













生产机器学习具有组织性问题。
该问题是伴随其出现的副产品,因为生产机器学习出现时间相对较短。
尽管更成熟的领域(如网络开发)经过数十年的探索已开发到极致,但生产机器学习还没有步入这一阶段。
举个例子,假如你的任务是为初创企业建立一个产品工程团队,来负责开发某个网络应用程序。即使没有组建团队的经验,你也能找到很多有关如何建立和发展工程团队的文章和书籍。
现在,假如你的公司是一家涉足机器学习的初创企业。你已经聘请了一位数据科学家来领导完成最初的工作,且成效显著。机器学习与公司产品的关系越来越紧密,数据科学家承担的责任越来越重大,很明显,机器学习团队需要发展。
这种情况下,没有那么多有关如何组建生产机器学习团队的文章和书籍供人参考。
这种情况十分普遍,机器学习公司的新责任(尤其是基础设施)交由数据科学家承担的情况时有发生。
这样是不对的。
机器学习和机器学习基础设施之间的区别
现在,平台工程师和产品工程师之间的区别已经很清楚了。同样,数据分析师和数据工程师之间也有着明显的不同。
很多公司的机器学习仍然缺少这样的专业知识。
要了解区分机器学习和机器学习基础设施为什么这么重要,这对于研究两者各自的工作内容和所需工具会很有帮助。
为了设计和训练新模型,数据科学家需要:
- 花时间在notebook上分析数据、进行实验。
- 考虑数据结构、为数据集选择正确的模型体系等问题。
- 使用Python、R、Swift或Julia之类的编程语言。
- 在PyTorch或TensorFlow等机器学习框架方面有自己的见解。
换句话说,数据科学家的职责、技能和工具将围绕操纵数据来开发模型,最终输出的将是能够提供最准确预测的模型。
机器学习基础设施与之截然不同。
将模型投入生产的普遍做法是将其作为微服务部署到云端。要将模型部署为生产应用程序界面,工程师需要:
- 同时关注分配文件、终端和云服务商的控制台,以优化稳定性、延迟和成本。
- 考虑自动伸缩实例、更新模型(前提是应用程序界面不崩溃)、在图形处理器上进行推理等问题。
- 使用Docker、Kubernetes、Istio、Flask等工具,以及云服务商提供的任何服务或应用程序界面。
下图展示了机器学习和机器学习基础设施之间的区别,十分形象,易于理解:
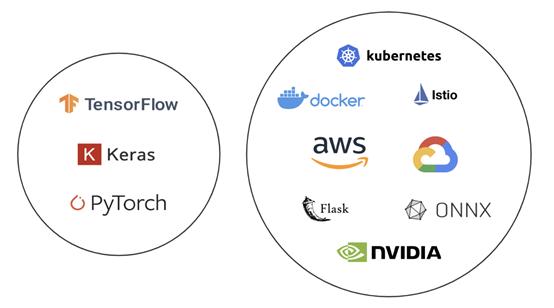
机器学习vs.机器学习基础设施
直观来看,数据科学家应该处理左边的圆圈,而不是右边的圆圈。
非专业人士管理基础设施有什么问题?
假如必须指定某个人来管理你的机器学习基础设施,但你又不想让他专职完成这项工作,那么只有两个选择:
- 数据科学家,因为他们熟悉机器学习。
- 开发运营工程师,因为他们熟悉通用基础设施。
这两个选择都有问题。
首先,数据科学家应该用尽可能多的时间做他们擅长的工作——数据科学。虽然学习基础设施对他们来说并不是难事,但基础设施和数据科学都是专职工作,将数据科学家的时间分配给这两项工作会降低工作质量。
其次,公司需要专门负责机器学习基础设施的人员。在生产过程中提供模型与托管网络应用程序不同,需要有人专门负责该项工作,能够在组织内部宣传机器学习基础设施。
事实证明,这样的宣传至关重要。笔者接触过很多机器学习公司,令人惊讶的是,公司内部成员的瓶颈通常不是来自技术方面的挑战,而是来自公司自身的挑战。
例如,笔者见过某些机器学习团队需要图形处理器 (GPUs)进行推理——GPT-2这样的大模型基本上需要图形处理器提供合理的延迟——却无法获得它们,因为这些团队的基础设施由更大的开发运营团队管理,而开发运营团队并不想把费用记在自己的账上。
有人专门负责机器学习基础设施,意味着该公司不仅拥有了能够不断改进基础设施的团队成员,还拥有了能够满足团队需要的宣传者。
那么谁来管理基础设施呢?
机器学习基础设施工程师。
这样一个头衔也许并不能让人认同,先把头衔的事放到一边,必须承认的是,生产机器学习仍然处于发展的早期阶段,更不用说头衔了。不同的公司可能会赋予其不同的称呼:
- 机器学习基础设施工程师
- 数据科学平台工程师
- 机器学习生产工程师
成熟的机器学习公司(比如Spotify)正在招聘这样的职位:
网飞公司也是如此:

随着支持机器学习的功能(比如Gmail的Smart Compose、优步的ETA预测和网飞公司的内容推荐)在软件中越来越普遍,机器学习基础设施也变得越来越重要。
如果人们希望未来存在大量支持机器学习的软件,那么消除基础设施瓶颈至关重要——为此,人们需要将其视为真正的专业知识,让数据科学家专注于数据科学工作。
别再让数据科学家管理Kubernetes集群了……


















