Redis为我们提供了5种数据类型,基本上我们使用频率最高的就是String,而对其他四种数据类型使用的频次稍弱于String。原因在于:
- String使用起来比较简单,可以方便存储复杂的对象,使用场景比较多;
- 由于Redis expire time只能设置在key上,像List、Hash、Set、Zset属于集合类型,会管理一组item,我们无法在这些集合的item上设置过期时间,所以使用expiretime来处理集合的cache失效会变得稍微复杂些。但是String使用expire time来管理过期策略会比较简单,因为它包含的项少。这里说的集合是宽泛的类似集合。
- 从更深层次来看,我们对另外四种数据类型的使用和原理并不是太了解。所以这个时候往往会忽视在特定场景下使用某种数据类型会比String性能高出很多的可能性,比如使用Hash结构来提高某实体某个项的修改等。
这里我们不打算罗列这5种数据类型的使用方法,因为这些资料网上有很多。我们主要讨论这5种数据类型的功能特点,弄清楚它们分别适合用于处理哪些现实的业务场景,我们又该如何组合性使用这5种数据类型,找到解决复杂cache问题的最优方案。
一、Redis的数据类型及特点
我们来简要了解一下String、List、Hash、Set及Zset:
1)String
String是Redis提供的字符串类型。可以针对String类型独立设置expire time,通常用来存储长字符串数据,比如某个对象的json字符串。
在使用上,String类型最巧妙的是可以动态拼接key。通常我们可以将一组id放在Set里,然后动态查找String还是否存在,如果不存在说明已经过期或者由于数据修改主动delete了,需要再做一次cache数据load。
虽然Set无法设置item的过期时间,但是我们可以将Set Item与String Key关联来达到相同的效果。
下图中的左边是一个key为Set:order:ids的Set集合,它可能是一个全量集合,也可能是某个查询条件获取出来的一个集合:
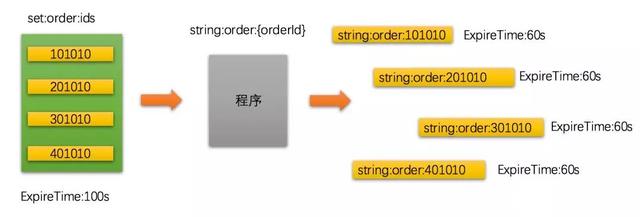
有时候复杂点的场景需要多个Set集合来支撑计算,在Redis服务器里可能会有很多类似这样的集合。这些集合我们可以称为功能数据,这些数据是用来辅助cache计算的,当进行各种集合运算之后会得出当前查询需要返回的子集,最后我们才会去获取某个订单真正的数据。
这些String:order:{orderId}字符串key并不一定是为了服务一种场景,而是整个系统最底层的数据,各种场景最后都需要获取这些数据。那些Set集合可以认为是查询条件数据,用来辅助查询条件的计算。
Redis为我们提供了TYPE命令来查看某个key的数据类型,如String类型:
- SET string:order:100 order-100
- TYPE string:order:100
- string
2)List
List在提高throughput的场景中非常适用,因为它特有的LPUSH、RPUSH、LPOP、RPOP功能可以无缝的支持生产者、消费者架构模式。
这非常适合实现类似Java Concurrency Fork/Join框架中的work-stealing算法(工作窃取)。
注:Java Fork/Join框架使用并行来提高性能,但是会带来由于并发take task带来的race condition(竞态条件)问题,所以采用work-stealing算法来解决由于竞争问题带来的性能损耗。
下图中模拟了一个典型的支付callback峰值场景:
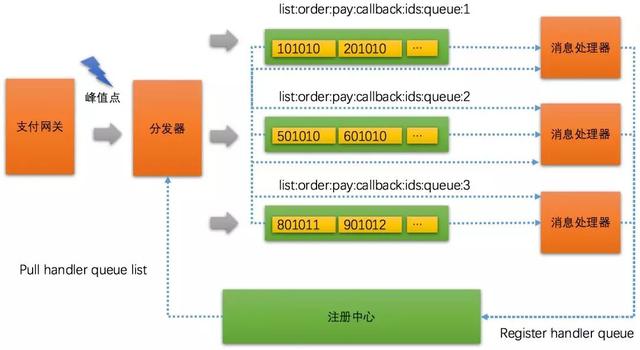
在峰值出现的地方一般我们都会使用加buffer的方式来加快请求处理速度,这样才能提高并发处理能力,提高through put。
支付gateway收到callback之后不做任何处理直接交给分发器。
分发器是一个无状态的cluster,每个node通过向注册中心pull handler queue list,也就是获取下游处理器注册到注册中心里的消息通道。每一个分发器node会维护一个本地queue list,然后顺序推送消息到这些queue list即可。
这里会有点小问题,就是支付gateway调用分发器的时候,是如何做load balance?如果不是平均负载可能会有某个queue list高出其他queue list。
而分发器不需要做soft load balance,因为哪怕某个queue list比其他queue list多也无所谓,因为下游message handler会根据work-stealing算法来窃取其他消费慢的queue list。
Redis List的LPUSH、RPUSH、LPOP、RPOP特性确实可以在很多场景下提高这种横向扩展计算能力。
3)Hash
Hash数据类型很明显是基于Hash算法的,对于项的查找时间复杂度是O(1)的,在极端情况下可能出现项Hash冲突问题,Redis内部是使用链表加key判断来解决的。具体Redis内部的数据结构我们在后面有介绍,这里就不展开了。
Hash数据类型的特点通常可以用来解决带有映射关系,同时又需要对某些项进行更新或者删除等操作。如果不是某个项需要维护,那么一般可以通过使用String来解决。
如果有需要对某个字段进行修改,使用String很明显会多出很多开销,需要读取出来反序列化成对象然后操作,然后再序列化写回Redis,这中间可能还有并发问题。
那我们可以使用Redis Hash提供的实体属性Hash存储特性,我们可以认为Hash Value是一个Hash Table,实体的每一个属性都是通过Hash得到属性的最终数据索引。
下图使用Hash数据类型来记录页面的a/bmetrics:
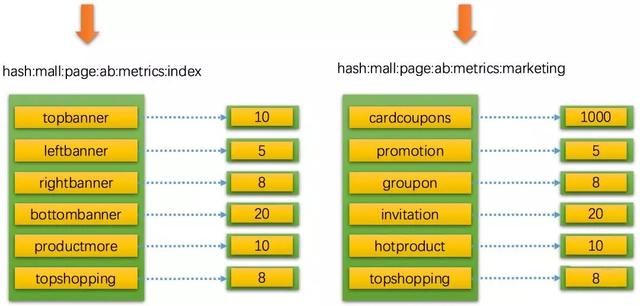
左边的是首页index的各个区域的统计,右边是营销marketing的各个区域统计。
在程序里我们可以很方便的使用Redis的atomic特性对Hash某个项进行累加操作。
- HMSET hash:mall:page:ab:metrics:index topbanner 10 leftbanner 5 rightbanner 8 bottombanner 20 productmore 10 topshopping 8
- OK
- HGETALL hash:mall:page:ab:metrics:index
- 1) "topbanner"
- 2) "10"
- 3) "leftbanner"
- 4) "5"
- 5) "rightbanner"
- 6) "8"
- 7) "bottombanner"
- 8) "20"
- 9) "productmore"
- 10) "10"
- 11) "topshopping"
- 12) "8"
- HINCRBY hash:mall:page:ab:metrics:index topbanner 1
- (integer) 11
使用Redis Hash Increment进行原子增加操作。HINCRBY命令可以原子增加任何给定的整数,也可以通过HINCRBYFLOAT来原子增加浮点类型数据。
4)Set
Set集合数据类型可以支持集合运算,不能存储重复数据。
Set最大的特点就是集合的计算能力,inter交集、union并集、diff差集,这些特点可以用来做高性能的交叉计算或者剔除数据。
Set集合在使用场景上还是比较多和自由的。举个简单的例子,在应用系统中比较常见的就是商品、活动类场景。用一个Set缓存有效商品集合,再用一个Set缓存活动商品集合。如果商品出现上下架操作只需要维护有效商品Set,每次获取活动商品的时候需要过滤下是否有下架商品,如果有就需要从活动商品中剔除。
当然,下架的时候可以直接删除缓存的活动商品,但是活动是从marketing系统中load出来的,就算我将cache里的活动商品删除,当下次再从marketing系统中load活动商品时候还是会有下架商品。
当然这只是举例,一个场景有不同的实现方法。
下图中左右两边是两个不同的集合:
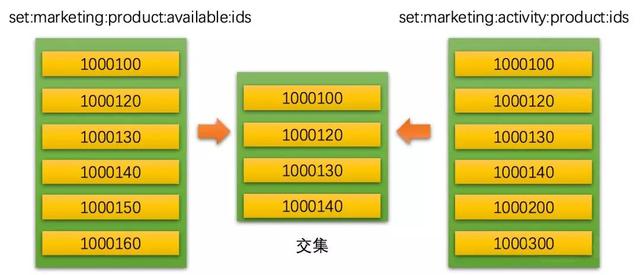
左边是营销域中的可用商品ids集合,右边是营销域中活动商品ids集合,中间计算出两个集合的交集。
- SADD set:marketing:product:available:ids 1000100 1000120 1000130 1000140 1000150 1000160
- SMEMBERS set:marketing:product:available:ids
- 1) "1000100"
- 2) "1000120"
- 3) "1000130"
- 4) "1000140"
- 5) "1000150"
- 6) "1000160"
- SADD set:marketing:activity:product:ids 1000100 1000120 1000130 1000140 1000200 1000300
- SMEMBERS set:marketing:activity:product:ids
- 1) "1000100"
- 2) "1000120"
- 3) "1000130"
- 4) "1000140"
- 5) "1000200"
- 6) "1000300"
- SINTER set:marketing:product:available:ids set:marketing:activity:product:ids
- 1) "1000100"
- 2) "1000120"
- 3) "1000130"
- 4) "1000140"
在一些复杂的场景中,也可以使用SINTERSTORE命令将交集计算后的结果存储在一个目标集合中。这在使用pipeline命令管道中特别有用,将SINTERSTORE命令包裹在pipeline命令串中可以重复使用计算出来的结果集。
由于Redis是Signle-Thread单线程模型,基于这个特性我们就可以使用Redis提供的pipeline管道来提交一连串带有逻辑的命令集合,这些命令在处理期间不会被其他客户端的命令干扰。
5)Zset
Zset排序集合与Set集合类似,但是Zset提供了排序的功能。在介绍Set集合的时候我们知道Set集合中的成员是无序的,Zset填补了集合可以排序的空隙。
Zset最强大的功能就是可以根据某个score比分值进行排序,这在很多业务场景中非常急需。比如,在促销活动里根据商品的销售数量来排序商品,在旅游景区里根据流入人数来排序热门景点等。基本上人们在做任何事情都需要根据某些条件进行排序。
其实Zset在我们应用系统中能用到地方到处都是,这里我们举一个简单的例子,在团购系统中我们通常需要根据参团人数来排序成团列表,大家都希望参加那些即将成团的团。
下图是一个根据团购code创建的Zset,score分值就是参团人数累加和:
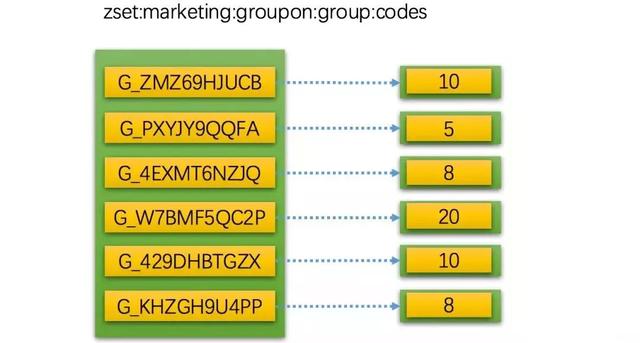
- ZADD zset:marketing:groupon:group:codes 5 G_PXYJY9QQFA 8 G_4EXMT6NZJQ 20 G_W7BMF5QC2P 10 G_429DHBTGZX 8 G_KHZGH9U4PP
- ZREVRANGEBYSCORE zset:marketing:groupon:group:codes 1000 0
- 1) "G_W7BMF5QC2P"
- 2) "G_ZMZ69HJUCB"
- 3) "G_429DHBTGZX"
- 4) "G_KHZGH9U4PP"
- 5) "G_4EXMT6NZJQ"
- 6) "G_PXYJY9QQFA"
- ZREVRANGEBYSCORE zset:marketing:groupon:group:codes 1000 0 withscores
- 1) "G_W7BMF5QC2P"
- 2) "20"
- 3) "G_ZMZ69HJUCB"
- 4) "10"
- 5) "G_429DHBTGZX"
- 6) "10"
- 7) "G_KHZGH9U4PP"
- 8) "8"
- 9) "G_4EXMT6NZJQ"
- 10) "8"
- 11) "G_PXYJY9QQFA"
- 12) "5"
Zset本身提供了很多方法用来进行集合的排序,如果需要score分值,可以使用withscore字句带出每一项的分值。
在一些比较特殊的场合可能需要组合排序,可能有多个Zset分别用来对同一个实体在不同维度的排序,按时间排序、按人数排序等。这个时候就可以组合使用Zset带来的便捷性,利用pipeline再结合多个Zset最终得出组合排序集合。
二、案例:沪江团购系统大促hot-top接口cache设计
以沪江团购系统大促hot-top接口cache设计为例,我们总结了Redis提供的5种数据类型的各自特点和一般的使用场景。但是我们不仅仅可以分开使用这些数据类型,我们完全可以综合使用这些数据类型来完成复杂的cache场景。
下面我们分享一个使用多个Zset、String来优化团购系统前台接口的例子。由于篇幅和时间限制,这里只介绍跟本次案例相关的信息。
注:hot-top接口是指热点、排名接口的意思,表示它的浏览量、并发量比较高,一般大促的时候都会有几个这种性能要求比较高的接口。
我们先来分析一个查询接口所包含的常规信息。
首先一个查询接口肯定是有query condition查询条件,然后是sort排序信息、最后是page分页信息。这是一般接口所承担的基本职责,当然,特殊场景下还需要支持master/slave replication时关于数据session一致性的要求,需要提供跟踪标记来回master查询数据,这里就不展开了。
我们可以抽象出这几个维度的信息:
- querycondition:查询条件,companyid =100,sellerid=1010101诸如此类。
- sort:排序信息,一般是默认一个列排序,但是在复杂的场景下会有可能让接口使用者定制排序字段,比如一些租户信息列。
- page:分页信息,简单理解就是数据记录排完序之后的第几行到第几行。
由于这里我们纯粹用Redis来提高cache能力,不涉及到有关于任何搜索的能力,所以这里忽略其他复杂查询的情况。其实我们在复杂的地方使用了Elastcsearch来提高搜索能力。
上述我们分析总结出了一个查询接口的基本信息,这里还有一个有关于高并发接口的设计原则,就是将hot-top接口和一般search接口分离开,因为只有分而治之才能分别根据特点选用不同的技术。
如果我们不分职责将所有的查询场景封装在一个接口里,那么在后面优化接口性能的时候基本就很麻烦了,有些场景是无法或者很难用cache来解决的,因为接口里耦合了各种场景逻辑,就算勉强能实现性能也不会高。
前面做这些铺垫是为了能在介绍案例的时候达成一个基本的共识。现在我们来看下这个团购系统的hot-top接口的具体逻辑。
注:在大促的时候需要展现团购列表,这个接口的访问量是非常大的,团购活动需要根据参团人数倒序排序,并且分页返回指定数量的团列表。我们假设这个接口名为getTopGroups(getTopGroupsRequestrequest)。
1)query condition查询条件问题
我们来仔细分析下,首先不同的查询条件从DB里查询出来的数据是不一样的,也就是说查询出来的团列表是不一样的,可能有company公司、channel渠道等过滤条件。
由于一个团购活动下不会有太多团,顶多上百个是极限了,所以一个查询条件出来的团列表也顶多几十个,而且根据场景分析热点查询条件不会超过十个,所以我们选择将查询条件Hash出一个code来缓存本次查询条件的全量团列表集合,但是这些结果集是没有任何排序的。
2)sort排序问题
再看根据参团人数排序问题,我们立刻就可以想到使用Zset来处理团排序问题,因为只有一个排序维度,所以一个Zset就够了。我们使用一个Zset来缓存所有团的参团人数集合,它是一个全量的团排序集合。
那么我们如何将用户的查询条件出来的团列表根据参团人数排序呢?刚好可以使用Zset的交集运算,直接计算出当前这个集合的Zset子集。
3)page分页问题
通过对已经排序之后的团列表Zset使用Zrange来获取出分页集合。我们来看下完整的流程,如何处理查询、排序、分页的。
下图从query condition计算Hash Code,然后通过DB查询出当前条件全量团列表:
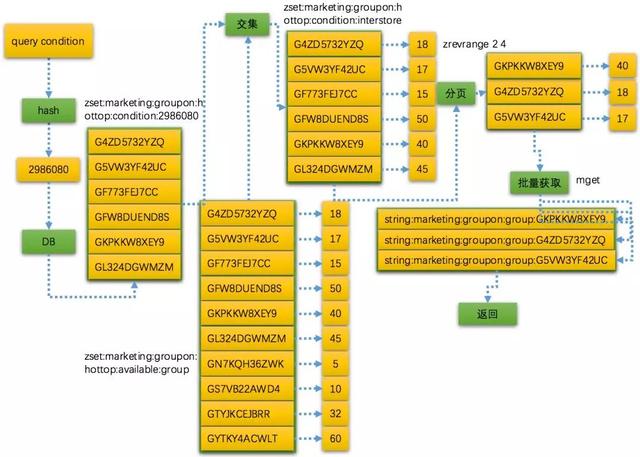
zset:marketing:groupon:hottop:available:groupkey表示全量团的参团人数,用一个Zset来缓存。接着将这两个Zset计算交集,就可以得出当前查询所需要的带有参团人数的Zset,最后在使用Zrevrange获取分页区间。
- ZADD zset:marketing:groupon:hottop:condition:2986080 0 G4ZD5732YZQ 0 G5VW3YF42UC 0 GF773FEJ7CC 0 GFW8DUEND8S 0 GKPKKW8XEY9 0 GL324DGWMZM
- (integer) 6
- ZADD zset:marketing:groupon:hottop:available:group 5 GN7KQH36ZWK 10 GS7VB22AWD4 15 GF773FEJ7CC 17 G5VW3YF42UC 18 G4ZD5732YZQ 32 GTYJKCEJBRR 40 GKPKKW8XEY9 45 GL324DGWMZM 50 GFW8DUEND8S 60 GYTKY4ACWLT
- (integer) 10
- ZINTERSTORE zset:marketing:groupon:hottop:condition:interstore 2 zset:marketing:groupon:hottop:condition:2986080 zset:marketing:groupon:hottop:available:group
- (integer) 6
- ZRANGE zset:marketing:groupon:hottop:condition:interstore 0 -1 withscores
- 1) "GF773FEJ7CC"
- 2) "15"
- 3) "G5VW3YF42UC"
- 4) "17"
- 5) "G4ZD5732YZQ"
- 6) "18"
- 7) "GKPKKW8XEY9"
- 8) "40"
- 9) "GL324DGWMZM"
- 10) "45"
- 11) "GFW8DUEND8S"
- 12) "50"
- ZREVRANGE zset:marketing:groupon:hottop:condition:interstore 2 4 withscores
- 1) "GKPKKW8XEY9"
- 2) "40"
- 3) "G4ZD5732YZQ"
- 4) "18"
- 5) "G5VW3YF42UC"
- 6) "17"
有了返回的团code集合之后就可以通过mget来批量获取String类型的团详情信息,这里就不贴出代码了。
由于篇幅和时间关系,我们不展开太多的业务场景介绍了。这其中还涉及到计算cache过期时间的问题,这也跟促销活动的运营规则有关系,还涉及到有可能query condition hash冲突问题等,但是这些已经不与我们本节主题相关。