功能完全失灵,以往看一眼就能解锁、支付的人工智能,现在宛如“废柴”。
这不,网友们纷纷吐槽:



更有网友建议各大手机厂商开发新功能:

最初我们知道AI人脸识别技术,是作为一种重要的个人身份鉴别方法,用于罪犯照片管理和刑侦破案,现在这种技术在安全系统和商贸系统中都有很多的应用。
如今,我们每时每刻依赖着这项功能。
早上起床对准手机看一下便自动解锁;
网上购物“刷脸”支付;
外出购物不需要带现金、在机器面前“刷脸”支付即可,上班“刷脸”打卡;
搭乘高铁、飞机实行无纸质的“刷脸”安检通道......
这项逐渐融入日常生活各个领域的技术,给我们的生活带来了天翻地覆的便利。接下来让我带着大家简单学习这项技术~
01.AI人脸识别
人脸识别是计算机视觉和模式识别的交叉领域,又将两者结合在一起。
20 世纪 80 年代后期在人脸识别中引入了神经生理学、脑神经学、视觉知识等,结合计算机技术的迅猛发展以及计算成本的迅速下降使得以前比较费时费空间的一些模式匹配算法,如大样本的引入、多维特征参 数的提取、建模等。
人脸识别这一领域的研究除了具有重大理论价值外,也极具实用价值,是基于人的脸部特征信息进行身份识别的一种生物识别技术。
02.识别领域
人脸检测
是指检测并定位图片中的人脸,返回高精度的人脸框坐标,是对人脸进行分析和处理的第一步。
早期的检测过程称为“滑动窗口”,也就是选择图像中的某个矩形区域作为滑动窗口,在这个窗口中提取一些特征对这个图像区域进行描述,最后根据这些特征描述来判断这个窗口是不是人脸(如下图所示)。
人脸检测的过程就是不断遍历需要观察的窗口

人脸关键点检测
是指定位并返回人脸五官与轮廓的关键点坐标位置(如下图所示)。
关键点包括人脸、轮廓、眼睛、眉毛、嘴唇以及鼻子轮廓。
现在某些人脸识别公司,如 Face++能提供高精度的关键点,最多可达 106 点。
无论是静态图片还是动态视频流,均能完美贴合人脸。

人脸关键点定位技术
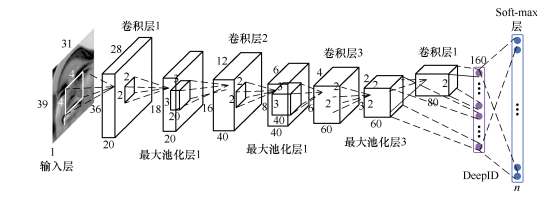
关键点定位技术主要有级联形回归(cascaded shape regression,CSR),目前人脸识别一般是基于 DeepID 网络结构。
DeepID 网络结构和卷积神经网络结构类似,主要区别在倒数第二层,DeepID 网络结 构有一个 DeepID 层,它与卷积层4和最大池化层3相连,由于卷积神经网络层数越高视野域越大,这种连接方式可以既考虑局部的特征,又考虑全局的特征(下图所示)。
人脸验证
是指分析两张人脸属于同一个人的可能性大小。
输入两张人脸,得到一个置信度分数和相应的阈值,以便评估相似度。
下图是调用 Face++的人脸验证在线接口得到的结果。对比结果为:是同一个人的可能性很高。

人脸属性检测
分为人脸属性辨识和人脸情绪分析。
例如,给出人的年龄、是否有胡子、情绪(高兴、正常、生气、愤怒)、性别、是否带眼镜、肤色等来进行人脸属性辨识和人脸情绪分析。
下图给出的一张照片的测试结果因为化妆和灯光的原因,结果并不是很准确。

02.数据预处理
在图像识别中,数据预处理是很重要的一步。
这里使用 facenet 源代码下的 align 模块去校准。我们需要将检测所使 用的数据集校准为和预训练模型所使用的数据集大小一致。
为了能正确运行校准程序,需要设置一下环境变量:
- export PYTHONPATH=$YOURHOME/facenet/src
校准命令如下:
- for N in {1..4}; do python src/align/align_dataset_mtcnn.py $YOURHOME/facenet /datasets/lfw/raw $YOURHOME/facenet/datasets/lfw/lfw_mtcnnpy_160 --image_size 160 --margin 32 --random_order --gpu_memory_fraction 0.25 done
这里采用 GitHub 上提供的预训练模型 20170216-091149.zip,采用的训练集是 MS-Celeb-1M 数据集。
MS-Celeb-1M 是微软的一个非常大的人脸识别数据库,它是从名人榜上选择前 100 万的名人,然后通过 搜索引擎采集每个名人大约 100 张人脸图片而形成的。这个预训练模型的准确率已经达到 0.993±0.004。
我们将下载后的模型解压到:
- $YOURHOME/facenet/models/facenet/20170216-091149
里面包含的文件如下:
- model-20170216-091149.ckpt-250000.data-00000-of-00001
- model-20170216-091149.ckpt-250000.index
- model-20170216-091149.met 10.4.3
03.进行检测
运行
进入 facenet 目录,用如下命令运行脚本:
- python src/validate_on_lfw.py datasets/lfw/lfw_mtcnnpy_160 models
得到的结果如下:
- Model directory: /media/data/DeepLearning/models/facenet/20170216-091149/ Metagraph file: model-20170216-091149.meta
- Checkpoint file: model-20170216-091149.ckpt-250000
- Runnning forward pass on LFW images
- Accuracy: 0.993+-0.004
- Validation rate: 0.97533+-0.01352 @ FAR=0.00100
- Area Under Curve (AUC): 0.999
- Equal Error Rate (EER): 0.008
比较
为了和基准进行比较,这里采用 facenet/data/pairs.txt 文件,它是官方随机生成的数据,里面包含匹配和不 匹配的人名和图片编号。
匹配的人名和图片编号示例如下:
- Abel_Pacheco 1 4
表示 Abel_Pacheco 的第 1 张和第 4 张是一个人。
不匹配的人名和图片编号示例如下:
- Abdel_Madi_Shabneh 1 Dean_Barker 1
表示 Abdel_Madi_Shabneh 的第 1 张和 Dean_Barker 的第 1 张不是一个人。
检测
下面我们看一下 validate_on_lfw.py 是如何检测人脸的。可以分为 4 步,具体如下:
- def main(args):
- with tf.Graph().as_default():
- with tf.Session() as sess:
1. 读入之前的 pairs.txt 文件
读入后如
- [['Abel_Pacheco', '1', '4']
- ['Akhmed_Zakayev', '1', '3'] ['Slobodan_Milosevic', '2', 'Sok_An', '1']] pairs = lfw.read_pairs(os.path.expanduser(args.lfw_pairs))
获取文件路径和是否匹配的关系对
- paths, actual_issame = lfw.get_paths(os.path.expanduser(args.lfw_dir),
- pairs, args.lfw_file_ext)
2. 加载模型
- print('Model directory: %s' % args.model_dir)
- meta_file, ckpt_file = facenet.get_model_filenames(os.path.expanduser
- (args.model_dir))
- print('Metagraph file: %s' % meta_file)
- print('Checkpoint file: %s' % ckpt_file)
- facenet.load_model(args.model_dir, meta_file, ckpt_file)
3. 获取输入、输出的张量
- images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
- embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
- phase_train_placeholder = tf.get_default_graph().get_tensor_by_name
- ("phase_train:0")
- image_size = images_placeholder.get_shape()
- embedding_size = embeddings.get_shape()
4. 使用前向传播来验证
- print('Runnning forward pass on LFW images')
- batch_size = args.lfw_batch_size
- nrof_images = len(paths)
- nrof_batches = int(math.ceil(1.0*nrof_images / batch_size))
- 总共的批次数 emb_array = np.zeros((nrof_images, embedding_size))
- for i in range(nrof_batches):
- start_index = i*batch_size
- end_index = min((i+1)*batch_size, nrof_images)
- pathspaths_batch = paths[start_index:end_index]
- images = facenet.load_data(paths_batch, False, False, image_size)
- feed_dict = { images_placeholder:images, phase_train_placeholder:False }
- emb_array[start_index:end_index,:] = sess.run(embeddings,
- feed_ dict=feed_dict)
5. 计算
这里计算准确率和验证率,使用了十折交叉验证的方法
- tpr, fpr, accuracy, val, val_std, far = lfw.evaluate(emb_array,
- actual_issame, nrof_folds=args.lfw_nrof_folds)
- print('Accuracy: %1.3f+-%1.3f' % (np.mean(accuracy), np.std(accuracy)))
- print('Validation rate: %2.5f+-%2.5f @ FAR=%2.5f' % (val, val_std, far))
- 得到 auc 值 auc = metrics.auc(fpr, tpr)
- print('Area Under Curve (AUC): %1.3f' % auc)
- 得到等错误率(eer)
- eer = brentq(lambda x: 1. - x - interpolate.interp1d(fpr, tpr)(x), 0., 1.)
- print('Equal Error Rate (EER): %1.3f' % eer)
这里采用十折交叉验证(10-fold cross validation)的方法来测试算法的准确性。十折交叉验证是常用的 精度测试方法,具体策略是:将数据集分成 10 份,轮流将其中 9 份做训练集,1 份做测试集,10 次的结 果的均值作为对算法精度的估计,一般还需要进行多次 10 折交叉验证求均值,例如,10 次 10 折交叉验 证,再求其均值,作为对算法准确性的估计。
04.AI人脸识别技术在进步
当下,正确佩戴口罩外出是必要的防护措施。
但由于口罩具备不透光性,使得摄像头拍摄到的画面无法捕捉到嘴巴、鼻子等脸部特征。
而人脸识别模型都要使用完整的面部特征,所以戴着口罩会造成AI人脸识别失败,使用人工检查的手段又效率太低。
幸好各大科创巨头纷纷投身研究,如何让AI人脸识别比以前更智能化。
口罩识别模型
是百度工程师开发的AI口罩督查官。
可以在公共场所使用场景中,无接触、快速精准地识别出实时画面中未戴口罩或者佩戴不正确的人。
戴口罩人脸身份识别模型
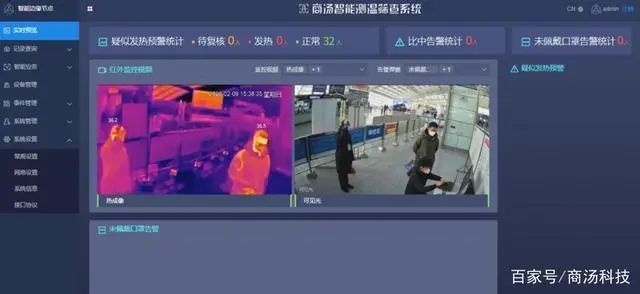
商汤科技推出了AI智慧防疫解决方案。
宣称其区域通行模块可以识别出戴口罩人脸的身份,在人员戴口罩的情况下,只要露出50%鼻梁,通过率可达85%。
动态人脸识别
汉王科技最新推出了亮银钻石款动态人脸识别机。
其在戴口罩人员的识别率也达到85%。
当前该套系统在北京地区用户已达20余家,应用设备近200套。
阿里、和华为识别率更高的模型也正在研发当中......
之前,我们单纯依赖全脸信息特征来识别身份,今后,我们可以做到半脸、甚至是眼部即可让AI人脸识别系统准确识别出我们每一个人,科技在我们的大力发展下帮助我们对抗各种生活中出现的难题。
还想了解更多AI人脸识别技术吗?这本《TensorFlow技术解析与实战》推荐给大家。

TensorFlow是谷歌公司开发的深度学习框架,也是目前深度学习的主流框架之一。本书从深度学习的基础讲起,深入TensorFlow框架原理、安装、模型、源代码和统计分析等各个方面。全书分为基础篇、实战篇和提高篇三部分。最后附录中列出一些可供参考的公开数据集,并结合作者的项目经验介绍项目管理的一些建议。