时下不论是在全文搜索领域还是大数据即时处理领域ELK都一枝独秀,而ELK的核心在于Elasticsearch,ELK很秀源于Elasticsearch很棒。很多可能用过ELK但是对其核心Elasticsearch却知之甚少,本文我们就一起来学习Elasticsearch,从基本概念到生产使用一文全搞定。
基础概念
对于一个Elasticsearch(ES)的新手,首先需要学习一些基本概念。
Elasticsearch项目源于Java的优秀的分布式搜索引擎Apache Lucene,Luncene还派生了另一个非常优秀的搜索项目Solor。不管是是Elasticsearch和Solor其底层保存数据和搜索引擎部分都是Lucene。ES在基于Lucene内核上更加优秀的一个分布式实时搜索引擎,尤其在分布式集群和横向扩展方面做的非常好,可以很轻松地运行管理数千个Lucene实例。
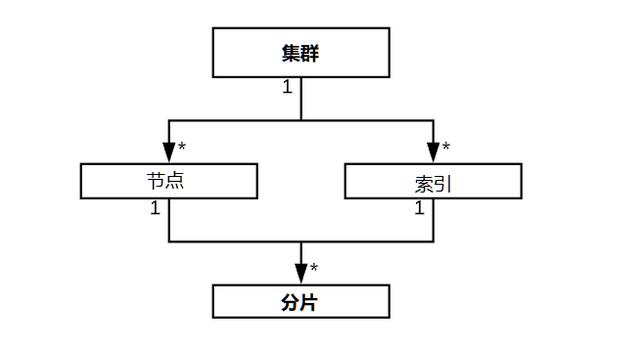
在ES架构中的最高级别单元是群集(Cluster)。集群是ES节点和索引的集合。
节点(Node)是ES的实例。它们可以是单个服务器,也可以仅仅为服务器上运行的ES进程。注意:服务器并等价于节点不相同。VM虚拟机或物理服务器都可以容纳许多ES进程,每个ES进程都是一个节点。节点可以完全加入一个集群。有不同类型的节点。其中最有重要两个节点是数据节点(Data Node)和备选主节点(Master-Eligible Node)。一个节点可以同时具备多种属性。数据节点运行所有数据操作。即存储,索引和搜索数据。备选主节点用来投票为运行集群和索引管理的主机。
索引(Index)是数据的高级抽象。索引本身不保存数据。它们只是对实际存储数据的另一种抽象。对数据执行的任何操作(例如插入,删除,建立索引和搜索)都会对索引产生影响。索引可以完全属于一个簇,并且由分片组成。
分片(Shard)是Apache Lucene的实例。一个分片可以容纳许多文档。分片是实际数据存储,索引和搜索的对象。一个分片恰好属于一个节点和索引。分片分两种类型:主(primary)分片和副本(replica)。两者基本上是等同的,它们拥有相同的数据,并且并行搜索所有分片。在拥有相同数据的所有分片中,一个是主分片,是唯一可以接受索引请求的分片。如果主分片所在的节点死亡,则副本分片将自动接管成为主分片。然后,ES将创建一个新的副本分片并复制数据。总体上可以用一个简单的图示如下:
深入了解
如果想运行一个系统,首先需要了解该系统。在了解基础概念后,我们来实际了解Elasticsearch的各个部分。
Quorum
理解Elasticsearch组织是一个民主机制很重要。节点通过投票决定谁是老大Master,即主节点。该主节点主运行很多集群管理进程,在集群中享有最终决定权。ES的 选举是有条件的,既只有备选节点才能参与选举成为主节点。符合Master资格的是其配置中设置为下面条件的所有节点:
node.master: true
在群集启动时或主节点退出群集时,所有符合主节点条件的节点都会开始选举新的主节点。因此,需要具有2n + 1个符合主机要求的节点。否则,可能会出现选举55开的裂脑情况。
节点加入
当ES流程启动时,它就独立自由存在,他如何知道自己所处的集群呢?有不同的方法可以完成此操作。但常用一种叫做种子主机(Seed Hosts)的方法来这个过程。
Elasticsearch节点会不断地和他所见过的所有其他节点进行对话。因此,一个节点最初只需资询几个其他节点即可了解整个集群。整个过程不是一个恒定的过程:节点不属于集群时,它们仅共享有关他们发现的其他节点的信息。一旦加入群集,节点便会停止该操作,并依靠当选群集主节点共享所发生的变化信息。这样可以节省了大量不必要的网络闲聊。在ES 7.x中,节点间只交流他们所见到到备选主机节点,发现过程会忽略备选主机节点。
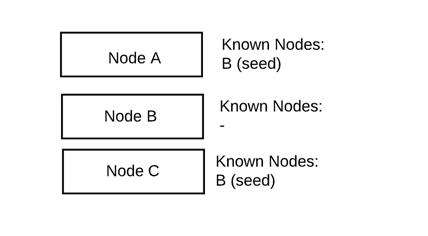
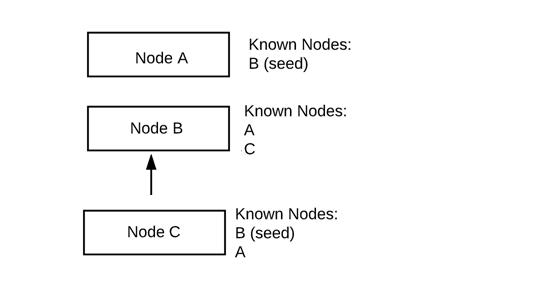
以一个三节点集群的为例:
初始状态:
节点A和C只是知道B。B是种子主机。种子主机要么以配置文件的形式提供给ES,要么直接放入elasticsearch.yml中。
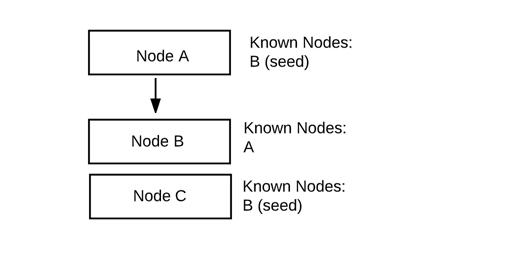
节点A与B连接并交换信息:
一旦节点A连接到B,B现在就知道了A的存在。A没有任何变化。
节点C连接并与B共享信息
现在C连线,C会和B通讯。B就会告诉C A的存在。C和B现在都知道群集中的所有节点。下一次A重新连接到B,它也会知道C的存在。
段合并
前面我们说过,分片存储数据。数据将以..文件的形式存储在文件系统中。在Lucene和Elasticsearch中,这些文件被称为段(Segments)。一个分片会有一到数千个段。
段是物理上实际存在的文件,可以在ES安装的data目录中看到。所以端文件的操作是个开销。如果要查看,必须要找到对应的文件并打开。如果要打开许多文件,那么将会带来很大的开销。由于Lucene中的段是不可变的,只能写入不可更改。放入ES中的每个文档都将创建一个仅包含单个文档的段。那么,如果集群中有十亿个文档则对应会有十亿个段文件么?
实际上不是这样的。在Lucene后台,会进行段合并。该操作不对段进行更改,但是可以两个较小段的数据合并创建新的段,并将合并的两个小段清理掉:
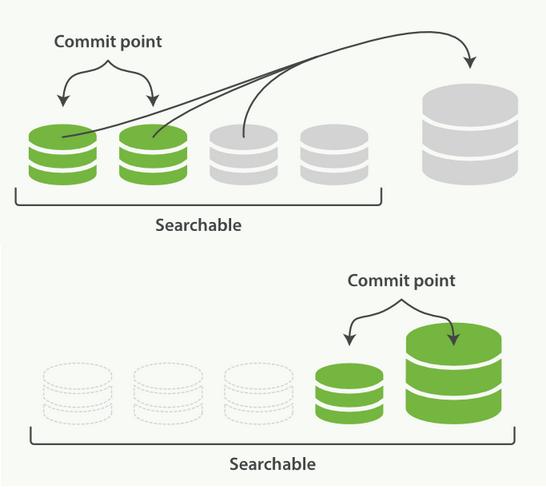
lucene会不断段合并,并 保持段数量不会太大。
消息路由
在Elasticsearch中,可以对集群中的任何节点运行任何命令,并且保持结果将相同。然而,在最底层文档将只存在于一个主分片及其副本中,而ES该文档位于何处,也没有映射说明特定文档位于特定分片中。
如果进行搜索,请求入口点ES节点会将其广播到索引中的所有分片,这些分片来查看该文档的所有段。如果要插入,则ES节点会随机选择一个主分片并将文档放在其中,然后将其写入该主要分片及其所有副本。
生产实践
最后部分来说说在生产中如何部署和管理Elasticsearc。
Elasticsearch实践中最常见的一个问题是,估计需要的集群规模,包括节点数量,需要硬件资源等。
内存
首先要考虑内存使用,内存大小将限制所有其他资源。
Java堆
ES是用Java开发的。Java要用堆,可以将其视为Java保留的内存。关于堆,有所有重要的东西会使这个文档的大小增加三倍。
关于尽量可能多的使用,但堆大小不要超过30G。
有一个这很多人都不知道的关于堆的秘密:堆中的每个对象都需要一个唯一的地址,即一个对象指针。该地址的长度是固定的,所以可以寻址的对象数量是有限的。简而言之,在某一时刻,Java会需要使用压缩的对象指针而不是未压缩的对象指针。这样每个内存访问都将涉及其他步骤,并且速度会慢得多。请不要超过此阈值(大约32G)。
根据社区对Elasticsearch的不同文件系统,堆大小,FS和BIOS的组合的基准测试,结果如下:
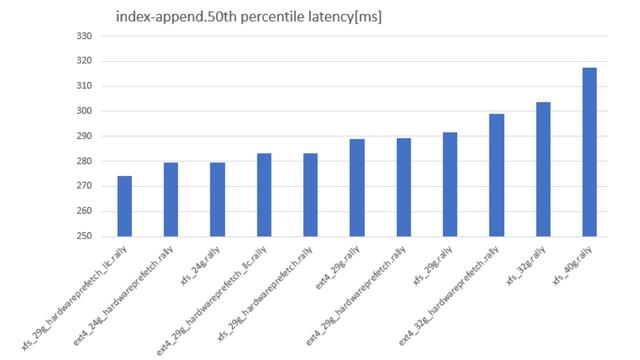
如上图所示,从32G的堆大小开始,性能突然开始变差(50%访问延时,越小越好)。
吞吐量结果(越大越好)也类似:
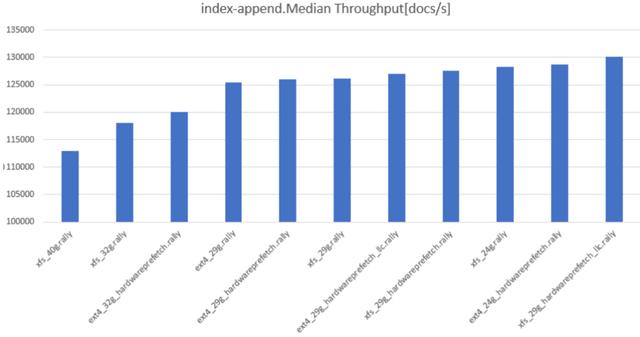
总之,请使用29G或30G的内存,请使用XFS,并尽可能使用hardwareprefetch和llc-prefetch。
文件缓存
绝大大多数人会在Linux上运行Elasticsearch,Linux使用RAM作为文件系统缓存。常见的建议是将64G用于ES服务器,这样一半的缓存,一半的堆。大型ES群集(如用于日志记录)可以从拥有大容量的FS缓存中获益。如果所有的索引都适合堆,则不需要那么多。
Elasticsearch 7.x会在其堆上需要一定数量的直接内存,并且还有其他开销,这就是为什么建议堆大小不超过物理内存的50%的原因。这是一个上限,64GB主机上的32GB堆可能不能为文件系统缓存保留太多空间。文件系统缓存是Elasticsearch/Lucene性能的关键,并且较小的堆有时可以产生更好的性能(它们为文件系统缓存留出更多空间,并且对于GC而言也更便宜)。
CPU
这取决于对群集执行的操作。如果要进行大量索引编制,则与仅执行日志记录相比,需要更多,更快的CPU。对于日志记录,一般来说8核CPU就绰绰有余,但是更具不同用途,要具体实践而定。
磁盘
如果索引分配到合适的内存,则磁盘仅在节点冷时才重要。而且实际可以存储的数据量取决于索引布局。每个分片都是Lucene实例,它们都有内存需求。这样可以在堆中容纳最大数量的分片。通常,可以将所有数据磁盘放入RAID0。应该在Elasticsearch级别进行复制,因此丢失节点无关紧要。不要请将LVM和多个磁盘一起使用,因为LVM一次只能写入一个磁盘,根本就不会给带来多个磁盘的好处。
关于文件系统和RAID设置:
调度器:cfq和截止日期优于noop。如果有nvme,Kyber可能会很好(未严格测试过)
QueueDepth:尽可能高
预读:是的,请使用
Raid块大小:无影响
FS块大小:无影响
FS类型:XFS优于ext4
索引布局
大程度上取决于的用例。从日志集群背景为例来说。
分片
简而言之:
对于写繁重的工作负载,主分片=节点数
于读繁重的工作负载,主分片*复制=节点数
更多副本=更高的搜索性能
可以通过一个公式来计算写入性能:
节点吞吐量*主分片数
原因很简单:如果只有一个主分片,那么只能像一个节点可以写入数据那样快地写入数据,因为一个分片只能位于一个节点上。如果确实想优化写入性能,则应确保每个节点上只有一个分片(主节点或副本),因为副本显然获得与主节点相同的写入,并且写入很大程度上取决于磁盘IO。
注意:如果有很多索引,则可能不正确,而瓶颈可能是其他原因。
如果要优化搜索性能,可以通过以下公式给出搜索性能:
节点吞吐量*(主分片数+副本数)
对于搜索,主碎片和副本分片基本上是等同的。因此,如果想提高搜索性能,只需增加副本数即可。
规模大小
关于索引大小有很懂资料。我们在此一个经验是:
30G堆=每个节点最多140个分片
使用多余140分片,可能会使Elasticsearch进程崩溃并出现内存不足错误。因为每个分片都是Lucene实例,并且每个实例都需要一定数量的内存。所以,每个节点可以有多少个分片。
如果有节点数量,分片数量和索引大小,则可以容纳多少个索引:
分片数量=(140*节点数)/(主分片数*副本率)
这样就可以计算出,所需要的大小:
索引大小=(节点数 * 硬盘大小)/索引数量
请注:较大的索引也相对较慢。对于日志记录来说,一定程度是可以的,但是对于真正搜索繁重的应用程序,应该根据所拥有的内存数量来增加大小。
段合并
请记住,每个段都是文件系统上的实际文件。基本上,对于每个搜索查询,都会转到索引中的所有分片,再从那里到分片中的所有段。段文件太多会极大地增加群集的读取IOPS,直至无法使用。因此,最好将段数保持在尽可能低的水平。
有一个force_merge API,允许将段合并到一定数量,例如1。如果进行索引轮换,例如,因为使用Elasticsearch进行日志记录,则在不使用群集时进行常规使用中的强制合并是一个好主意。
强制合并会占用大量资源,并且会大大降低群集的速度,如果有很多索引,则必须要强制合并。
集群布局
对于除最小设置以外的所有内容,最好使用专用的符合主机资格的节点。保持具有2n + 1个备选节点以确保仲裁。但是对于数据节点,只希望能够随时添加一个新节点,而不必担心。另外,也不希望数据节点上的高负载影响的主节点。
最后,主节点是种子节点的理想候选者。
记住,种子节点是在Elasticsearch中执行节点发现的最简单方法。由于的主节点很少会会更改,因此,它们是最佳选择,他们已经知道了集群中的所有其他节点。
主节点可能很小,一个核心甚至4G的内存就可以满足大多数群集的需求。与往常一样,关注实际使用情况并进行相应调整。
监控
监控是个好东西,对Elasticsearch也是如此。ES为提供了大量的指标,并且支持以JSON的形式为方便调用,在监控工具中添加这些指标非常简单。以下是一些有用的监控指标包括:
段数,堆使用率,堆GC时间,搜索、索引、合并的平均用时,IOPS,磁盘利用率等
总结
本文,我们由简到深入再到实践实战,介绍了Elasticsearch使用的全部信息。主要是分享干货 ,没有其他枝枝节节的描写和内容,希望对大家有所帮助。