【51CTO.com快译】分布式应用不是新鲜事。随着ARPANET等计算机网络的出现,第一批分布式应用系统在50年前就开发出来了。从那时起,开发人员利用分布式系统来扩展应用和服务,包括大规模模拟、Web服务和大数据处理。我在这20多年的职业生涯中开发过分布式系统,涉及互联网、对等网络、大数据和现在的机器学习等领域。
然而就在不久前,分布式应用还是例外,而不是常态。即使在今天,大多数学校的本科生也很少搞涉及分布式应用的项目(即便有的话),不过这种情况在迅速改变。
分布式应用很快将成为常态,而不是例外
推动这一转变的两大潮流是:摩尔定律终结和新的机器学习应用对计算需求激增。这些潮流导致应用需求和单节点性能之间的差距迅速拉大,这使得我们除了分发这些应用外别无选择。
摩尔定律已死
过去40年来推动计算机行业空前发展的摩尔定律已走到头。根据摩尔定律,处理器的性能每18个月翻番。而今天,它在同一时期仅以10%至20%的速度增长。
虽然摩尔定律可能已死,但对增加计算资源的需求并未停止。为了应对这一挑战,计算机架构师将注意力集中到制造以通用性换性能的针对特定领域的处理器上。
光有针对特定领域的硬件不够
针对特定领域的处理器以牺牲通用性为代价,对特定工作负载进行了优化。这类工作负载的典例是深度学习,深度学习彻底改变了几乎每个应用领域,包括金融服务、工业控制、医疗诊断、制造和系统优化等。

为了支持深度学习工作负载,许多公司竞相制造专用处理器,比如英伟达的GPU和谷歌的TPU。然而,虽然GPU和TPU等加速器带来了更强的计算能力,但它们实质上有助于延长摩尔定律的寿命,而不是从根本上提高改进的速度。
深度学习应用需求的三重打击
机器学习应用的需求正以惊人的速度增长。下面是三种典型的重要工作负载。
1. 训练
据OpenAI的一篇著名博文(https://openai.com/blog/ai-and-compute)介绍,自2012年以来,获得最先进的机器学习结果所需的计算量大约每3.4个月翻番。这相当于每18个月增加近40倍,比摩尔定律还要多20倍!因此,即使摩尔定律还没有终结,它仍远远满足不了这些应用的要求。
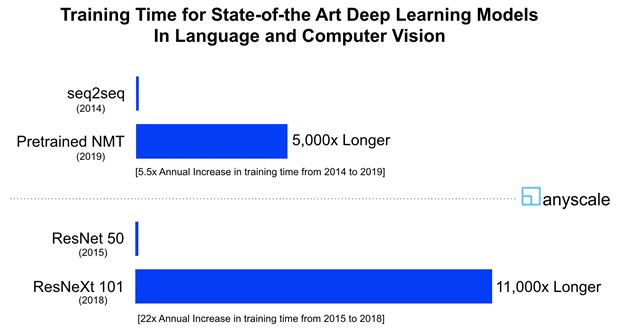
这种爆炸性的增长并非仅限于深奥的机器学习应用,比如AlphaGo。类似的趋势也适用于主流应用领域,比如计算机视觉和自然语言处理。不妨考虑两个最先进的神经机器翻译(NMT)模型:2014年的seq2seq模型和2019年针对数百亿个句子对的预训练方法。两者所需的计算资源之比超过5000倍。这相当于每年增加5.5倍。同样不妨考虑ResNet 50与ResNeXt 101 Instagram模型,这两个最先进的对象识别模型分别于2015年和2018年发布。两者的训练时间之比达到惊人的11000倍(ResNet 50使用16个英伟达V100 GPU用时58分钟,ResNetXt 101使用336个GPU用时22天)。这相当于每年增加22倍!这使摩尔定律相形见绌,摩尔定律每年增长仅1.6倍。
这些需求与专用处理器的功能之间的差距日益拉大,系统架构师除了分发这些计算别无选择。最近,谷歌发布了TPU v2和v3 pod,含有多达1000个通过高速网状网络连接的TPU。值得关注的是,虽然TPU v3 pod的功能是TPU v2 pod的8倍,但其中只有2倍来自更快的处理器,其余的6倍来自TPU v3 pod变得更分布式,即使用的处理器比TPU v2 pod多4倍。同样,英伟达发布了两个分布式AI系统:分别是搭载8个GPU和16个GPU的DGX-1和DGX-2。此外,英伟达最近收购了知名网络供应商迈络思,以增强其数据中心中GPU之间的连接性。
2. 调整
情况变得更糟。你不会只训练一次模型。通常,模型的质量取决于各种超参数,比如层数、隐藏单元数量和批大小。找到最佳模型常常需要在各种超参数设置之间进行搜索,这个过程就叫超参数调整,开销可能很大。比如说,RoBERTa是用于预训练NLP模型的可靠技术,它使用的超参数多达17个。假设每个超参数至少有两个值,搜索空间由13万多个配置组成,探索这些空间(哪怕是部分探索)可能需要大量的计算资源。
超参数调整任务的另一个例子是神经架构搜索,它尝试不同的架构,并选择性能最佳的架构,从而使人工神经网络的设计实现自动化。研究人员声称,即使设计一个简单的神经网络也可能需要数十万个GPU计算日。
3. 模拟
虽然深度神经网络模型常常可以利用专用硬件方面的进步,但并非所有机器学习算法都可以。尤其是,强化学习算法涉及大量模拟。由于复杂的逻辑,这些模拟仍然在通用CPU上执行最好(它们将GPU仅用于渲染),因此无法得益于硬件加速器的最新进步。比如说,OpenAI在最近的一篇博文(https://openai.com/blog/openai-five/)中声称,使用128000个CPU核心和仅仅256个GPU(即CPU比GPU多500倍)来训练玩《Dota 2》游戏时能击败爱好者的模型。
虽然《Dota 2》只是个游戏,但我们看到模拟日益用在决策应用领域中,这个领域出现了几家新兴公司,比如Pathmind、Prowler和Hash.ai。由于模拟器试图更准确地对环境建模,复杂性随之增加。这又大大增强了强化学习的计算复杂性。
小结
大数据和AI在迅速改变我们所知道的世界。虽然任何技术革命都存在危险,但我们看到这场革命大有潜力以十年前根本无法想象的方式改善我们的生活。然而要兑现这一承诺,我们需要克服这些应用的需求与硬件功能之间迅速拉大的差距所带来的巨大挑战。为了缩小这个差距,我们只能分发这些应用。这需要新的软件工具、框架和课程来培训和帮助开发人员构建这类应用。这开启了一个新的、令人兴奋的计算时代。
原文标题:The Future of Computing is Distributed,作者:Ion Stoica
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】