什么是 HTTP 缓存
HTTP 缓存可以说是HTTP性能优化中简单高效的一种优化方式了,缓存是一种保存资源副本并在下次请求时直接使用该副本的技术,当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去源服务器重新下载。
一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,节省网络流量,并且由于缓存文件可以重复利用,降低网络负荷,提高客户端响应。
所以,学会利用 HTTP 缓存是很有必要的。
在此,我会向大家系统的介绍HTTP缓存机制,期望对各位正确的理解HTTP缓存有所帮助。
缓存策略
在阐述HTTP不同缓存策略之前,我们需要知道用户刷新/访问行为 的手段分成三类:
- 在URI输入栏中输入然后回车/通过书签访问
- F5/点击工具栏中的刷新按钮/右键菜单重新加载
- Ctl+F5 (完全不使用HTTP缓存)
不同的刷新手段,会导致浏览器使用不同的缓存策略,我们下面会分析到
HTTP 缓存主要是通过请求和响应报文头中的对应 Header 信息,来控制缓存的策略。
响应头中相关字段为Expires、Cache-Control、Last-Modified、Etag。
HTTP缓存的类型很多,根据是否需要重新向服务器发起请求来分类包括两种:强制缓存和对比缓存
假设浏览器有一个缓存数据库用于本地缓存,先看看浏览器请求资源的情况:
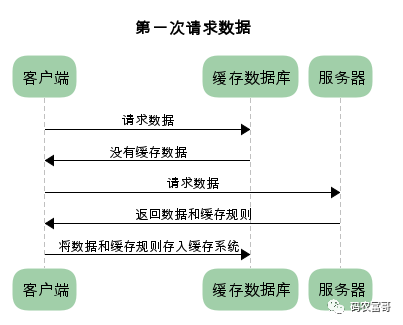
强制缓存
在浏览器已经缓存数据的情况下,使用强制缓存去请求数据的流程是这样的:
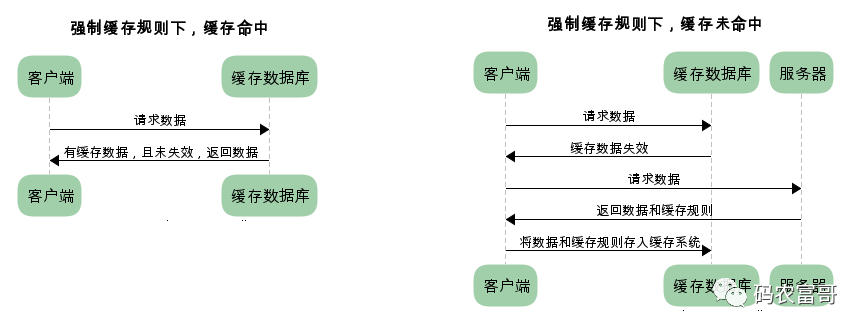
从流程图可以看到,强制缓存,在缓存数据未失效的情况下,可以直接使用缓存数据,不需要再请求服务器,那么浏览器是如何判断缓存数据是否失效呢?
对于强制缓存来说,响应header中会有两个字段来标明失效规则(Expires/Cache-Control):
- Expires:
Expires 是 HTTP1.0 的产物了,现在默认浏览器均默认使用 HTTP 1.1,所以它的作用基本忽略。但是很多网站还是对它做了兼容。它的值为服务端返回的到期时间,即下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。
但有一个问题是到期时间是由服务端生成的,如果客户端时间跟服务器时间不一致,这就会导致缓存命中的误差。
在 HTTP 1.1 的版本,Expires 被 Cache-Control 替代。
- Cache-Control:
Cache-Control 是最重要的规则。常见的取值有 private、public、no-cache、max-age,no-store,默认为 private。
1) max-age:用来设置资源(representations)可以被缓存多长时间,单位为秒;
2) s-maxage:和 max-age 是一样的,不过它只针对代理服务器缓存而言;
3) public:指示响应可被任何缓存区缓存;
4) private:只能针对个人用户,而不能被代理服务器缓存;
5) no-cache:强制客户端直接向服务器发送请求,也就是说每次请求都必须向服务器发送。服务器接收到请求,然后判断资源是否变更,是则返回新内容,否则返回304,未变更。这个很容易让人产生误解,使人误以为是响应不被缓存。实际上Cache-Control: no-cache是会被缓存的,只不过每次在向客户端(浏览器)提供响应数据时,缓存都要向服务器评估缓存响应的有效性。
6) no-store:禁止一切缓存(这个才是响应不被缓存的意思)。
举个例子,比如一个资源响应头是:
- cache-control: public, max-age= 31536000
那么这个资源会被缓存31536000秒(365天),在365天内再次请求这条数据,都会直接获取缓存数据库中的数据,直接使用。
那么我们试试再次访问资源,会有以下的响应:

可以看到HTTP状态码是200,Size这个字段显示:disk cache,说明浏览器确实走了强制缓存,没有再跟浏览器交互。
我们上面说了,不同的访问/刷新手段,会使浏览器使用不同的缓存策略,要让浏览器走强制缓存对请求方式有一个要求: 在URI输入栏中输入然后回车/通过书签访问。
对比缓存
在浏览器已经缓存数据的情况下,使用对比缓存去请求数据的流程是这样的。
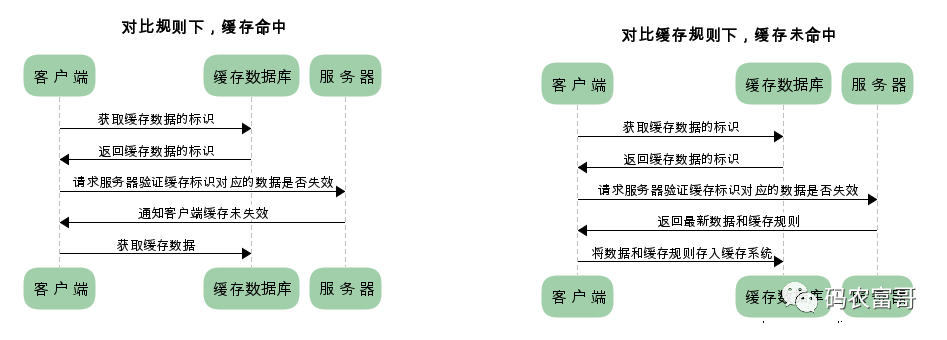
有同学可能会问,基于对比缓存的流程下,不管是否使用缓存,都需要向服务器发送请求,那么还用缓存干什么?
这个问题,我们现在来探讨一下。
对比缓存,顾名思义,需要进行比较判断是否可以使用缓存。
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给浏览器,浏览器将二者备份至缓存数据库中。
当浏览器再次请求数据时,浏览器将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据。
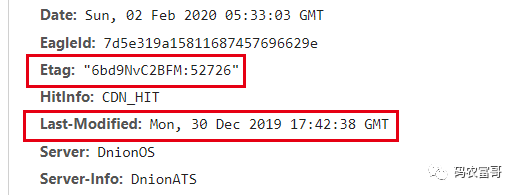
举个例子,第一次访问:

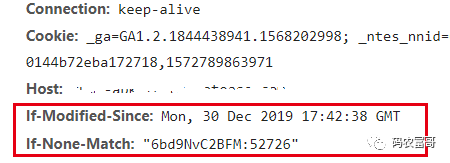
第二次访问:

对于对比缓存来说,响应 header 中会有两个字段来标明规则
- Last-Modified / If-Modified-Since
服务器响应请求时,会告诉浏览器一个告诉浏览器资源的最后修改时间:Last-Modified,浏览器之后再请求的时候,会带上一个头:If-Modified-Since,这个值就是服务器上一次给的 Last-Modified 的时间,服务器会比对资源当前最后的修改时间,如果大于If-Modified-Since,则说明资源修改过了,浏览器不能再使用缓存,否则浏览器可以继续使用缓存,并返回304状态码。
- Etag / If-None-Match(优先级高于Last-Modified / If-Modified-Since)
服务器响应请求时,通过Etag头部告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定),浏览器再次请求时,就会带上一个头If-None-Match,这个值就是服务器上一次给的Etag的值,服务器比对一下资源当前的Etag是否跟If-None-Match一致,不一致则说明资源修改过了,浏览器不能再使用缓存,否则浏览器可以继续使用缓存,并返回304状态码。
看个例子:第一次请求,服务器的响应头包含了:
第二次请求,浏览器的请求头
总结
我们再看一下HTTP缓存的一个总概流程图:
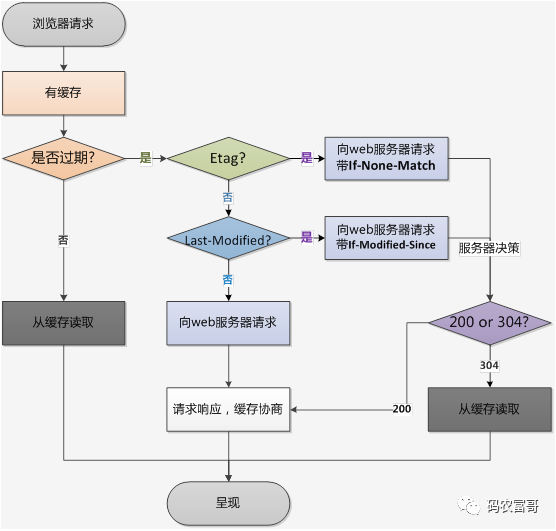
- HTTP缓存主要分强制缓存和对比缓存
- 强制缓存的 HTTP 相关头部 Cache-Control,Exipres(HTTP1.0),浏览器直接读本地缓存,不会再跟服务器端交互,状态码 200。
- 对比缓存的 HTTP 相关头部 Last-Modified / If-Modified-Since, Etag / If-None-Match (优先级比Last-Modified / If-Modified-Since高),每次请求需要让服务器判断一下资源是否更新过,从而决定浏览器是否使用缓存,如果是,则返回304,否则重新完整响应。