将 Bishop 大神的 PRML 称为机器学习圣经一点也不为过,该书系统地介绍了模式识别和机器学习领域内详细的概念与基础。书中有对概率论基础知识的介绍,也有高阶的线性代数和多元微积分的内容,适合高校的研究生以及人工智能相关的从业人员学习。
知乎上关于这个关于“PRML为何是机器学习的经典书籍中的经典?”的高赞回答或许会给大家一些启发:

Luau Lawrence的回答:
https://www.zhihu.com/question/35992297/answer/67009652
PRML 对初学者确实有一定难度,如果觉得吃力可以先读一下知乎上推荐的科普性读物,掌握了机器学习的基础概念之后再进行后续的学习。
知乎讨论地址:
https://www.zhihu.com/question/35992297
首先我们来看一下 PRML 的主要内容:
第一章是引子,用曲线拟合让读者对机器学习有个大概理解。
第二章主要是介绍了一下基础的统计方面的知识,包括期望方差的计算、高斯分布的参数估计与理解、高斯分布的性质等。
第三章和第四章主要在讲最基础的线性模型,并且展示了如何将其应用在分类和回归的场景下,贝叶斯方法是整本书的核心。
第五章介绍了神经网络,在线性模型的基础上引入了多层感知机模型,即常说的 BP 网络。
第六章讲的是核方法,核是两个样本的内积,也可以理解为某个希尔伯特空间中由内积定义的“距离”。主要讲了线性模型转成核表达的方式、核的构建以及高斯过程。
第七章是向量机,向量机讲的是贝叶斯模型如何通过先验找到一个稀疏的模型。
第八章是讲的图模型,对变量的独立性、隐变量和参数的区别(这个会在变分贝叶斯中体现)做了很好的阐释。
第九章讲了混合模型和 EM 算法,涉及了隐变量的概念和 EM 算法等。
第十章讲的是变分推断,解决了基于现在的模型的分布假设,推断参数难的问题。
第十一章讲采样方法,介绍了不同采样方法的优缺点,并重点讲了MCMC采样。
第十二章讲主成分分析,是考察多个变量间相关性一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构。
第十三章讲的是序列数据,序列数据的特点及马尔可夫假设等。
第十四章讲的是 Ensemble,包括适应性的 boosting 最著名的 AdaBoost,以及一些其他的融合方法。
看这些理论知识是非常枯燥的,很多初学者感觉学起来非常吃力,甚至半途放弃,如果你也有这些困扰,那么下面提到的这个 GitHub 项目也许可以帮你走出困境。
在 notebooks 文件夹下实现了聚类方法、特征抽取、线性模型、核方法、马尔科夫模型、概率分布模型、采样方法和神经网络方法等内容,你可以将目录切换到
notebooks 下直接打开对应的 ipynb 文件进行练习。
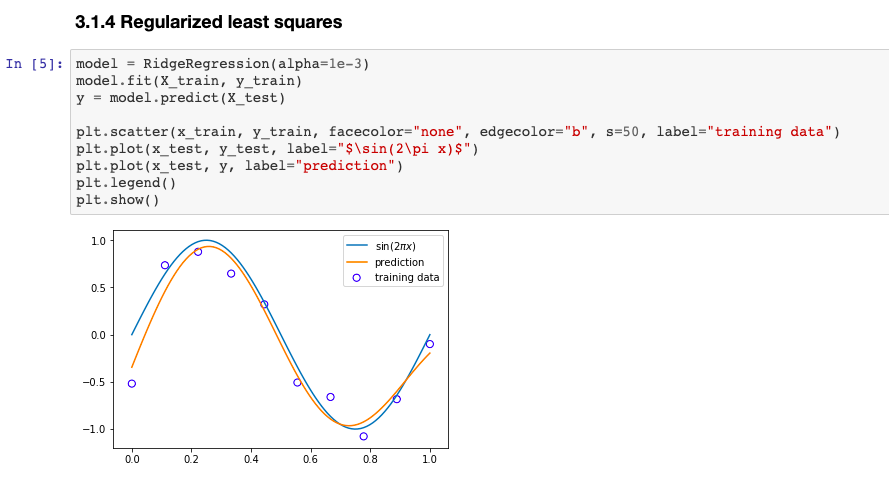
该 GitHub 项目所需要的编程语言为 Python 3,其它科学计算库还需要 NumPy 、SciPy、 Matplotlib、Scikit-learn 等,如果你是 Python 初学者,那么我们强力推荐你安装 Annaconda,它集成了所有需要的计算库,并且可以在 jupyter notebook 交互式的查看执行的结果。
这么好的资源赶紧学起来吧!
GitHub链接:
https://github.com/ctgk/PRML