













当Python 有读写 MySQL 数据的需求时,我们经常使用PyMySQL这个第三方库来完成。
有时候如果一张表里面的数据非常大,但是我们只需要读取一条数据,此时我们可能会想当然地使用cursor.fetchone()这个方法,以为这样就真的可以只读取一条数据:
- import pymysql
- connection = pymysql.connect(host='localhost',
- user='user',
- password='passwd',
- db='db',
- charset='utf8mb4',
- cursorclass=pymysql.cursors.DictCursor)
- with connection.cursor() as cursor:
- db = 'select * from users where age > 10'
- cursor.execute(db)
- one_user = cursor.fetchone()
但实际上,上面这段代码,与下面这段代码没有任何区别:
- ...
- with connection.cursor() as cursor:
- sql = 'select * from users where age > 10'
- cursor.execute(sql)
- all_users = cursor.fetchall()
- one_user = all_users[0]
这是因为,当我们执行到cursor.execute(sql)的时候,PyMySQL就已经把表里面所有的数据读取到内存中了。而后面的cursor.fetchall()或者cursor.fetchone()只不过是从内存中返回全部数据还是返回1条数据而已。
我们来看PyMySQL的源代码[1]。在cursor.execute()方法代码如下图所示:
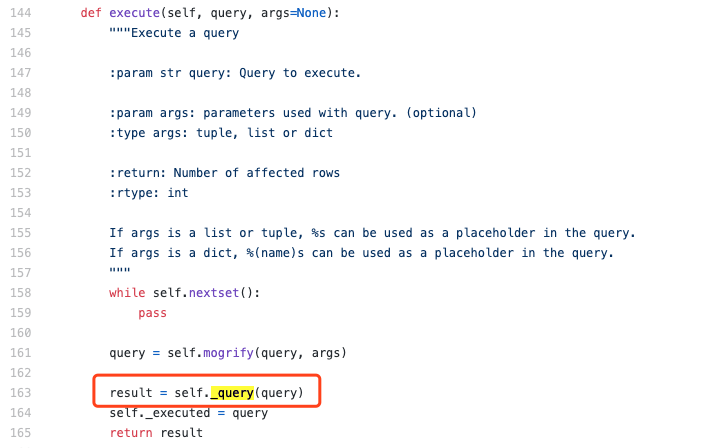
其中第163行调用了self._query方法。我们再去到这个方法里面:

看到代码第322行,调用了self._do_get_result()方法。我们再去这个方法里面看看:
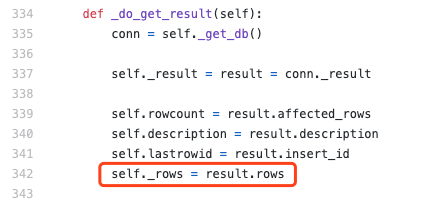
注意代码第342行,此时已经把所有数据存放到了self._rows列表中。
现在我们来看cursor.fetchone()方法:

可以看到,这里不过是从列表里面根据下标读取一条数据出来而已。
再看cursor.fetchall()方法:

如果之前先多次调用过cursor.fetchone(),那么self.rownumber会持续增加。而调用cursor.fetchall()时,跳过之前已经返回过的数据,直接返回剩下的全部数据即可。如果之前没有调用过cursor.fetchone(),那么直接返回全部数据。
所以,单纯使用cursor.fetchone()并不能节省内存,如果表里面的数据非常大,还是会有内存爆炸的危险。
那么真正的解决办法是什么呢?真正的解决办法在创建数据库连接的时候指定游标类型。pymysql.connect有一个参数叫做cursorclass,把它的值设定为pymysql.SSDictCursor即可解决问题。
我们来看一下如何正确使用它:
- import pymysql
- connection = pymysql.connect(host='localhost',
- user='user',
- password='passwd',
- db='db',
- charset='utf8mb4',
- cursorclass=pymysql.cursors.SSDictCursor)
- with connection.cursor() as cursor:
- db = 'select * from users where age > 10'
- cursor.execute(db)
- for row in cursor:
- print('对 cursor 直接进行迭代,每循环一次,从数据库读取一条数据。不会提前把所有数据读取到内存中。')
- print(row['name'])



















