













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
从节点架构到网络架构,再到通信算法,阿里巴巴把自研的高性能AI集群技术细节写成了论文,并对外公布。
论文名为EFLOPS: Algorithm and System Co-design for a High Performance Distributed Training Platform,被计算机体系结构顶级会议HPCA 2020收录。阿里是国内唯一有论文收录的企业,论文作者之一、阿里资深技术专家蒋晓维在会议现场分享了论文内容。

除了展示AI集群技术细节,他还介绍了其如何为阿里巴巴内部业务和算法带来价值。这一集群已应用于阿里巴巴计算平台的人工智能训练平台(PAI),服务阿里巴巴的人工智能业务的模型训练:
能将拍立淘百万分类大模型的训练速度提升4倍,并首次支持千万分类模型的训练;在提升阿里巴巴翻译模型精度的同时,能将训练时间从100小时降低至12小时。
而且与世界顶级的AI计算系统相比,阿里的AI集群虽然使用了性能较低的硬件资源,但表现出了相当的性能。
这是阿里巴巴首次对外披露高性能AI集群的性能,具体情况如何?我们根据阿里研究团队提供的解读一一来看。
从业务出发,优化AI集群架构
由于深度神经网络的技术突破,围绕AI的技术研究,如AI算法模型、训练框架、以及底层的加速器设计等,引起越来越多的关注,而且应用越来广泛,已经落地到社会生活的各个方面。
“然而极少有人从集群架构角度探究过,AI业务的运行模式与传统大数据处理业务的差别,以及AI集群的架构设计应该如何优化,“阿里研究团队表示。
他们认为,虽然AI业务存在很强的数据并行度,但与大数据处理业务和高性能计算业务特征存在明显的不同。核心差别有两点:
第一,AI业务的子任务独立性很低,需要周期性地进行通信,实现梯度的同步;第二,AI业务的运行以加速部件为中心,加速部件之间直接通信的并发度显著高于传统服务器。
因此,在传统数据中心的服务器架构和网络架构上运行AI业务,会存在很多严重的问题。
具体来说,服务器架构问题,主要是资源配置不平衡导致的拥塞问题,以及PCIe链路的QoS问题。
一般情况下,传统服务器配备一张网卡用于节点间通信,为了支持AI业务会配置多个GPU。
但AI训练经常需要在GPU之间进行梯度的同步,多GPU并发访问网络,唯一的网卡就会成为系统的瓶颈。
此外,PCIe链路上的带宽分配与路径长度密切相关,长路径获得的带宽分配较低,而跨Socket通信的问题更加严重。
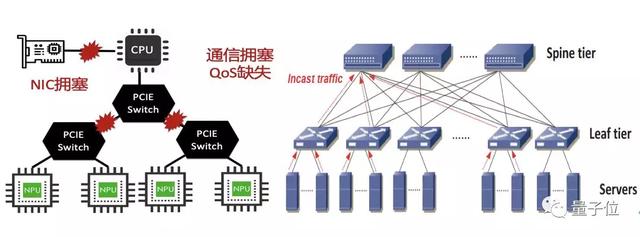
网络架构问题,主要在于AI训练中同步通信导致的短板效应。网络拥塞本是一个非常普遍的问题,相关研究已经持续了几十年。
但拥塞控制算法的最终目的,在于对两个碰撞的流进行限速,使其尽快达到均分物理带宽的目的,并不能解决AI训练集群的通信效率问题。
由于AI业务通信的同步性,每个通信事务的最终性能决定于最慢的连接。均分带宽意味着事务完成时间的成倍提升,会严重影响AI通信的性能。
基于此,阿里巴巴决定为AI业务自研高性能AI集群。
阿里AI集群的关键技术
阿里巴巴自研的高性能AI集群名为EFlops,关键技术一共有三个:网络化异构计算服务器架构、高扩展性网络架构、与系统架构协同的高性能通信库。
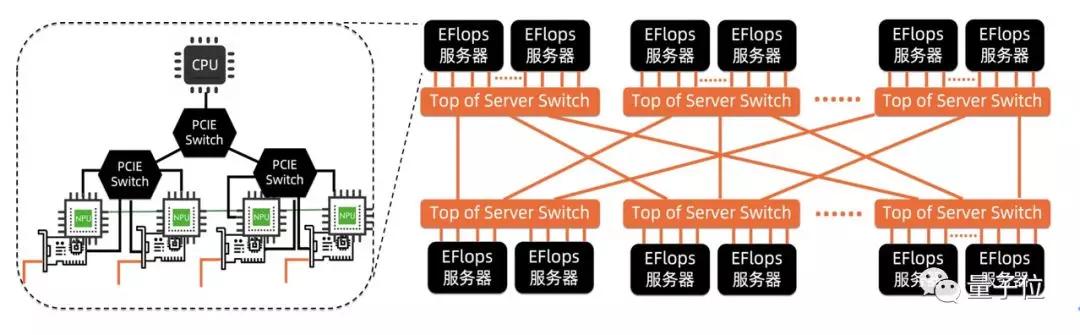
为了避免网卡上的数据拥塞,他们为每个GPU提供专用的网卡,来负责与其他GPU的通信。
此外,基于Top-of-Server的设计思想,将节点内加速器之间的通信导出到节点外,并利用成熟的以太网QoS机制来保证拥塞流量之间的公平性。
研究团队认为,随着加速器芯片计算能力的快速提升,对通信性能提出越来越高的需求,这种多网卡的网络化异构计算服务器架构将很快成为主流。
在网络架构层面,EFlops设计了BiGraph网络拓扑,在两层网络之间提供了丰富的链路资源,提供了跨层路由的可控性。
配合多网卡服务器结构,他们在EFlops项目中提出了BiGraph网络拓扑,其与传统的Fat-tree拓扑有相似之处,也存在根本的区别。
与Fat-tree拓扑类似的地方在于,他们将网络中的分为两部分(Upper和Lower),各部分之间通过Clos架构进行互连,形如两层Fat-tree拓扑的Spine和Leaf交换机。
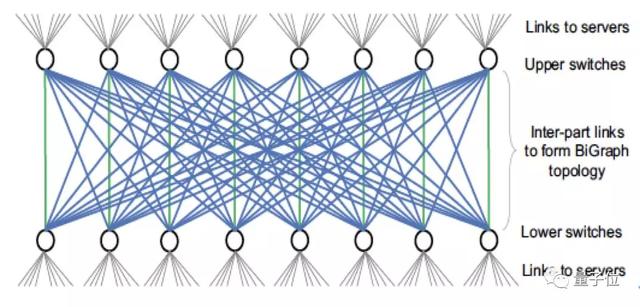
与Fat-tree不同的是,他们在两部分交换机上都可以直接接入计算服务器;即每一个交换机都扮演了Fat-tree拓扑中的Spine和Leaf两个角色,最大跳步数为3。
也给BiGraph拓扑带来了两个重要的特性:
一方面,在两层交换机之间提供了丰富的物理链路资源。在N个计算服务器的系统中,两层交换机之间至少存在着N/2个物理链路可供使用。另一方面,接入不同层次的任意两个计算服务器之间的最短路径具有唯一性。
因此,他们可以充分利用这一特性,在通信库甚至更高层次进行服务器间通信模式的管理。比如,在建立连接的时候,选择合适源和目的服务器,来控制网络上的路径选择。
想要说清楚这一点,需要引入一个新的概念:Allreduce——数据并行训练场景下的最主要集合通信操作。
其中常用的通信算法有Ring-based(Ring)、Tree-based(Tree)和Halving-Doubling(HD)等。
在阿里巴巴的这篇论文中,主要关注的是Ring和HD,前者是应用范围最广的算法之一,后者是他们在这一研究中的优化对象。
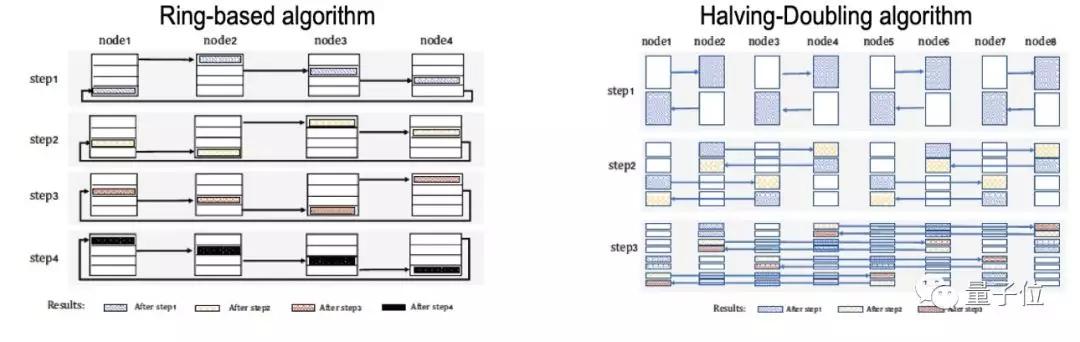
Ring和HD算法在数据传输量上没有区别,都是2S;其中S是Message的大小。从通信次数角度看,Ring算法需要N-1个Step的通信,而HD算法只需要log2N个Step;其中N是参与节点个数。
而Ring算法只需要N个连接,而HD算法需要N*log2N个连接。需要特别指出的是,HD算法的每个Step只需要N/2个连接。
结合BiGraph拓扑的特性进行分析,可以看到:BiGraph拓扑两层交换机之间存在N/2个物理链路,而HD算法每个step需要N/2个连接。
BiGraph拓扑两层交换机之间最短路径的确定性,提供了一种可能性:将HD算法的连接和BiGraph拓扑的物理链路进行一一映射,避免它们之间的链路争用,以彻底解决网络拥塞问题。
基于此,他们也进一步提出了Rank映射算法,将HD算法的通信连接一一映射至BiGraph网络的物理链路,避免了网络的拥塞,该算法Halving-Doubling with Rank-Mapping(HDRM)已经在阿里定制的集合式通信库ACCL实现。具体步骤如下:

如此集群,性能如何?
为了评估EFlops系统的性能,他们部署了16个节点,共计64个GPU的训练集群。其中每个节点配置了4个Tesla V100-32G的GPU,以及4个ConnectX-5 100Gbps网卡。
网络环境按照BiGraph拓扑进行设计,其中8个物理交换机划分为16个虚拟交换机,分别部署于BiGraph的两层。
研究团队用MLPerf的ResNet50模型评估了集群性能,具体方式是在达到指定准确率之后,计算单位时间图片处理数量。
下图呈现了EFlops系统和单网卡系统的性能对比,包括全系统吞吐量和单GPU平均吞吐量。
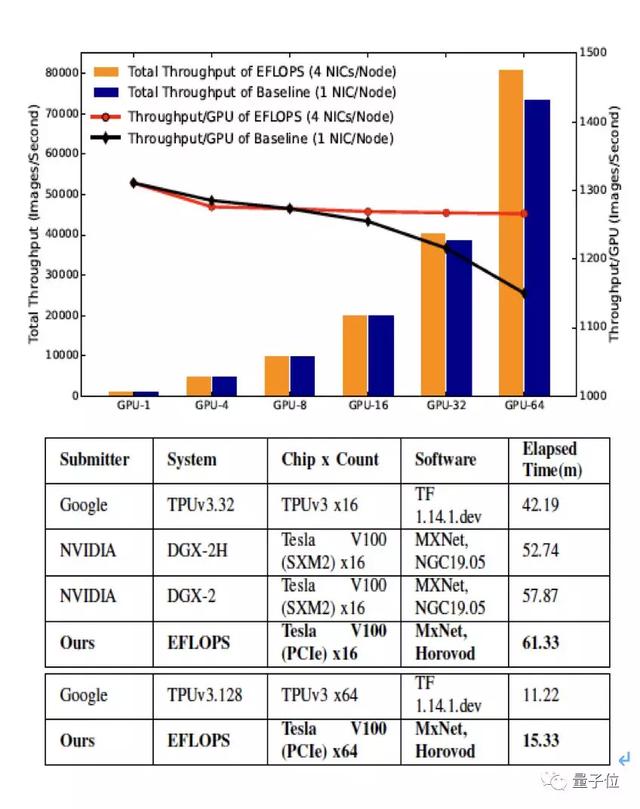
可以看到,EFlops系统的性能基本达到了线性扩展,而单网卡系统的单位吞吐量明显随着规模逐步下降。
与世界顶级的AI计算系统相比,EFlops虽然使用了性能较低的硬件资源(V100-PCIe性能低于V100-SXM2约10%)也表现出了相当的性能。
此外,他们还分析了阿里巴巴内部应用的性能收益。以拍立淘百万分类模型为例,EFlops系统可以提升通信性能5.57倍,端到端性能34.8%。
因为通信量占比不高,HDRM算法提升通信性能43.5%,整体性能4.3%。对BERT模型而言,通信量明显高于拍立淘百万分类模型,仅HDRM算法就可以提升通信性能36%,端到端性能15.8%。
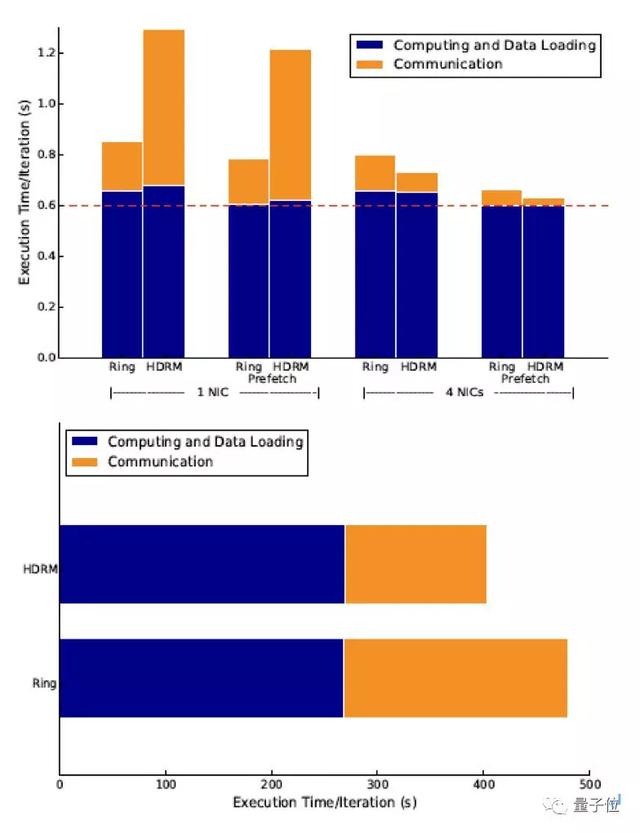
研究团队表示,可以预见,随着系统规模进一步增长,EFlops的性能收益将显著提升。基于64节点集群的收益,他们进一步搭建了512 GPUs的高性能AI训练集群。
初步的评测结果显示,基于ImageNet训练集,在Resnet50模型上,EFlops集群仍然能保持接近线性的扩展性。
阿里巴巴基础设施团队打造
EFlops集群一共有17名阿里的技术专家参与打造,大多来自阿里巴巴基础设施团队,平头哥团队提供支持。

论文的第一作者是董建波,毕业于中科院计算所,现在是阿里巴巴高级技术专家。论文的通讯作者是谢源——阿里巴巴达摩院高级研究员、平头哥首席科学家。
谢源是计算体系结构、芯片设计领域大牛级别的存在,研究方向是计算机体系结构、集成电路设计、电子设计自动化、和嵌入式系统设计,已发表过300多篇顶级期刊和会议论文。
在获得IEEE、AAAS、ACM Fellow称号之后,他在2月28日再次获得国际学术荣誉——IEEE CS 2020年度技术成就奖。




























