












我之前的一篇文章,带大家揭晓了 Python 在给内置对象分配内存时的 5 个奇怪而有趣的小秘密。文中使用了sys.getsizeof()来计算内存,但是用这个方法计算时,可能会出现意料不到的问题。
文档中关于这个方法的介绍有两层意思:
- 该方法用于获取一个对象的字节大小(bytes)
- 它只计算直接占用的内存,而不计算对象内所引用对象的内存
也就是说,getsizeof() 并不是计算实际对象的字节大小,而是计算“占位对象”的大小。如果你想计算所有属性以及属性的属性的大小,getsizeof() 只会停留在第一层,这对于存在引用的对象,计算时就不准确。
例如列表 [1,2],getsizeof() 不会把列表内两个元素的实际大小算上,而只是计算了对它们的引用。举一个形象的例子,我们把列表想象成一个箱子,把它存储的对象想象成一个个球,现在箱子里有两张纸条,写上了球 1 和球 2 的地址(球不在箱子里),getsizeof() 只是把整个箱子称重(含纸条),而没有根据纸条上地址,找到两个球一起称重。
1、计算的是什么?
我们先来看看列表对象的情况:
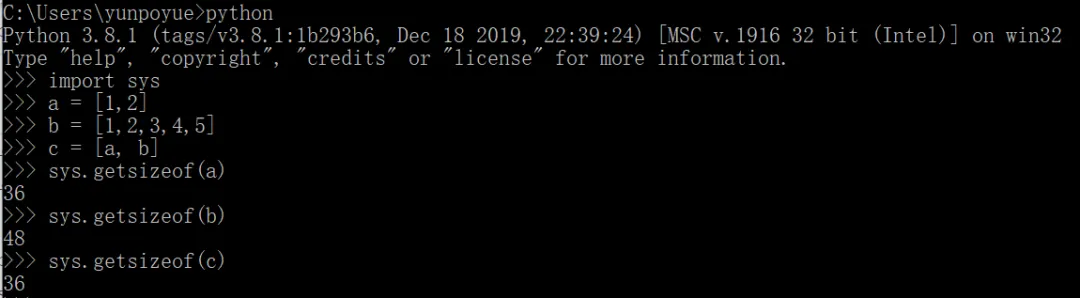
如图所示,单独计算 a 和 b 列表的结果是 36 和 48,然后把它们作为 c 列表的子元素时,该列表的计算结果却仅仅才 36。(PS:我用的是 32 位解释器)
如果不使用引用方式,而是直接把子列表写进去,例如 “d = [[1,2],[1,2,3,4,5]]”,这样计算 d 列表的结果也还是 36,因为子列表是独立的对象,在 d 列表中存储的是它们的 id。
也就是说:getsizeof() 方法在计算列表大小时,其结果跟元素个数相关,但跟元素本身的大小无关。
下面再看看字典的例子:
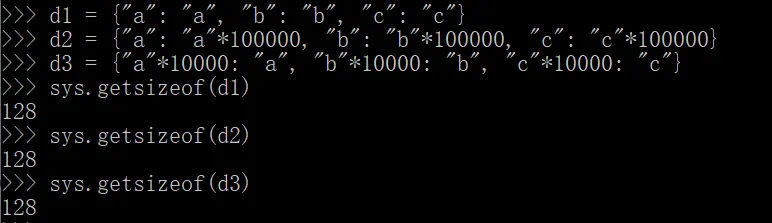
明显可以看出,三个字典实际占用的全部内存不可能相等,但是 getsizeof() 方法给出的结果却相同,这意味着它只关心键的数量,而不关心实际的键值对是什么内容,情况跟列表相似。
2、“浅计算”与其它问题
有个概念叫“浅拷贝”,指的是 copy() 方法只拷贝引用对象的内存地址,而非实际的引用对象。类比于这个概念,我们可以认为 getsizeof() 是一种“浅计算”。
“浅计算”不关心真实的对象,所以其计算结果只是一个假象。这是一个值得注意的问题,但是注意到这点还不够,我们还可以发散地思考如下的问题:
- “浅计算”方法的底层实现是怎样的?
- 为什么 getsizeof() 会采用“浅计算”的方法?
关于第一个问题,getsizeof(x) 方法实际会调用 x 对象的__sizeof__() 魔术方法,对于内置对象来说,这个方法是通过 CPython 解释器实现的。
我查到这篇文章《Python中对象的内存使用(一)》,它分析了 CPython 源码,最终定位到的核心代码是这一段:
- /*longobject.c*/
- static Py_ssize_t
- int___sizeof___impl(PyObject *self)
- {
- Py_ssize_t res;
- res = offsetof(PyLongObject, ob_digit) + Py_ABS(Py_SIZE(self))*sizeof(digit);
- return res;
- }
我看不懂这段代码,但是可以知道的是,它在计算 Python 对象的大小时,只跟该对象的结构体的属性相关,而没有进一步作“深度计算”。
对于 CPython 的这种实现,我们可以注意到两个层面上的区别:
- 字节增大:int 类型在 C 语言中只占到 4 个字节,但是在 Python 中,int 其实是被封装成了一个对象,所以在计算其大小时,会包含对象结构体的大小。在 32 位解释器中,getsizeof(1) 的结果是 14 个字节,比数字本身的 4 字节增大了。
- 字节减少:对于相对复杂的对象,例如列表和字典,这套计算机制由于没有累加内部元素的占用量,就会出现比真实占用内存小的结果。
由此,我有一个不成熟的猜测:基于“一切皆是对象”的设计原则,int 及其它基础的 C 数据类型在 Python 中被套上了一层“壳”,所以需要一个方法来计算它们的大小,也即是 getsizeof()。
官方文档中说“All built-in objects will return correct results” [1],指的应该是数字、字符串和布尔值之类的简单对象。但是不包括列表、元组和字典等在内部存在引用关系的类型。
为什么不推广到所有内置类型上呢?我未查到这方面的解释,若有知情的同学,烦请告知。
3、“深计算”与其它问题
与“浅计算”相对应,我们可以定义出一种“深计算”。对于前面的两个例子,“深计算”应该遍历每个内部元素以及可能的子元素,累加计算它们的字节,最后算出总的内存大小。
那么,我们应该注意的问题有:
- 是否存在“深计算”的方法/实现方案?
- 实现“深计算”时应该注意什么?
Stackoverflow 网站上有个年代久远的问题“How do I determine the size of an object in Python?” [2],实际上问的就是如何实现“深计算”的问题。
有不同的开发者贡献了两个项目:pympler 和 pysize :第一个项目已发布在 Pypi 上,可以“pip install pympler”安装;第二个项目烂尾了,作者也没发布到 Pypi 上(注:Pypi 上已有个 pysize 库,是用来做格式转化的,不要混淆),但是可以在 Github 上获取到其源码。
对于前面的两个例子,我们可以拿这两个项目分别测试一下:
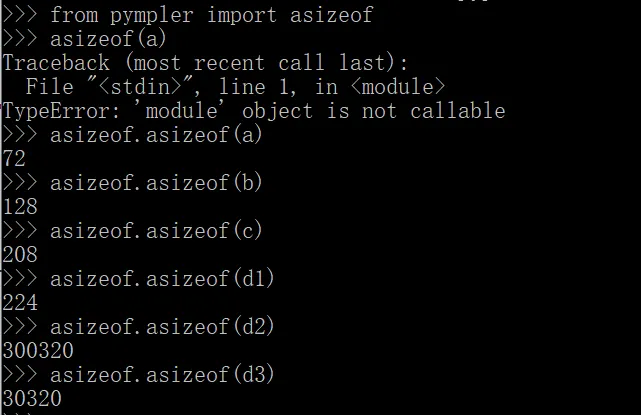
单看数值的话,pympler 似乎确实比 getsizeof() 合理多了。
再看看 pysize,直接看测试结果是(获取其源码过程略):
- 64
- 118
- 190
- 206
- 300281
- 30281
可以看出,它比 pympler 计算的结果略小。就两个项目的完整度、使用量与社区贡献者规模来看,pympler 的结果似乎更为可信。
那么,它们分别是怎么实现的呢?那微小的差异是怎么导致的?从它们的实现方案中,我们可以学习到什么呢?
pysize 项目很简单,只有一个核心方法:
- def get_size(obj, seen=None):
- """Recursively finds size of objects in bytes"""
- size = sys.getsizeof(obj)
- if seen is None:
- seen = set()
- obj_id = id(obj)
- if obj_id in seen:
- return 0
- # Important mark as seen *before* entering recursion to gracefully handle
- # self-referential objects
- seen.add(obj_id)
- if hasattr(obj, '__dict__'):
- for cls in obj.__class__.__mro__:
- if '__dict__' in cls.__dict__:
- d = cls.__dict__['__dict__']
- if inspect.isgetsetdescriptor(d) or inspect.ismemberdescriptor(d):
- size += get_size(obj.__dict__, seen)
- break
- if isinstance(obj, dict):
- size += sum((get_size(v, seen) for v in obj.values()))
- size += sum((get_size(k, seen) for k in obj.keys()))
- elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)):
- size += sum((get_size(i, seen) for i in obj))
- if hasattr(obj, '__slots__'): # can have __slots__ with __dict__
- size += sum(get_size(getattr(obj, s), seen) for s in obj.__slots__ if hasattr(obj, s))
- return size
除去判断__dict__和 __slots__属性的部分(针对类对象),它主要是对字典类型及可迭代对象(除字符串、bytes、bytearray)作递归的计算,逻辑并不复杂。
以 [1,2] 这个列表为例,它先用 sys.getsizeof() 算出 36 字节,再计算内部的两个元素得 14*2=28 字节,最后相加得到 64 字节。
相比之下,pympler 所考虑的内容要多很多,入口在这:
- def asizeof(self, *objs, **opts):
- '''Return the combined size of the given objects
- (with modified options, see method **set**).
- '''
- if opts:
- self.set(**opts)
- self.exclude_refs(*objs) # skip refs to objs
- return sum(self._sizer(o, 0, 0, None) for o in objs)
它可以接受多个参数,再用 sum() 方法合并。所以核心的计算方法其实是 _sizer()。但代码很复杂,绕来绕去像一座迷宫:
- def _sizer(self, obj, pid, deep, sized): # MCCABE 19
- '''Size an object, recursively.
- '''
- s, f, i = 0, 0, id(obj)
- if i not in self._seen:
- self._seen[i] = 1
- elif deep or self._seen[i]:
- # skip obj if seen before
- # or if ref of a given obj
- self._seen.again(i)
- if sized:
- s = sized(s, f, name=self._nameof(obj))
- self.exclude_objs(s)
- return s # zero
- else: # deep == seen[i] == 0
- self._seen.again(i)
- try:
- k, rs = _objkey(obj), []
- if k in self._excl_d:
- self._excl_d[k] += 1
- else:
- v = _typedefs.get(k, None)
- if not v: # new typedef
- _typedefs[k] = v = _typedef(obj, derive=self._derive_,
- frames=self._frames_,
- infer=self._infer_)
- if (v.both or self._code_) and v.kind is not self._ign_d:
- # 猫注:这里计算 flat size
- s = f = v.flat(obj, self._mask) # flat size
- if self._profile:
- # profile based on *flat* size
- self._prof(k).update(obj, s)
- # recurse, but not for nested modules
- if v.refs and deep < self._limit_ \
- and not (deep and ismodule(obj)):
- # add sizes of referents
- z, d = self._sizer, deep + 1
- if sized and deep < self._detail_:
- # use named referents
- self.exclude_objs(rs)
- for o in v.refs(obj, True):
- if isinstance(o, _NamedRef):
- r = z(o.ref, i, d, sized)
- r.name = o.name
- else:
- r = z(o, i, d, sized)
- r.name = self._nameof(o)
- rs.append(r)
- s += r.size
- else: # just size and accumulate
- for o in v.refs(obj, False):
- # 猫注:这里递归计算 item size
- s += z(o, i, d, None)
- # deepest recursion reached
- if self._depth < d:
- self._depth = d
- if self._stats_ and s > self._above_ > 0:
- # rank based on *total* size
- self._rank(k, obj, s, deep, pid)
- except RuntimeError: # XXX RecursionLimitExceeded:
- self._missed += 1
- if not deep:
- self._total += s # accumulate
- if sized:
- s = sized(s, f, name=self._nameof(obj), refs=rs)
- self.exclude_objs(s)
- return s
它的核心逻辑是把每个对象的 size 分为两部分:flat size 和 item size。
计算 flat size 的逻辑在:
- def flat(self, obj, mask=0):
- '''Return the aligned flat size.
- '''
- s = self.base
- if self.leng and self.item > 0: # include items
- s += self.leng(obj) * self.item
- # workaround sys.getsizeof (and numpy?) bug ... some
- # types are incorrectly sized in some Python versions
- # (note, isinstance(obj, ()) == False)
- # 猫注:不可 sys.getsizeof 的,则用上面逻辑,可以的,则用下面逻辑
- if not isinstance(obj, _getsizeof_excls):
- s = _getsizeof(obj, s)
- if mask: # align
- s = (s + mask) & ~mask
- return s
这里出现的 mask 是为了作字节对齐,默认值是 7,该计算公式表示按 8 个字节对齐。对于 [1,2] 列表,会算出 (36+7)&~7=40 字节。同理,对于单个的 item,比如列表中的数字 1,sys.getsizeof(1) 等于 14,而 pympler 会算成对齐的数值 16,所以汇总起来是 40+16+16=72 字节。这就解释了为什么 pympler 算的结果比 pysize 大。
字节对齐一般由具体的编译器实现,而且不同的编译器还会有不同的策略,理论上 Python 不应关心这么底层的细节,内置的 getsizeof() 方法就没有考虑字节对齐。
在不考虑其它 edge cases 的情况下,可以认为 pympler 是在 getsizeof() 的基础上,既考虑了遍历取引用对象的 size,又考虑到了实际存储时的字节对齐问题,所以它会显得更加贴近现实。
4、小结
getsizeof() 方法的问题是显而易见的,我创造了一个“浅计算”概念给它。这个概念借鉴自 copy() 方法的“浅拷贝”,同时对应于 deepcopy() “深拷贝”,我们还能推理出一个“深计算”。
前面展示了两个试图实现“深计算”的项目(pysize+pympler),两者在浅计算的基础上,深入地求解引用对象的大小。pympler 项目的完整度较高,代码中有很多细节上的设计,比如字节对齐。
Python 官方团队当然也知道 getsizeof() 方法的局限性,他们甚至在文档中加了一个链接 [3],指向了一份实现深计算的示例代码。那份代码比 pysize 还要简单(没有考虑类对象的情况)。
未来 Python 中是否会出现深计算的方法,假设命名为 getdeepsizeof() 呢?这不得而知了。
本文的目的是加深对 getsizeof() 方法的理解,区分浅计算与深计算,分析两个深计算项目的实现思路,指出几个值得注意的问题。
读完这里,希望你也能有所收获。若有什么想法,欢迎一起交流。












