题记:谁具有灵活的外在表现形式,谁就能获得回报——这正是进化的精髓所在。——凯文·凯利 《失控》
熟知的互联网协议栈给了我们深刻的“细腰”概念。但这种架构是如何产生的?它是必然的吗?“细腰”架构在商业、技术、工程上给了我们哪些启示?互联网新的细腰结构在哪里?
故事1:CPU指令集的烽火战事
处理器大战的这段历史,已经沉睡在计算机历史的博物馆之中,鲜有人提及。
在20多年前,有许多不同的处理器平台,战事一触即发。
首先是Intel的x86平台,从8086开始,然后是8088、80286、80386,再到奔腾,等等,这些被称为CISC(复杂指令集计算机)。
而在战场的另一边,则是基于RISC的处理器,苹果产品、思科路由器和Sun Sparc工作站。
战事的争论可以归结为:Intel x86 ISA是复杂混乱的,有点特别,难以使用,有时有bug,但在芯片级别提供了很多功能。另一方面,基于RISC的处理器有一个更简单的ISA,更多的功能留给上层的软件来完成。
二十多年后,战事的温度已经消散,Intel x86 ISA轻松获胜。我们仍然记得苹果和思科的产品线从基于RISC的处理器转移到x86平台;AMD第一次开始制造x86“界面”的处理器,为了运行兼容英特尔处理器的软件。
x86 ISA能够获胜的原因是什么?
英特尔x86 ISA杂乱无章,伴随着摩尔定律总是在一段时间内增加更多的功能,而与之竞争的RISC处理器则保持非常简洁,把更多功能留给了上层软件应用。
这个原因可能是违背了大多数人的直觉。
事实上,微软首席研究研究员Andrew Baumann在《硬件是新的软件》一文中总结了 Intel x86 cpu和ISA的复杂性增长,并使用英特尔在2015-2016年围绕软件安全向x86 ISA添加12条新指令作为例子,展示了处理器在一段时期内所增加的复杂性。尽管12条新指令听起来可能不多,但这些特殊的指令要求在CPU中创建新的寄存器、新的堆栈结构(包括听起来相当复杂的新影子堆栈)、新的异常处理进程(用于中断)、更改内存页表格式等等。
这么做的主要目的是使开发人员能够停止对软件特定安全部分的信任,而开始信任硬件,而硬件(在理论上)是不能改变的。
原来如此。
Andrew Baumann说道:
摩尔定律(Moore’s Law)的放缓将加大销售CPU的难度:如果没有微架构方面的改进,它们的运行速度不会大幅提高,也不会大幅提高能效,而且它们的核心数量与以前的cpu差不多,价格也与以前的CPU差不多。为什么会有人买一个新的CPU?英特尔转向的一个原因是它的功能:如果新的CPU实现了一个重要的ISA扩展——比如说,一个软件需要至关重要的安全扩展——消费者将有充分的理由升级。
如果把计算机系统堆栈分层来看,上层是应用程序,底层是实际的硬件,ISA是整个堆栈的细腰部分。Andrew Baumann在《硬件是新的软件》这样总结到:“作为当今商品技术堆栈中最稳定的‘细腰’接口,x86 ISA对于很多系统来说都是一个关键点。”
哲学:
- 细腰在应对复杂问题的过程中非常重要。拥有最简单的细腰是在任何系统中降低复杂性的最重要的事情之一。
- 有些情况下,“精简”或者简洁只是工程师的个人品味,和商业无关。
- 反过来看,复杂性是生存的基础,也并不可怕。关键是找到自己增长的“摩尔定律”,比如阿里的复杂性和“双十一”。
- 细腰总是意味着商品化,而商品化反过来又意味着利润下降。
- 细腰厂商要么学会用更少的利润生活,扩展到其他领域,要么学会拓宽腰围(比如像英特尔的SGX)。而拓宽腰围意味着复杂性的增加,大多数情况下是以意想不到的方式,而且这又违背设计者简洁的品味。
- 虽然说软件吞噬世界,但请小心处理硬件和软件之间的界限,在更广泛意义来说,很难区分哪些该是硬件的,哪些该是软件的。
- 那些承担更多工作并对外提供简单接口(隐藏复杂性)的组件(人)将赢得未来。
- 我们总是在拓宽细腰。
故事2:SQL语言的峰回路转
互联网和个人电脑出现之前,贝尔实验室的两位年轻科学家在发明C语言的时候,意识到,“计算机行业的成功在很大程度上取决于培养一批用户,而不是训练有素的计算机专家。”
“他们想要一种查询语言,像英语一样容易阅读,而且还包括数据库管理和操作。对于没有受过正规数学或计算机编程训练的用户来说,这种语言更容易使用。”——20世纪70年代早期,IBM研究院的两位博士Donald Chamberlin和Raymond Boyce在思考关系数据库模型时,意识到查询语言将成为采用该模型的主要瓶颈,于是着手设计一种新的查询语言。
于是,SQL在1974年首次面试。在接下来的几十年里,随着System R、Ingres、DB2、Oracle、SQL Server、PostgreSQL、MySQL(以及更多)等关系数据库占领了软件行业,SQL成为与数据库交互的卓越语言,并成为日益拥挤和竞争激烈的生态系统的通用语言。
然而,随着互联网的不断发展,软件社区发现当时的关系数据库无法处理新的数据规模。之后,两个新的互联网巨头取得了突破,开发了自己的非关系型分布式数据库来应对这种冲击:谷歌的MapReduce(2004年发表论文)和Bigtable(2006年发表论文),以及亚马逊的Dynamo(2007年发表论文)。
这些开创性的论文催生了更多的非关系型数据库,包括Hadoop(基于MapReduce论文,2006年)、Cassandra(深受Bigtable和Dynamo论文的启发,2008年)和MongoDB(2009年)。这一切被称为NoSQL运动。
NoSQL光彩闪耀,似乎是通向工程成功的捷径。之后不久,巴别塔的语言效应开始出现:每个NoSQL数据库都提供了自己独特的查询语言,这意味着需要学习更多的语言;将这些数据库连接到应用程序的难度增加,导致大量脆弱的粘合代码;缺乏第三方生态系统,要求公司开发自己的操作和可视化工具。
巴别塔的故事:当时地上的人们都说同一种语言,当人们离开东方之后,他们来到了示拿之地。在那里,人们想方设法烧砖好让他们能够造出一座城和一座高耸入云的塔来传播自己的名声,以免他们分散到世界各地。上帝来到人间后看到了这座城和这座塔,说一群只说一种语言的人以后便没有他们做不成的事了;于是上帝将他们的语言打乱,这样他们就不能听懂对方说什么了,还把他们分散到了世界各地,这座城市也停止了修建。
还记得数据库领域图灵奖得主Michael Stonebraker的文章《MapReduce: A major step backwards》吗?NoSQL语言的不成熟意味着在应用程序级别需要更多的复杂性。连接的缺乏也导致了去正规化,导致数据膨胀和僵化。
反向的摩擦力使得社区重新回到SQL。首先出现的是Hadoop上的SQL接口(后来是Spark),引领业界从“NoSQL”转向“Not Only SQL”。然后出现了NewSQL:完全支持SQL的新型可伸缩数据库。
业界的焦点聚集在谷歌身上。
谷歌分别在2012年和2017年两次发表Spanner的论文(作者包括最初的MapReduce作者),声称:
虽然这些系统提供了数据库系统的一些优点,但它们缺乏应用程序开发人员经常依赖的许多传统数据库特性。一个关键的例子是健壮的查询语言,这意味着开发人员必须编写复杂的代码来处理和聚合应用程序中的数据。因此,我们决定把Spanner变成一个功能齐全的SQL系统,查询执行与Spanner的其他架构特性紧密结合(比如强一致性和全局复制)。
在论文的后面,他们进一步阐述了从NoSQL到SQL转换的基本原理:
Spanner的原始API提供了NoSQL方法,用于对单个表和交错表进行点查找和范围扫描。虽然NoSQL方法提供了启动Spanner的简单路径,并且在简单的检索场景中仍然很有用,但是SQL在表达更复杂的数据访问模式和将计算推给数据方面提供了重要的附加价值。
这篇文章还描述了SQL的采用并没有止步于Spanner,而是实际上扩展到了谷歌的其余部门,在这些部门,多个系统共享一个共同的SQL语言:
Spanner的SQL引擎共享一种常见的SQL语言,称为“标准SQL”,与谷歌上的其他几个系统包括内部系统,如F1和Dremel(以及其他系统),以及外部系统,如BigQuery…
对于谷歌内的用户,这降低了跨系统工作的障碍。针对扳手数据库编写SQL的开发人员或数据分析人员可以将他们对语言的理解转移到Dremel,而不必考虑语法、空处理等方面的细微差异。
这种方法的成功不言自明。Spanner已经是主要谷歌系统(包括AdWords和谷歌Play)的“真实来源”,而“潜在的云客户对使用SQL非常感兴趣”。
因此,有人质疑:谷歌这个老司机是不是把大数据行业给带偏了?
目前,所有主要的云供应商都提供流行的托管关系数据库服务:例如,Amazon RDS、谷歌云SQL、用于PostgreSQL的Azure数据库、当然也有阿里巴巴的数据库体系。Hadoop、Spark和Kafka上的SQL接口也继续蓬勃发展。
亚马逊 CTO甚至说:(与PostgreSQL和mysql兼容的)Aurora数据库产品是“AWS历史上增长最快的服务”。
这段历史意味着SQL重新回归数据的通用接口。数据分析软件堆栈的细腰已经形成。

哲学:
- 从巴别塔的失败中汲取教训。
- 所有的细腰都是语言接口,而SQL更明显。
- 我们总是在拓宽细腰。
故事3:系统调用原语永存
这张地图,描绘了免费开源软件与微软帝国的史诗般的斗争。
在操作系统的战场上,《软件战争之后》的作者如此评价Unix家族树:Unix和Linux还没有打败Windows的最大原因是工作站供应商没有在软件上一起工作,因此不断地重新实现彼此的特性。
1980年代的“ UNIX战争”之所以发生,是因为许多UNIX供应商(他们的产品均基于原始Bell Labs UNIX的不同版本),其产品略有不同,并引起了激烈的竞争。
Unix在商业爆发之前已经流行了很多年,但是其商业成功的关键是一波低成本工作站的迅速涌现,它迅速将集中式微型计算机推到了一边。这些工作站运行的操作系统在许多情况下几乎与大型系统上的操作系统相同,但是它们更小,更便宜,以至于它们可以部署在单个员工的桌面上。一些供应商进入了该市场以及相关的存储和计算服务器市场。
问题是这些供应商中的每一个都有自己的Unix版本。所有的Unix变体可能都有某种共同的遗产,但是,当它们出现在已部署的系统上时,它们已经完全不同了。类Unix系统的异构网络给系统管理员,开发人员和用户都带来了挑战。每种新的系统类型都有其自己的一套怪癖,错误和不完善的特性要处理。随着各种Unix实现的分歧,它们变得越来越令人讨厌。结果,许多组织试图标准化单个供应商,希望他们选择了正确的供应商。
要么,要么他们转向那些当时没有以任何令人信服的方式运行Unix的廉价新PC系统。但是它们确实运行DOS(最终运行Windows),一旦运行它们,它们都是一样的。打包的软件变得随时可用,到1990年代中期,越来越清楚的是,未来的桌面系统将不再运行Unix。令人沮丧的是,几乎所有Unix工作站供应商都在与Microsoft进行交易,并宣布未来的工作站(和服务器)将改为运行Windows NT。那是一个黑暗的时期。
Linux是在Windows几乎遍布全世界的情况下,尝试拯救世界。但是,几乎从一开始,批评者就开始说Linux会像Unix一样严重地分裂。
事情发展正是如此。
在商业面前,Unix和Linux的似乎没有办法汲取巴别塔的教训。
操作系统的细腰在拓宽,但Unix的哲学却保留了下来。
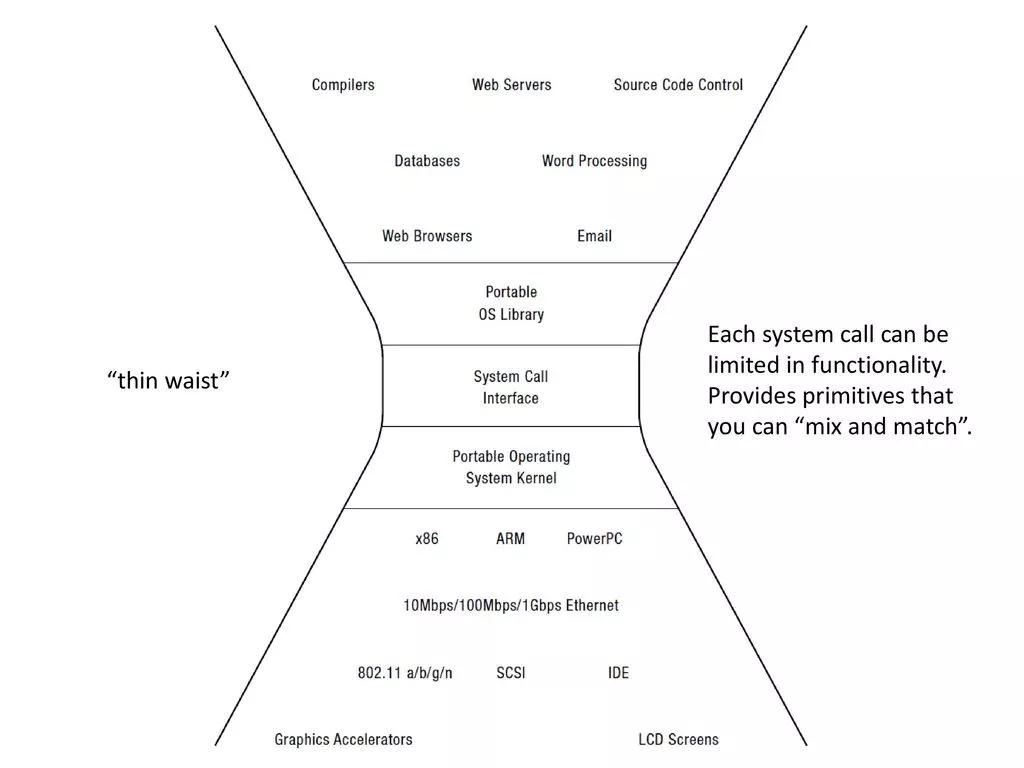
作为细腰模型的案例经常被提及的,一个互联网协议栈,一个是Unix系统调用接口。
正是Unix的哲学让系统调用的原语一直保存下来:
- 模块化规则:编写通过干净接口连接的简单零组件。
- 平行思考:大多数任务由可能并行运行的子任务组成。这也适用于用户交互。并行可以节省大量时间和挫败感。
- 分层思考:层次结构允许跨嵌套元素统一应用任务和属性。这是一个鼓励分解和模块化的重大想法。
哲学:
- 简单。简单性的一个关键方面是正交性。在服务接口中,正交性意味着只有一种方法可以访问任何基本的底层服务或资源。冗余特性增加了接口的复杂性,却没有使它在逻辑上更强大。系统架构师理解接口设计中正交性的价值,并且接受这种简单形式的设计标准。Unix系统调用接口中的一个正交性示例是将目录之间的文件移动分解为三个操作:创建物理链接(使用link())、在目标位置创建链接的副本,然后删除原始链接(使用unlink())。这种复合性的文件移动操作是在用户级命令(mv)中实现的。这使得用户级文件移动操作可以很容易地一般化,包括物理卷之间的移动(这需要复制内容),以及使用link()在同一个卷中实现有效的文件共享。
- 原语。人们经常注意到,操作系统和互联网支持的应用程序的多样性远远超过了其初始设计者所预见的。设计人员创建了一组通用原语,以便这些目标应用处于原语所支持的空间中。这个空间还包括许多其他的应用,包括许多最初没有预见到的应用。
- 抽象。实现资源限制和信息隐藏。细腰层提供其实现中的资源抽象,防止应用程序直接访问它们。信息隐藏是通过隐藏模块的实现细节来实现模块化编程,从而使用户无需了解模块内部的复杂性。
故事4:IP协议适者生存
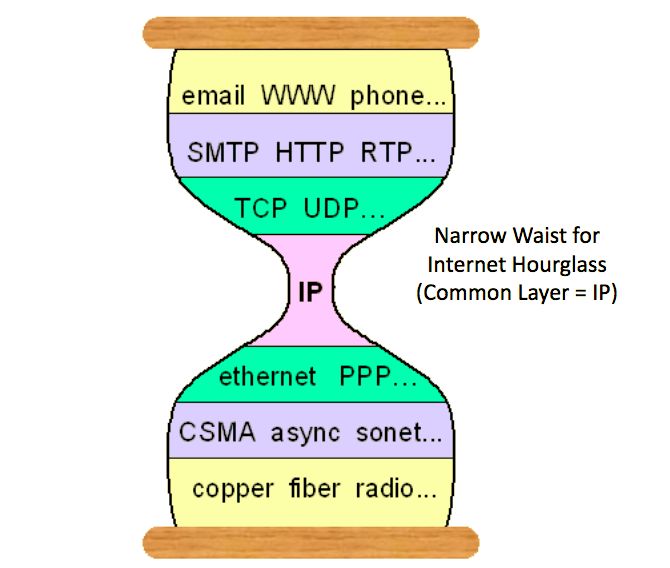
毫无疑问,互联网的细腰是网络层IP协议。尽管有很多文章宣称UDP,TCP,HTTP成为新的细腰,但并没有得到广泛认可。
美国计算机学会(SIGCOMM)数据通信特别兴趣小组在2011年的一项研究表明:互联网细腰结构的出现遵循一个进化模型,称为EvoArch。在自然界中,共享同一生态系统的物种经常争夺资源,导致较弱的竞争者灭绝。互联网架构演变也发生了类似的事情:网络的结构随着不同层新协议的创建而变化,现有协议由于与同一层其他协议的竞争而被删除。
在分组交换网络的发展过程中,开发了许多不同的协议(或协议栈)。随着时间的推移,所有这些协议都被放弃了,转而支持IP协议栈。例如,Banyan Vines有自己基于IP协议的协议栈,称为VIP(Vines Internet Protocol),而Novell NetWare也有自己的基于IPX协议的协议栈,叫做IPX。其他标准化组织同样创建了各自标准的协议族,如国际电信联盟(International Telecommunications Union,ITU)就构建了无连接模式网络服务的协议族(Connectionless Mode Network Service,CLNS)。
为什么这些协议族都半途而废了呢?因为其中一些协议是私有的,许多政府和大型组织出于各种原因拒绝了分组交换网络中私有性质的解决方案。私有协议通常是由少数人群开发和维护的,通常也会缺乏深思熟虑。基于标准的协议可能更复杂,但它们也往往由更多经验丰富的工程师开发和维护。基于CLNS的协议栈在过去的一段时间里一直是个有力的竞争者,但它从未真正在全球互联网上流行起来,而当时全球互联网正成为一股重要的经济力量。还有一些具体的技术原因,例如,CLNS不对线路编号,而是对主机编号。可达性信息的聚合由此受到了许多方面的限制。
——《计算机网络:问题与解决方案》
EvoArch的研究指出:
- 细腰的上部在拓宽,但竞争是你死我活。文件传输协议(FTP)和HTTP提供的服务在特定于应用程序的层中重叠。当HTTP因其自身的高层产品(如Web浏览器等应用程序)而变得更有价值时,FTP就消失了。
- 细腰的底层模块每一个都必不可少,对于网络来说,其主要原因可能是这些协议模块靠近硬件,迭代周期长,没有一个协议能够占绝对的主导地位,所以长时间共同存在。
- 细腰部分出现古老而强大的协议。这些协议被称为演化核心,很难进行重大修改。
- 竞争必然导致细腰,保持细腰多样性的一个建议是在设计服务和功能时候不要重叠,以避免竞争。
- 最好的协议不一定在竞争中获胜。
EvoArch的研究表明,即使未来的互联网架构最初不是以细腰的形状构建的,随着它们的发展,它们也可能演进为细腰的形状。
哲学:
- 自由软件在复杂的环境中工作得很好。也许根本没有人了解全局,但进化并不需要全球的理解,它只需要局部的小改进和一个开放的市场(“适者生存”)。——Linus Torvalds
- 进化的结果,细腰缓慢地沿着协议栈向上移动。
- 良好的细腰设计带来互操作性。
- 细腰结构带来部署扩展性。
- 保持较低的层次通用,以便最有效地满足较高层次的特定要求。
互联网新的细腰结构在哪里?
IP成为互联网协议的细腰之后,业界有两个力量推进细腰结构的演进。
第一个是社区推动整个网络协议栈成为细腰。

第二个是NDN推动IP细腰向内容细腰的转变。
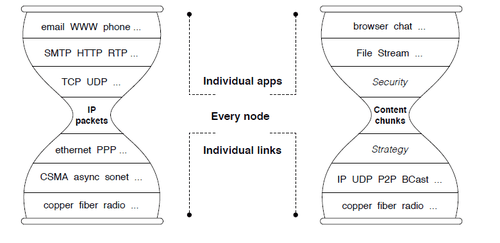
IPFS是一个雄心勃勃的项目,融合了NDN, Git, BitTorrent, IPFS, Tahoe-LAFS, SFS等多种思想,旨在取代HTTP构建新的互联网细腰。
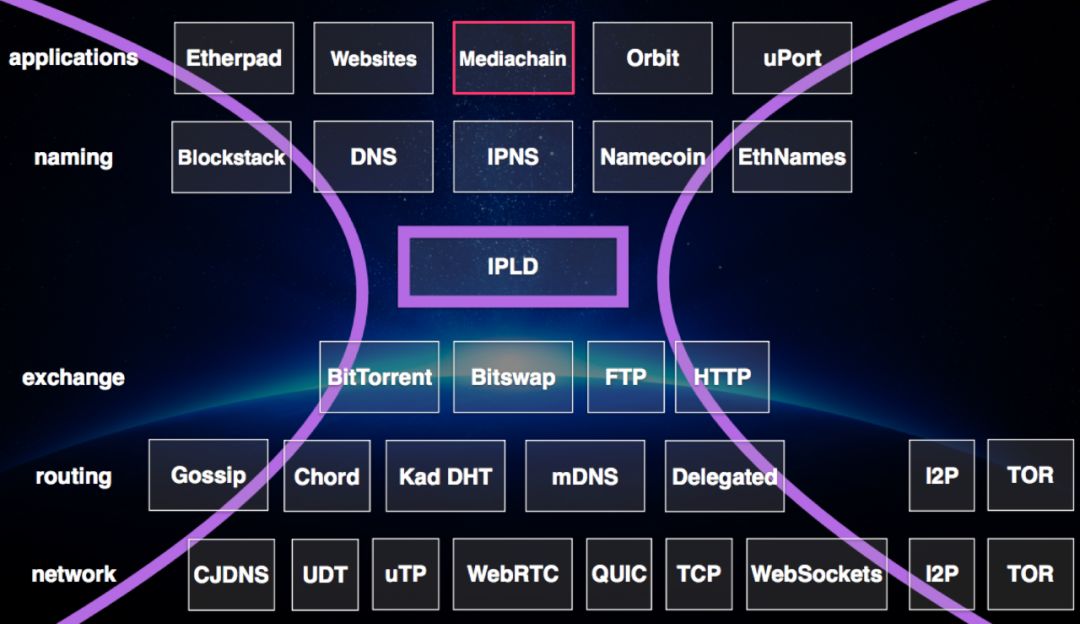
在IPFS协议的腰部,是一个称为星际链式数据(InterPlanetary Linked Data,IPLD)的数据结构。简单来说,IPLD是将传统Posix语义的文件目录树映射为不同节点上的DAG图,称为IPFS unixfs 。IPFS unixfs 使用可插拔的数据分片算法对传统posix 语义的文件进行分片。传统posix 语义的文件是顺序存储的字节,IPFS unixfs 是基于分片的有向无环图。IPFS unixfs的最小单位是分片,这些分片被称为叶子或者数据片,为了构建有向无环图,必然需要引入中间文件对象,这些中间对象通过一定拓扑hash为一个root CID。IPFS unixfs 这种构建图式数据存储的方式被称为IPLD,即是星际链式数据,这也是IPFS 内容寻址的基础。
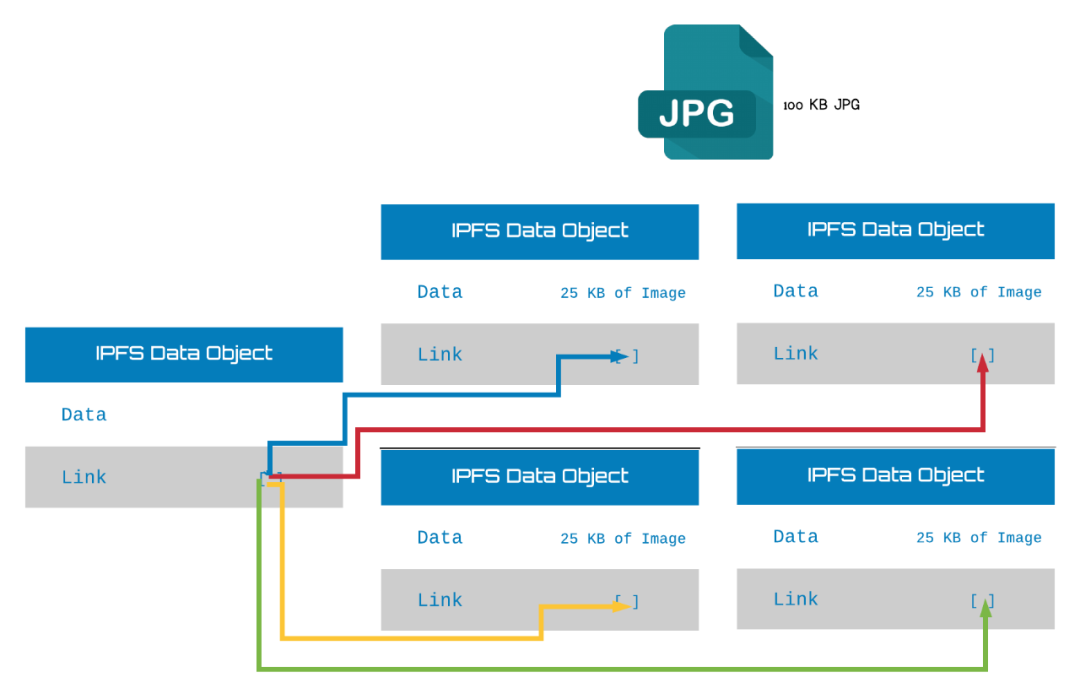
把IPLD这样的数据结构映射在互联网的网络结构之上,IPFS就有了星际互联的能力。
协议在变胖,应用在变瘦,Web正在走向Web3。
和区块链(Filecoin)一起,IPFS正在成为Web3的基础设施。
分布式,模块化,边缘生长,元变化,。。。很多IPFS正在践行的哲学需要IPFS自身给出证明。
我们拭目并报以温暖的期待。
混沌和随机是两回事
在混沌中存在着秩序。——凯文·凯利 《失控》