在不远的过去,数据科学团队需要一些东西来有效地利用深度学习:
- 新颖的模型架构,很可能是内部设计的
- 访问大型且可能是专有的数据集
- 大规模模型训练所需的硬件或资金
这就阻碍了深度学习,将其局限于满足这些条件的少数项目。
然而,在过去几年里,情况发生了变化。
在Cortex,用户推出了基于深度学习的新一代产品,与以前不同的是,这些产品并非都是使用独一无二的模型架构构建的。
这种进步的背后驱动力是迁移学习。
什么是迁移学习?
广义上讲,迁移学习是指在为特定任务训练的模型中积累知识,例如,识别照片中的花可以转移到另一个模型中,以助于对不同的相关任务(如识别某人皮肤上的黑色素瘤)进行预测。
注:如果想深入研究迁移学习,塞巴斯蒂安·鲁德(Sebastian Ruder)已经写了一本很棒的入门书。
迁移学习有多种方法,但有一种方法被广泛采用,那就是微调。
在这种方法中,团队得到一个预训练的模型,并移除/重新训练模型的最后一层,以专注于一个新的、相关的任务。例如,AI Dungeon是一款开放世界的文本冒险游戏,因其人工智能生成的故事极具说服力,而迅速风靡:

值得注意的是,AI Dungeon不是在谷歌的一个研究实验室里开发的,它是由一个工程师建造的项目。
AI Dungeon的创建者尼克·沃尔顿(NickWalton)并不是从头开始设计一个模型的,而是通过采用最先进的NLP模型OpenAI的GPT-2,然后根据自行选择的冒险文本进行微调。
这项工作之所以有效,是因为在神经网络中,最初的层关注简单的、一般的特征,而最终层则关注更多针对任务的分类/回归。吴恩达通过想象一个图像识别模型来可视化这些层和它们的相对特异性水平:
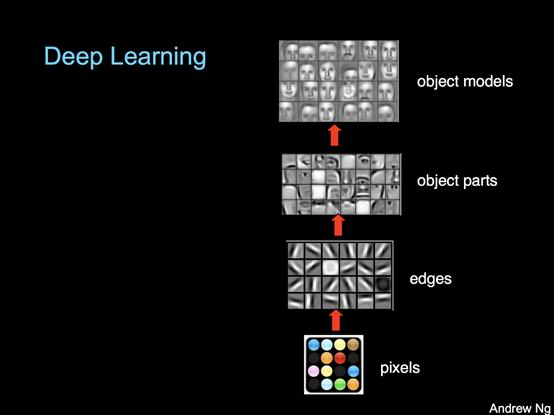
事实证明,基础层的一般知识通常可以很好地转化为其他任务。在AI地牢的例子中,GPT-2对普通英语有着比较先进的理解,只需在其最终层进行一些再训练,就可以在自己选择的冒险类型中表现出色。
通过这个过程,一个工程师可以在几天内将一个模型部署到一个新的领域中,从而获得比较新的结果。
为什么迁移学习是下一代机器学习驱动型软件的关键
在前面,笔者提到机器学习和深度学习所需要的有利条件,特别是要有效地使用这些条件。你需要访问一个大的、干净的数据集,需要设计一个有效的模型,需要方法进行训练。
这意味着在默认情况下,在某些领域或没有某些资源的项目是不可行的。
现在,通过迁移学习,这些瓶颈正在消除:
一、小数据集不再是决定性因素
深度学习通常需要大量的标记数据,在许多领域中,这些数据根本不存在。迁移学习可以解决这个问题。
例如,哈佛医学院下属的一个研究小组最近部署了一个模型,该模型可以“根据胸片预测长期死亡率,包括非癌症死亡”。
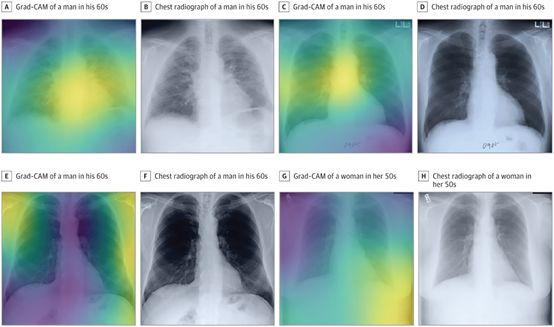
在拥有大约50000个标记图像的数据集的条件下,研究人员没有从零开始训练CNN(卷积神经网络)所需的数据。取而代之的是,他们采用一个预训练的Inception-v4模型(在拥有超过1400万张图像的ImageNet数据集上进行训练),使用迁移学习,通过轻微修改架构来使模型适应他们的数据集。
最后,他们的CNN成功地仅使用一张胸部图像为每位患者生成与患者实际死亡率相关的风险评分。
二、模型可以在几分钟内训练,而不是几天
在海量数据上训练模型不仅是获取大型数据集的问题,也是资源和时间的问题。
例如,当谷歌开发比较先进的图像分类模型exception时,他们训练两个版本:一个是ImageNet数据集(1400万张图像),另一个是JFT数据集(3.5亿张图像)。
在60 NVIDIAK80GPUs上进行各种优化的训练,运行一个ImageNet实验需要3天。JFT的实验花了一个多月的时间。
然而,现在已经发布预先训练的Xception模型,团队可以更快地微调自己的版本。
例如,伊利诺伊大学和阿贡国家实验室的一个小组最近训练了一个模型,将星系的图像分为螺旋状或椭圆形:

尽管只有35000个标记图像的数据集,他们能够在8分钟内使用NVIDIAGPUs对Xception进行微调。
当在GPU上运行时,模型能够以每分钟超20000个星系的超人速度对星系分类,准确率达99.8%。
三、你不再需要风险投资来训练模型
当在60 GPUs上训练Xception模型需要数月的时间的时候,谷歌可能不太在乎成本。然而,对于任何没有谷歌规模预算的团队来说,模型训练的价格是一个真正令人担忧的问题。
例如,当OpenAI第一次公布GPT-2的结果时,他们发布了模型架构,但由于担心误用,没有发布完整的预训练模型。
作为回应,Brown的一个团队按照本文所述的架构和训练过程复制GPT-2,并调用模型OpenGPT-2。他们花了大约5万美元去训练,但表现不如GPT-2。
如果一个模型的性能低于比较先进的水平,那么5万美元对于任何一个团队来说都是一个巨大的风险,因为他们在没有大量资金的情况下去构建真正的软件。
建造AI Dungeon时,尼克·沃尔顿通过微调GPT-2来完成项目。OpenAI已经投入大约27118520页的文本和数千美元来训练这个模型,而沃尔顿不需要重新创建任何一个。
取而代之的是,他使用从chooseyourstory.com上截取了一组小得多的文本,并在完全免费的GoogleColab中对模型进行微调。
机器学习工程正在成为一个真正的生态系统
相比软件工程,从相当标准的模式来看,人们一般认为生态系统已经“成熟”。
一种涵盖了一些极强性能的新编程语言即将出现,人们将把它用于专门的案例、研究项目和玩具上。在这个阶段,任何使用它的人都必须从头开始构建所有的基本实用程序。
接下来,这一社区中的人们开发库和项目,将公共实用程序抽离出来,直到工具能够稳定地用于生产。
在这个阶段,使用它来构建软件的工程师并不关心发送HTTP请求或连接到数据库,所有这些都被抽离出来的,工程师们只关注于构建他们的产品。
换句话说,脸书构建React,谷歌构建Angular,而工程师使用它们来构建产品。随着迁移学习的发展,机器学习工程正朝着这一方向迈进。
随着OpenAI、谷歌、脸书和其他科技巨头发布强大的开源模型,机器学习工程师的“工具”变得更加强大和稳定。
机器学习工程师们不再花时间用PyTorch或TensorFlow从头开始构建模型,而是使用开源模型和迁移学习来构建产品,这意味着全新一代的机器学习驱动软件即将面世。
现在,机器学习工程师只需要担心如何将这些模型投入生产。
深度学习不再困难。