面对现实吧,Python的速度在与C语言或Go语言相比时,的确引发了不少口水战。
这让笔者一段时间以来,一直对Python快速处理任务的能力有所怀疑。
目前,笔者尝试在Go语言中进行数据科学研究——这是有可能的——但操作起来根本不像在Python中那样令人愉快,多半是由于语言的静态特性和数据科学大多是探索性领域。
并不是说用Go语言重写完成的解决方案不能提高性能,但这是另一篇文章的主题。
迄今为止,笔者至少忽略了Python可以更快地处理任务这一能力。笔者一直饱受目光短浅之苦——这是一种表现为当你只看到一种解决方案时,完全忽视其他方案的存在的综合征。相信出现这种情况的不只笔者自己。
这就是笔者今天想简要介绍如何令Pandas每日工作速度更快且更为愉悦的原因。更准确地说,该示例将关注行之间的迭代,并在过程中执行一些数据操作。因此,事不宜迟,一起进入正题。
做一个数据集
把观点论述清楚最简单的方法是声明一个单列数据框对象,其整数值范围为1到100000:
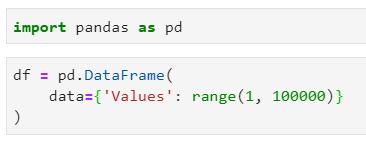
真的不需要任何更为复杂的东西来解决Pandas的速度问题。为验证一切进展顺利,以下是数据集的前几行和整体形状:

好了,准备工作已做足,现在一起看看如何遍历以及如何不遍历数据框的行。首先介绍如何不进行选择。
以下是你不应该做的事
啊,笔者一直在使用(和过度使用)如此多的iterrows()方法。它在默认情况下速度很慢,但你知道笔者费心去寻找替代方案的原因(目光短浅)。
为证明你不该使用iterrows()方法在数据框中进行遍历,笔者会做个快速演示——声明一个变量并将其初始设置为0——然后在每次迭代时按Values属性的当前值进行递增。
如果你想知道%%time魔法函数返回单元格完成所有操作所需的秒数/毫秒数。
一起看看该函数是如何运行的:
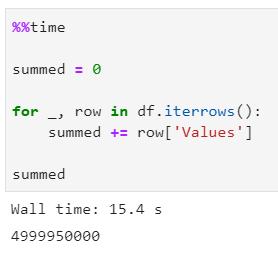
你现在可能会想,用15秒遍历100000行并递增一些外部变量的值并不算多。但事实上是——请看下一部分的阐述原因。
以下是你应该做的事
现在有一个神奇的方法能进行挽救——itertuples()。顾名思义,itertuples()循环遍历数据框的行,然后返回一个命名元组。这就是不能用括号[]访问这些值,而是需要使用.符号的原因。
现在将演示与几分钟前相同的示例,但使用的是itertuples()方法:
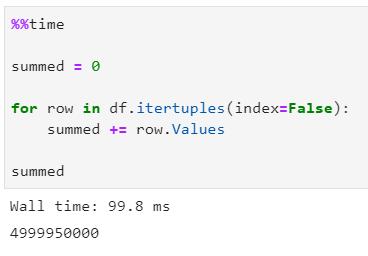
瞧瞧!使用itertuples()进行同样的运算,速度快了约154倍!现在想象一下你的日常工作场景,你正在处理上百万条行——itertuples()可以帮你节省大量时间。
在这个简单的例子中,我们已经见识到对代码进行的小小改动就能对整体结果产生的巨大影响。
这不意味itertuples()在每个场景下都会比iterrows()快150倍,但在某种程度上这确实意味着每次都会快一些。
感谢阅读,希望大家有所收获!