背景
渠道分析系统,是一个多维度数据分析系统,旨在为渠道运营和渠道评估提供数据支持。随着精细化运营需求的日益增长,对渠道数据的时效性和准确性要求也越来越高。第一代渠道分析系统,数据主要依赖离线计算产生,最小时间粒度为小时,其中,“新增用户数”对运营人员及时调整策略起到至关重要的作用,但该数据的滞后性比较明显,导致相应的运营决策比较被动,决策效果较差。
本文实现了一种实时计算与离线计算一体化的解决方案,为渠道新增数据提供实时、准确、高效的数据支撑。本文将从面临挑战、解决方案、难点攻克等几个方面来详细描述整个方案实施过程。
面临挑战
渠道数据涉及多种产品线,因此数据打点分散,数据源较多,其中包括数据中心数据、商业化数据、反作弊数据等。为了建立通用的渠道评估机制,全面的评估渠道质量从而指导结算,由此面临的挑战总结如下:
- 数据量大。渠道数据汇聚了多个产品的数据,每天数据量约为5~6TB,高峰期可达100MB/s。
- 数据复杂度高。产品的多样性使得数据源种类繁多,且原始日志经过多重加密,增加了日志解析的复杂度。
- 低延迟。渠道运营数据延迟越低,对运营决策的价值越高,而新增数据由于其依赖历史数据,其本身计算逻辑存在复杂性,增加了低延迟的处理难度。
- 数据准确性要求高。保证渠道评估的准确性才能做到精准投放和公平结算,因此对渠道数据的准确性要求较高,需要有数据校准机制。
解决方案
1. 总体设计
基于面临的挑战本文采用了实时计算分流、离线计算补充校准的方式来满足上述数据要求,以下是整体数据处理架构图。
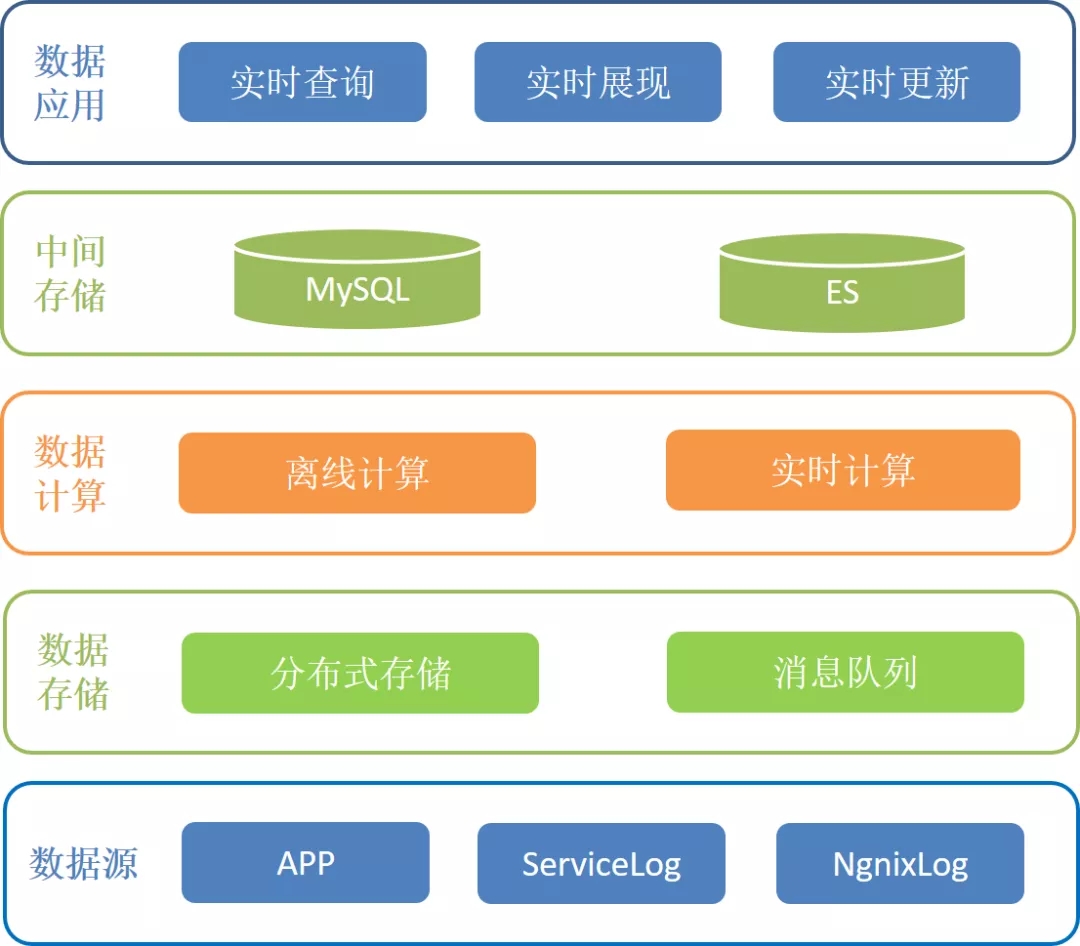
图1 架构图
从图1中可以看到,本文采用双写的方式存储原始数据:实时流式消息队列存储和分布式存储,通过实时计算分流与离线计算补充的方式来实现实时更新数据,实时查询数据和实时展现数据。
2. 具体实现
正如上文所提到的渠道分析的数据量级庞大,数据复杂度高,并且新增计算本身具有复杂性,同时需求本身在数据低延迟上的要求,在设计过程中,需要考虑:
- 实时流处理复杂数据的时间开销,比如渠道原始数据经多次加密和压缩导致解析时间开销增大;
- 实时计算引擎自身的特性,本文涉及到的是运营投放和结算,对数据统计的正确性要求较高;
- 数据指标计算的复杂性,新增数据计算严重依赖历史库的数据查询效率;
- 网络环境,当不可抗力影响了实时数据的产出,及时报警并启用离线方案校准数据。
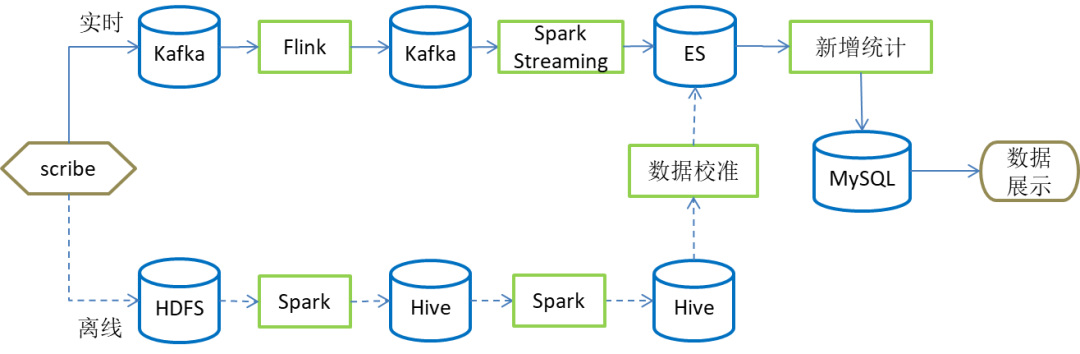
图2 数据处理流程图
从图2中可以看出,为应对大量复杂的数据,尽可能降低处理延迟,实时计算部分采用了数据分层与分流相结合的技术路线,将数据计算流程拉长,采用单功能多阶段的数据处理方式将数据处理拆分为三个阶段:日志解析,产品分流和新增计算。在实时处理部分,采用了Flink 和Spark Streaming 相结合的方式。Flink 是一种具有高吞吐、低延迟的实时离线统一的流式数据处理引擎,非常适合本文场景中第一阶段的日志解析。而Spark Streaming 是微批处理,可以将实时数据流输入的数据划分为一个个小批次数据流,保障后续新增计算中聚合操作稳定的分钟级响应。为了将计算引擎的性能发挥到最大,将新增计算的延迟降到最低,在数据存储部分,本方案采用了高性能的消息队列Kafka 和索引速度快的ES 。另外,本文还设计了离线补充校准数据的容灾方案,以确保异常情况下数据的准确性。
下面分别对日志解析,产品分流,新增计算三个处理阶段和容灾部分的数据校准作详细说明。
3. 日志解析
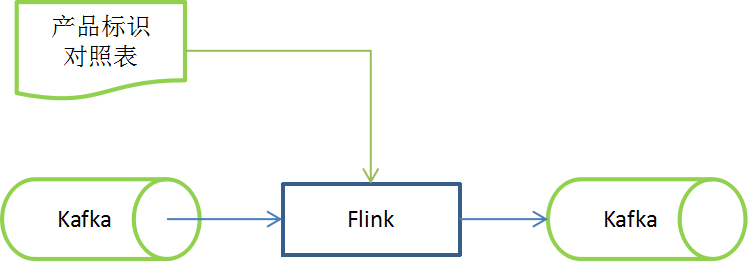
图3 日志解析图解
本阶段采用高性能消息队列Kafka 与低延迟计算引擎Flink相结合的方式进行日志解析。利用Flink的双流特性,在消费原始日志消息队列的同时会间隔一定时间同步产品标识信息,在原始日志打点规则不变的情况下,动态可配置的按需获取数据,提升了程序的可扩展性和复用性。
4. 产品分流
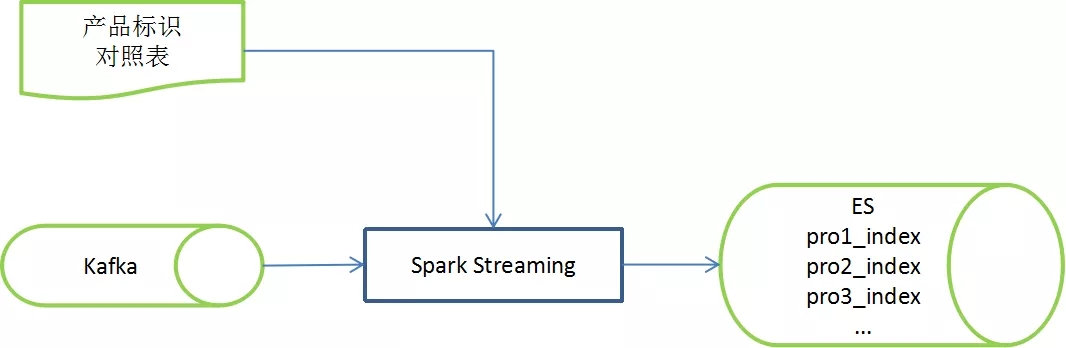
图4 产品分流图解
本阶段采用Spark Streaming和ES对合规数据进行分流。经过日志解析,数据的量级下降,此时,使用Spark Streaming可以将流式数据转换成微批处理,提高ES的更新效率。同时,利用ES 的主键唯一性,按照不同的产品标识进行数据更新。因此,ES中始终维护着一个包含所有历史记录数据的大表,即累计新增库。
5. 新增计算
本阶段利用ES自身的高性能,按照产品类别定期查询ES以达到统计小时新增和累计新增的目的。借助之前的两个阶段,日志解析和产品分流,将新增计算的响应速度从小时级降到分钟级,使得运营人员在做出决策调整投放策略后,可以在分钟级看到投放效果。
6. 容灾
容灾的主要目的是在不可抗力因素发生,影响实时数据的情况下,尽可能快的将数据补回来,尽力保证数据的准确性。我们方案实现了一套与实时功能等价的离线数据校准流程。如上图2所示,容灾过程通过离线数据处理完成主要分为两个阶段:
- 第一阶段日志解析阶段,此阶段通过离线数据处理将数据按照产品分类的方式按小时解析完成存入HIVE引擎。
- 第二阶段新增计算,通过与历史累计新增表的对比计算出新增数据。
这两个阶段是独立于实时数据处理按小时周期进行的,当发生实时数据异常时,即会触发补数流程进行补数。这个方案通过几次线上实操验证,能保证数据校准的响应维持在小时级别,数据误差率控制在0.5%以内。
方案效果
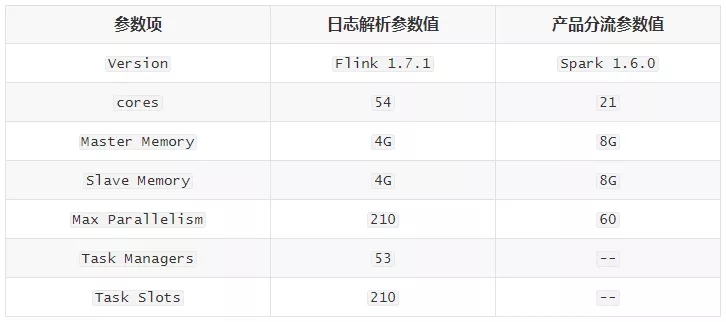
根据业务要求,渠道分析的数据延迟应控制在10分钟以内,分析本方案中各个阶段处理性能,参数配置如下:
日志解析和产品分流阶段的数据处理能力如下图所示:
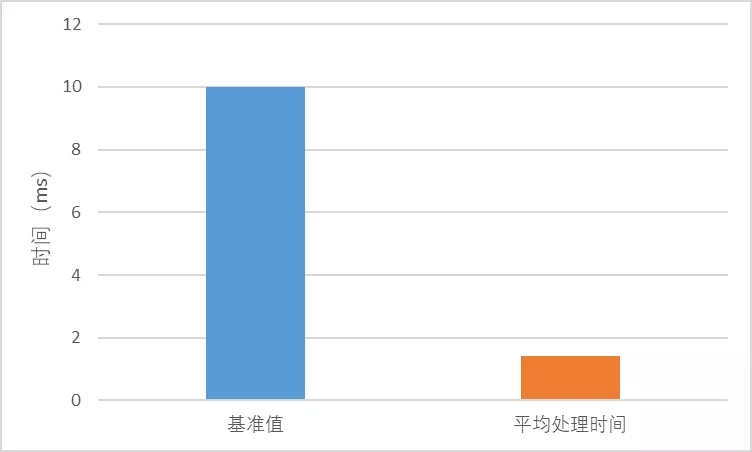
图5 日志解析处理能力统计
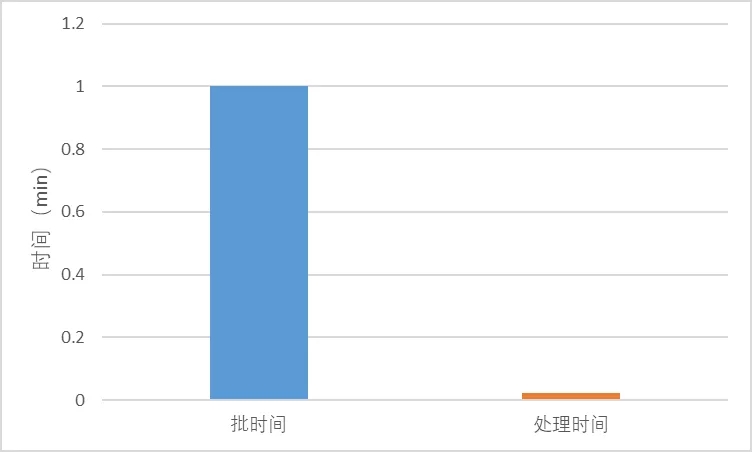
图6 产品分流处理能力统计
日志解析阶段,如上图5为一天内所有数据的平均处理时间,可以看出,单条数据处理延迟约为1.43ms,无累积延迟。产品分流阶段,如上图6为一天内所有批次的平均处理时间,可以看出,数据处理时间约为1.39s,远小于批时间,即本方案中数据消费能力远大于数据生产速度,无累积延迟。
从分析结果可知,本方案整体数据延迟控制在秒级左右,远小于业务所要求的10分钟,满足业务需求。其中新增计算与实时查询部分的延迟均为ms级别,可忽略不计。
难点攻克
1. 低延迟
渠道数据原始日志里包含众多产品,在高峰期数据量可以达到100MB/s,并且打点结构设计复杂,需要经过多重解码和结构拆分才能得到所需字段。为了保证新增计算低延迟,本方案将数据处理流程拉长,通过数据分层,将一个复杂的数据流程分解成多个处理流程。虽然拉长了数据处理流程,但可以针对性的对不同的处理阶段进行调优,例如,当日志解析阶段出现堆积,可以通过调整并行度提高执行效率。细粒度的拆分数据处理流程也提高了数据的利用率,原始数据经过日志解析,将数据变成有效的规则的明细层数据,再根据明细层数据进行分流获得不同产品的主题层数据,最终根据主题层数据计算获得应用层数据。
2. 数据准确性稳定性保障
实时处理流程配置有完善的预警和报警措施,可一旦发生极端情况,如网络或集群问题导致的实时任务失败,数据丢失不可避免。因此,本方案同时设计了一套稳定的小时级离线灾备流程,当发现实时处理出现故障,可及时开启离线补数,矫正业务数据。离线校准不仅为实时计算提供正确性校验,更保证渠道评估的准确性,为运营做到精准投放和公平结算保驾护航。
总结
本文实现了一种以实时计算为主体、离线计算为校准的分钟级累计新增计算解决方案,在原有的小时级离线新增基础上,将新增统计提升到分钟级,有效的降低了响应延迟,将运营决策被动等待转换成主动调整,为渠道运营和渠道评估提供有力的数据支持。
【本文是51CTO专栏机构360技术的原创文章,微信公众号“360技术( id: qihoo_tech)”】