主存(RAM) 是一件非常重要的资源,必须要小心对待内存。虽然目前大多数内存的增长速度要比 IBM 7094 要快的多,但是,程序大小的增长要比内存的增长还快很多。正如帕金森定律说的那样:不管存储器有多大,但是程序大小的增长速度比内存容量的增长速度要快的多。下面我们就来探讨一下操作系统是如何创建内存并管理他们的。
经过多年的探讨,人们提出了一种 分层存储器体系(memory hierarchy),下面是分层体系的分类:
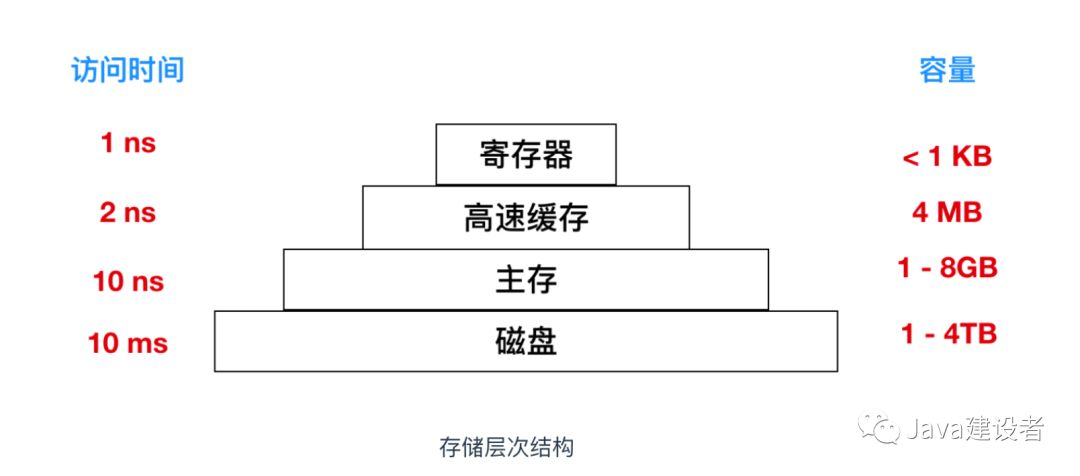
顶层的存储器速度最高,但是容量最小,成本非常高,层级结构越向下,其访问效率越慢,容量越大,但是造价也就越便宜。
操作系统中管理内存层次结构的部分称为内存管理器(memory manager),它的主要工作是有效的管理内存,记录哪些内存是正在使用的,在进程需要时分配内存以及在进程完成时回收内存。
下面我们会对不同的内存管理模型进行探讨,从简单到复杂,由于最低级别的缓存是由硬件进行管理的,所以我们主要探讨主存模型和如何对主存进行管理。
无存储器抽象
最简单的存储器抽象是没有存储。早期大型计算机(20 世纪 60 年代之前),小型计算机(20 世纪 70 年代之前)和个人计算机(20 世纪 80 年代之前)都没有存储器抽象。每一个程序都直接访问物理内存。当一个程序执行如下命令:
- MOV REGISTER1, 1000
计算机会把位置为 1000 的物理内存中的内容移到 REGISTER1 中。因此,那时呈现给程序员的内存模型就是物理内存,内存地址从 0 开始到内存地址的最大值中,每个地址中都会包含一个 8 位位数的单元。
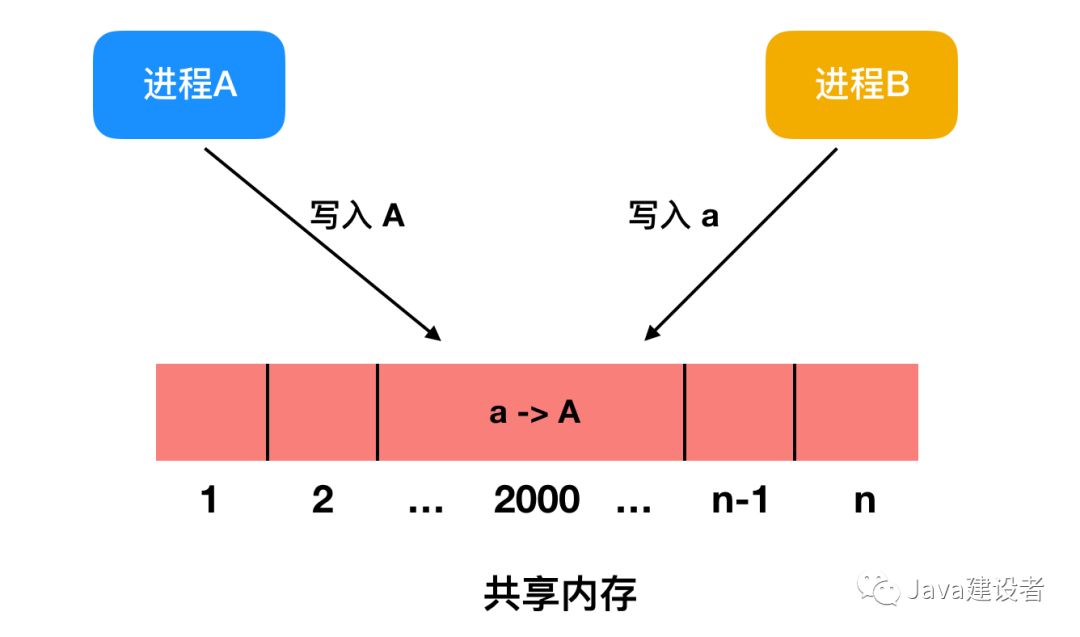
所以这种情况下的计算机不可能会有两个应用程序同时在内存中。如果第一个程序向内存地址 2000 的这个位置写入了一个值,那么此值将会替换第二个程序在该位置上的值,所以,同时运行两个应用程序是行不通的,两个程序会立刻崩溃。
不过即使存储器模型就是物理内存,还是存在一些可选项的。下面展示了三种变体: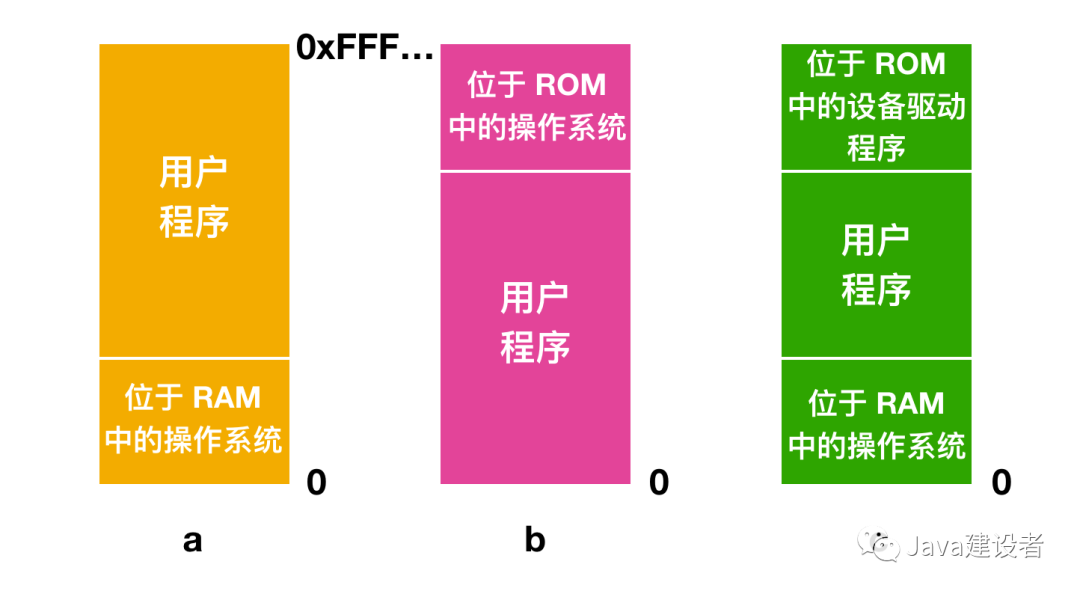
在上图 a 中,操作系统位于 RAM(Random Access Memory) 的底部,或像是图 b 一样位于 ROM(Read-Only Memory) 顶部;而在图 c 中,设备驱动程序位于顶端的 ROM 中,而操作系统位于底部的 RAM 中。图 a 的模型以前用在大型机和小型机上,但现在已经很少使用了;图 b 中的模型一般用于掌上电脑或者是嵌入式系统中。第三种模型就应用在早期个人计算机中了。ROM 系统中的一部分成为 BIOS (Basic Input Output System)。模型 a 和 c 的缺点是用户程序中的错误可能会破坏操作系统,可能会导致灾难性的后果。
按照这种方式组织系统时,通常同一个时刻只能有一个线程正在运行。一旦用户键入了一个命令,操作系统就把需要的程序从磁盘复制到内存中并执行;当进程运行结束后,操作系统在用户终端显示提示符并等待新的命令。收到新的命令后,它把新的程序装入内存,覆盖前一个程序。
在没有存储器抽象的系统中实现并行性的一种方式是使用多线程来编程。由于同一进程中的多线程内部共享同一内存映像,那么实现并行也就不是问题了。
运行多个程序
但是,即便没有存储器抽象,同时运行多个程序也是有可能的。操作系统只需要把当前内存中所有内容保存到磁盘文件中,然后再把程序读入内存即可。只要某一时间只有一个程序,那么就不会产生冲突。
在额外特殊硬件的帮助下,即使没有交换功能,也可以并行的运行多个程序。IBM 360 的早期模型就是这样解决的
System/360是 IBM 在1964年4月7日,推出的划时代的大型电脑,这一系列是世界上首个指令集可兼容计算机。
在 IBM 360 中,内存被划分为 2KB 的区域块,每块区域被分配一个 4 位的保护键,保护键存储在 CPU 的特殊寄存器中。一个内存为 1 MB 的机器只需要 512 个这样的 4 位寄存器,容量总共为 256 字节 (这个会算吧。) PSW(Program Status Word, 程序状态字) 中有一个 4 位码。一个运行中的进程如果访问键与其 PSW 码不同的内存,360 硬件会发现这种情况,因为只有操作系统可以修改保护键,这样就可以防止进程之间、用户进程和操作系统之间的干扰。
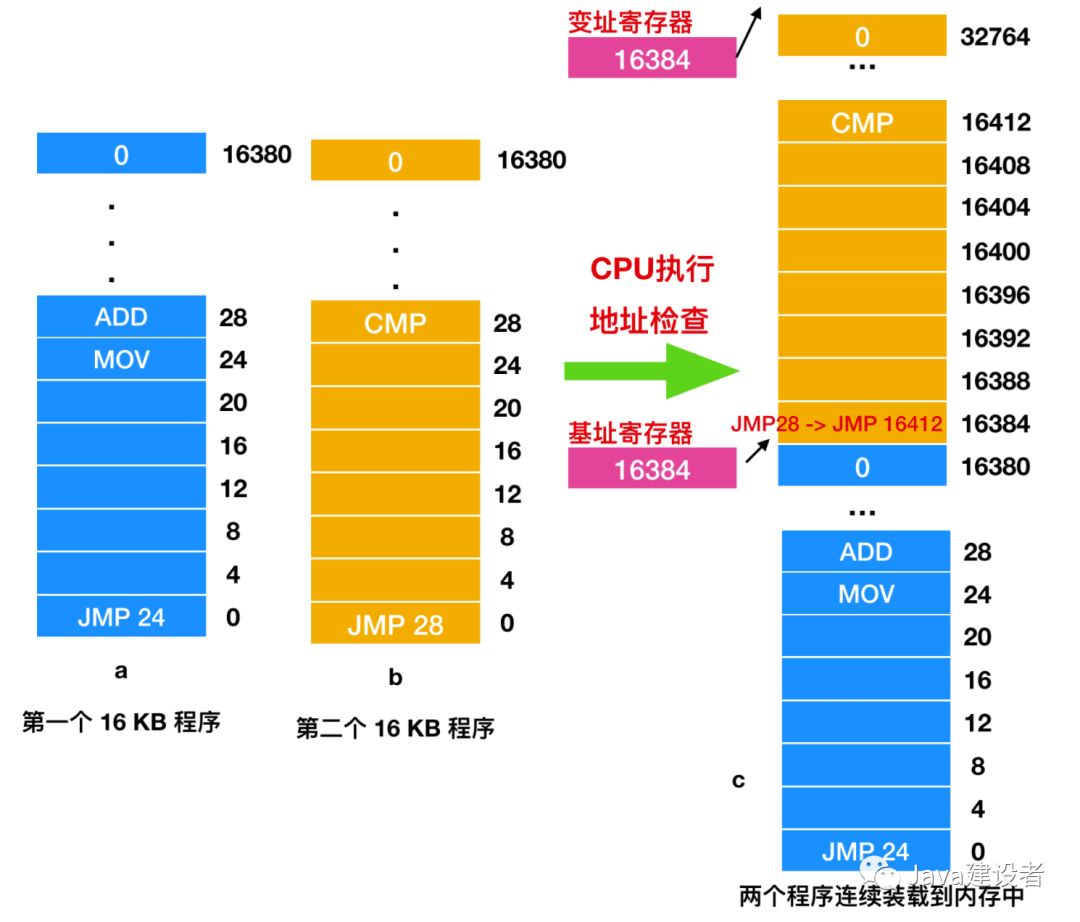
这种解决方式是有一个缺陷。如下所示,假设有两个程序,每个大小各为 16 KB。

从图上可以看出,这是两个不同的 16KB 程序的装载过程,a 程序首先会跳转到地址 24,那里是一条 MOV 指令,然而 b 程序会首先跳转到地址 28,地址 28 是一条 CMP 指令。这是两个程序被先后加载到内存中的情形,假如这两个程序被同时加载到内存中从 0 地址处开始执行,内存的状态就如上面 c 图所示,程序装载完毕开始运行,第一个程序首先从 0 地址处开始运行,执行 JMP 24 指令,然后依次执行后面的指令(许多指令没有画出),一段时间后第一个程序执行完毕,然后开始执行第二个程序。第二个程序的第一条指令是 28,这条指令会使程序跳转到第一个程序的 ADD 处,而不是事先设定的跳转指令 CMP,由于内存地址的不正确访问,这个程序可能在 1秒内就崩溃了。
上面两个程序同时执行最核心的问题是都引用了绝对物理地址。这不是我们想要看到的。我们想要的是每一个程序都会引用一个私有的本地地址。IBM 360 在第二个程序装载到内存中的时候会使用一种称为 静态重定位(static relocation) 的技术来修改它。它的工作流程如下:当一个程序被加载到 16384 地址时,常数 16384 被加到每一个程序地址上(所以 JMP 28会变为JMP 16412 )。虽然这个机制在不出错误的情况下是可行的,但这不是一种通用的解决办法,同时会减慢装载速度。更近一步来讲,它需要所有可执行程序中的额外信息,以指示哪些包含(可重定位)地址,哪些不包含(可重定位)地址。毕竟,上图 b 中的 JMP 28 可以被重定向(被修改),而类似 MOV REGISTER1,28 会把数字 28 移到 REGISTER 中则不会重定向。所以,装载器(loader)需要一定的能力来辨别地址和常数。
一种存储器抽象:地址空间
把物理内存暴露给进程会有几个主要的缺点:第一个问题是,如果用户程序可以寻址内存的每个字节,它们就可以很容易的破坏操作系统,从而使系统停止运行(除非使用 IBM 360 那种 lock-and-key 模式或者特殊的硬件进行保护)。即使在只有一个用户进程运行的情况下,这个问题也存在。
第二点是,这种模型想要运行多个程序是很困难的(如果只有一个 CPU 那就是顺序执行),在个人计算机上,一般会打开很多应用程序,比如输入法、电子邮件、浏览器,这些进程在不同时刻会有一个进程正在运行,其他应用程序可以通过鼠标来唤醒。在系统中没有物理内存的情况下很难实现。
地址空间的概念
如果要使多个应用程序同时运行在内存中,必须要解决两个问题:保护和 重定位。我们来看 IBM 360 是如何解决的:第一种解决方式是用保护密钥标记内存块,并将执行过程的密钥与提取的每个存储字的密钥进行比较。这种方式只能解决第一种问题,但是还是不能解决多进程在内存中同时运行的问题。
还有一种更好的方式是创造一个存储器抽象:地址空间(the address space)。就像进程的概念创建了一种抽象的 CPU 来运行程序,地址空间也创建了一种抽象内存供程序使用。地址空间是进程可以用来寻址内存的地址集。每个进程都有它自己的地址空间,独立于其他进程的地址空间,但是某些进程会希望可以共享地址空间。
基址寄存器和变址寄存器
最简单的办法是使用动态重定位(dynamic relocation),它就是通过一种简单的方式将每个进程的地址空间映射到物理内存的不同区域。从 CDC 6600(世界上最早的超级计算机)到 Intel 8088(原始 IBM PC 的核心)所使用的经典办法是给每个 CPU 配置两个特殊硬件寄存器,通常叫做基址寄存器(basic register)和变址寄存器(limit register)。当使用基址寄存器和变址寄存器时,程序会装载到内存中连续的空间位置并且在装载期间无需重定位。当一个进程运行时,程序的起始物理地址装载到基址寄存器中,程序的长度则装载到变址寄存器中。在上图 c 中,当一个程序运行时,装载到这些硬件寄存器中的基址和变址寄存器的值分别是 0 和 16384。当第二个程序运行时,这些值分别是 16384 和 32768。如果第三个 16 KB 的程序直接装载到第二个程序的地址之上并且运行,这时基址寄存器和变址寄存器的值会是 32768 和 16384。那么我们可以总结下
- 基址寄存器:存储数据内存的起始位置
- 变址寄存器:存储应用程序的长度。
每当进程引用内存以获取指令或读取或写入数据字时,CPU 硬件都会自动将基址值添加到进程生成的地址中,然后再将其发送到内存总线上。同时,它检查程序提供的地址是否等于或大于变址寄存器 中的值。如果程序提供的地址要超过变址寄存器的范围,那么会产生错误并中止访问。这样,对上图 c 中执行 JMP 28 这条指令后,硬件会把它解释为 JMP 16412,所以程序能够跳到 CMP 指令,过程如下:
使用基址寄存器和变址寄存器是给每个进程提供私有地址空间的一种非常好的方法,因为每个内存地址在送到内存之前,都会先加上基址寄存器的内容。在很多实际系统中,对基址寄存器和变址寄存器都会以一定的方式加以保护,使得只有操作系统可以修改它们。在 CDC 6600 中就提供了对这些寄存器的保护,但在 Intel 8088 中则没有,甚至没有变址寄存器。但是,Intel 8088 提供了许多基址寄存器,使程序的代码和数据可以被独立的重定位,但是对于超出范围的内存引用没有提供保护。
所以你可以知道使用基址寄存器和变址寄存器的缺点,在每次访问内存时,都会进行 ADD 和 CMP 运算。比较可以执行的很快,但是加法就会相对慢一些,除非使用特殊的加法电路,否则加法因进位传播时间而变慢。
交换技术
如果计算机的物理内存足够大来容纳所有的进程,那么之前提及的方案或多或少是可行的。但是实际上,所有进程需要的 RAM 总容量要远远高于内存的容量。在 Windows、OS X、或者 Linux 系统中,在计算机完成启动(Boot)后,大约有 50 - 100 个进程随之启动。例如,当一个 Windows 应用程序被安装后,它通常会发出命令,以便在后续系统启动时,将启动一个进程,这个进程除了检查应用程序的更新外不做任何操作。一个简单的应用程序可能会占用 5 - 10MB 的内存。其他后台进程会检查电子邮件、网络连接以及许多其他诸如此类的任务。这一切都会发生在第一个用户启动之前。如今,像是 Photoshop 这样的重要用户应用程序仅仅需要 500 MB 来启动,但是一旦它们开始处理数据就需要许多 GB 来处理。从结果上来看,将所有进程始终保持在内存中需要大量内存,如果内存不足,则无法完成。
所以针对上面内存不足的问题,提出了两种处理方式:最简单的一种方式就是交换(swapping)技术,即把一个进程完整的调入内存,然后再内存中运行一段时间,再把它放回磁盘。空闲进程会存储在磁盘中,所以这些进程在没有运行时不会占用太多内存。另外一种策略叫做虚拟内存(virtual memory),虚拟内存技术能够允许应用程序部分的运行在内存中。下面我们首先先探讨一下交换
交换过程
下面是一个交换过程:
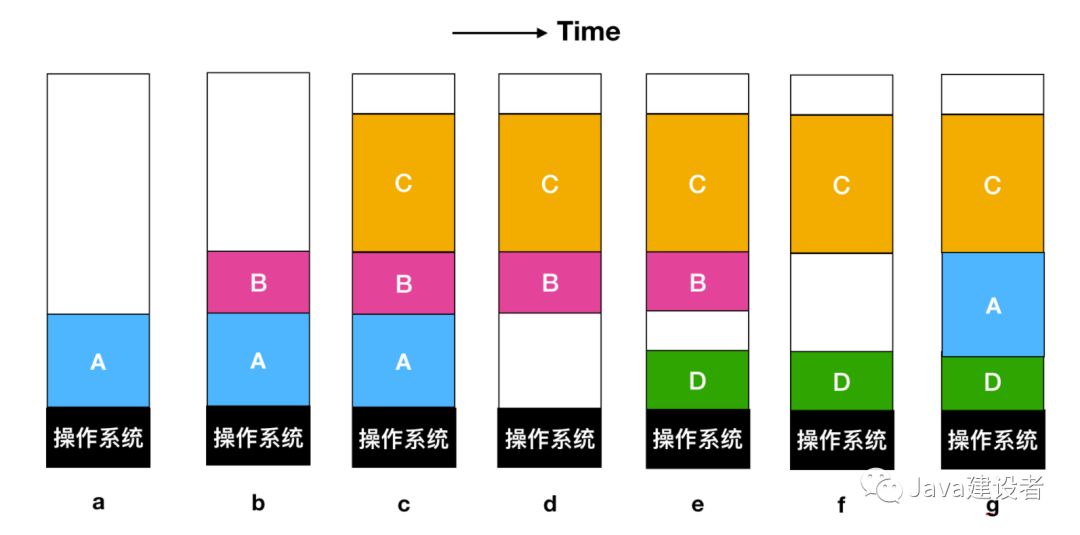
刚开始的时候,只有进程 A 在内存中,然后从创建进程 B 和进程 C 或者从磁盘中把它们换入内存,然后在图 d 中,A 被换出内存到磁盘中,最后 A 重新进来。因为图 g 中的进程 A 现在到了不同的位置,所以在装载过程中需要被重新定位,或者在交换程序时通过软件来执行;或者在程序执行期间通过硬件来重定位。基址寄存器和变址寄存器就适用于这种情况。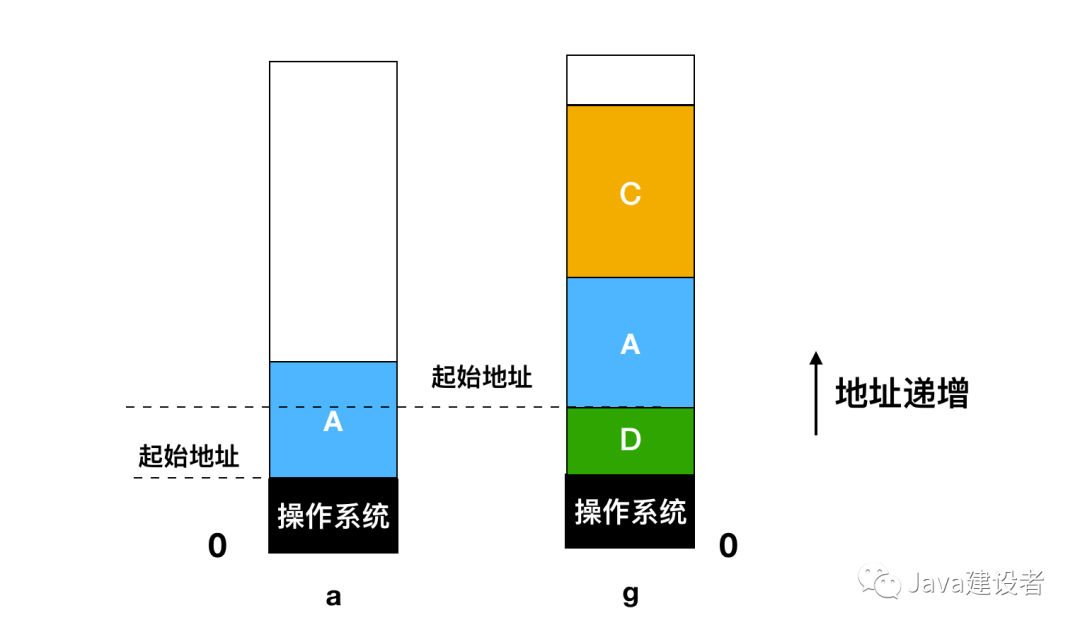
交换在内存创建了多个 空闲区(hole),内存会把所有的空闲区尽可能向下移动合并成为一个大的空闲区。这项技术称为内存紧缩(memory compaction)。但是这项技术通常不会使用,因为这项技术会消耗很多 CPU 时间。例如,在一个 16GB 内存的机器上每 8ns 复制 8 字节,它紧缩全部的内存大约要花费 16s。
有一个值得注意的问题是,当进程被创建或者换入内存时应该为它分配多大的内存。如果进程被创建后它的大小是固定的并且不再改变,那么分配策略就比较简单:操作系统会准确的按其需要的大小进行分配。
但是如果进程的 data segment 能够自动增长,例如,通过动态分配堆中的内存,肯定会出现问题。这里还是再提一下什么是 data segment 吧。从逻辑层面操作系统把数据分成不同的段(不同的区域)来存储:
- 代码段(codesegment/textsegment):
又称文本段,用来存放指令,运行代码的一块内存空间
此空间大小在代码运行前就已经确定
内存空间一般属于只读,某些架构的代码也允许可写
在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
- 数据段(datasegment):
可读可写
存储初始化的全局变量和初始化的 static 变量
数据段中数据的生存期是随程序持续性(随进程持续性)
随进程持续性:进程创建就存在,进程死亡就消失
- bss段(bsssegment):
可读可写
存储未初始化的全局变量和未初始化的 static 变量
bss 段中数据的生存期随进程持续性
bss 段中的数据一般默认为0
- rodata段:
只读数据
比如 printf 语句中的格式字符串和开关语句的跳转表。也就是常量区。例如,全局作用域中的 const int ival = 10,ival 存放在 .rodata 段;再如,函数局部作用域中的 printf("Hello world %d\n", c); 语句中的格式字符串 "Hello world %d\n",也存放在 .rodata 段。
- 栈(stack):
可读可写
存储的是函数或代码中的局部变量(非 static 变量)
栈的生存期随代码块持续性,代码块运行就给你分配空间,代码块结束,就自动回收空间
- 堆(heap):
可读可写
存储的是程序运行期间动态分配的 malloc/realloc 的空间
堆的生存期随进程持续性,从 malloc/realloc 到 free 一直存在
下面是我们用 Borland C++ 编译过后的结果:
- _TEXT segment dword public use32 'CODE'
- _TEXT ends
- _DATA segment dword public use32 'DATA'
- _DATA ends
- _BSS segment dword public use32 'BSS'
- _BSS ends
段定义( segment ) 是用来区分或者划分范围区域的意思。汇编语言的 segment 伪指令表示段定义的起始,ends 伪指令表示段定义的结束。段定义是一段连续的内存空间
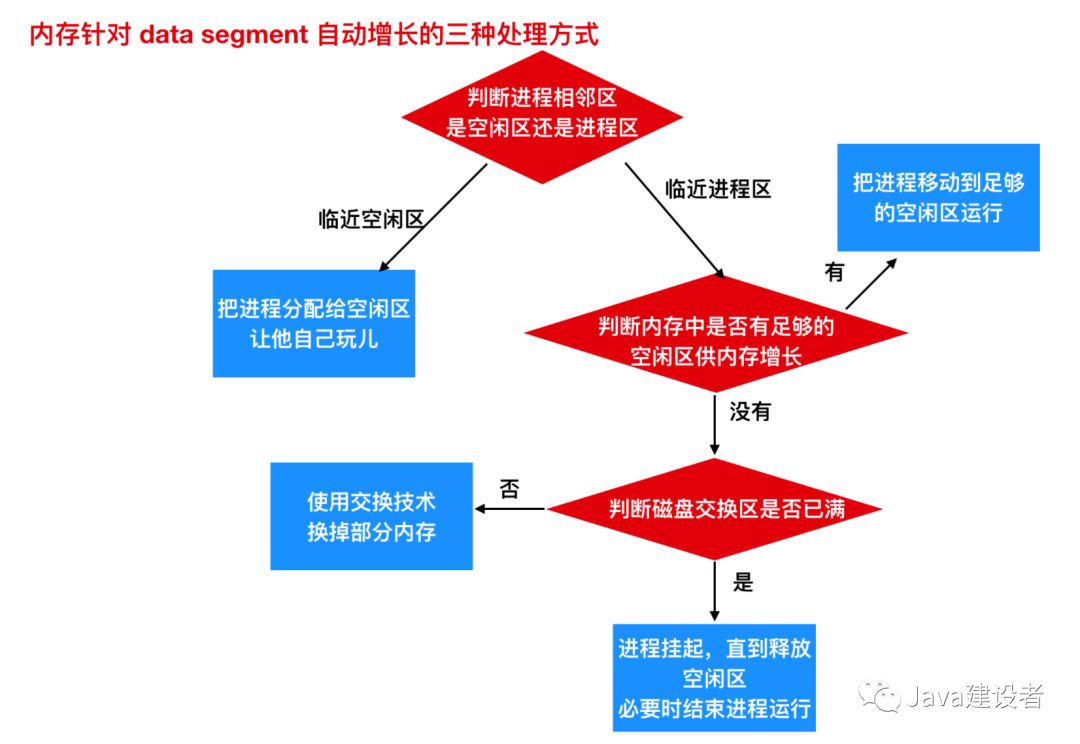
所以内存针对自动增长的区域,会有三种处理方式
- 如果一个进程与空闲区相邻,那么可把该空闲区分配给进程以供其增大。
- 如果进程相邻的是另一个进程,就会有两种处理方式:要么把需要增长的进程移动到一个内存中空闲区足够大的区域,要么把一个或多个进程交换出去,已变成生成一个大的空闲区。
- 如果一个进程在内存中不能增长,而且磁盘上的交换区也满了,那么这个进程只有挂起一些空闲空间(或者可以结束该进程)
上面只针对单个或者一小部分需要增长的进程采用的方式,如果大部分进程都要在运行时增长,为了减少因内存区域不够而引起的进程交换和移动所产生的开销,一种可用的方法是,在换入或移动进程时为它分配一些额外的内存。然而,当进程被换出到磁盘上时,应该只交换实际上使用的内存,将额外的内存交换也是一种浪费,下面是一种为两个进程分配了增长空间的内存配置。
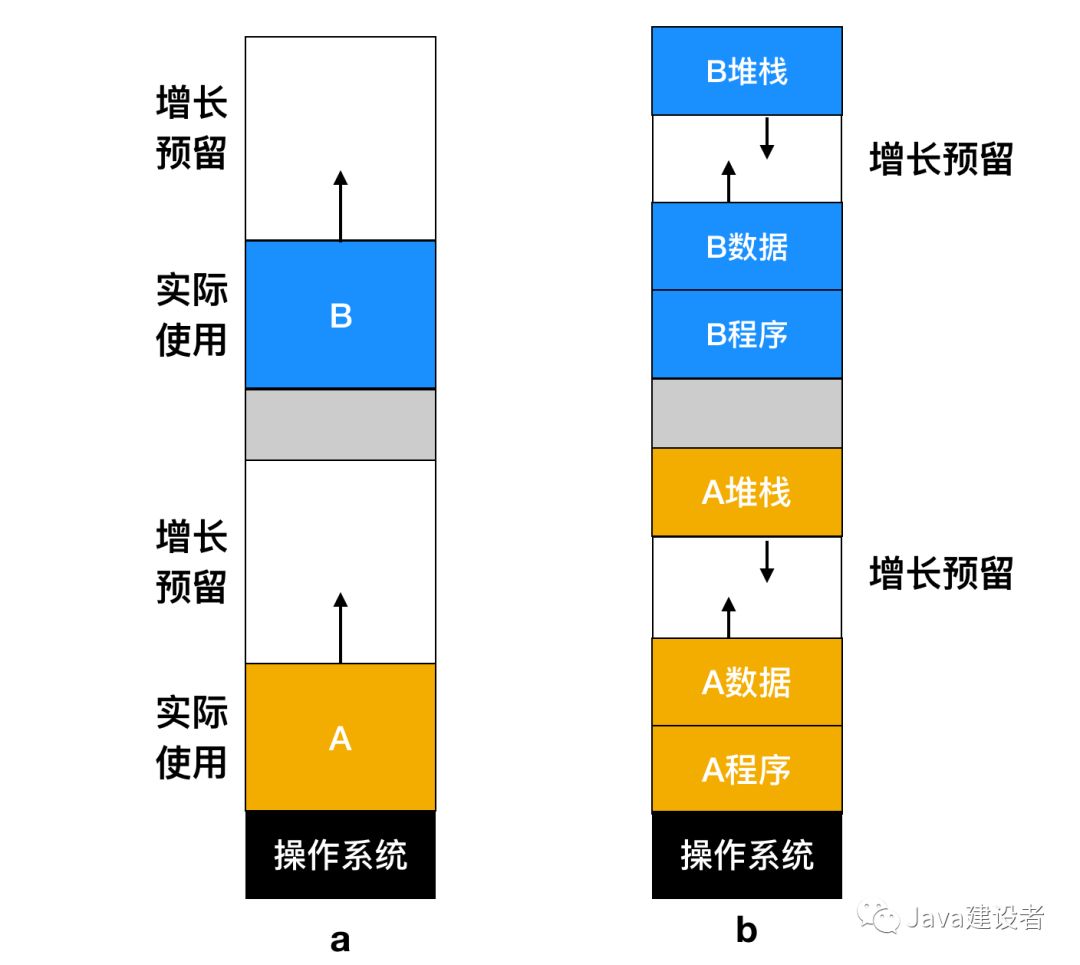
如果进程有两个可增长的段,例如,供变量动态分配和释放的作为堆(全局变量)使用的一个数据段(data segment),以及存放局部变量与返回地址的一个堆栈段(stack segment),就如图 b 所示。在图中可以看到所示进程的堆栈段在进程所占内存的顶端向下增长,紧接着在程序段后的数据段向上增长。当增长预留的内存区域不够了,处理方式就如上面的流程图(data segment 自动增长的三种处理方式)一样了。
空闲内存管理
在进行内存动态分配时,操作系统必须对其进行管理。大致上说,有两种监控内存使用的方式:
- 位图(bitmap)
- 空闲列表(free lists)
下面我们就来探讨一下这两种使用方式:
使用位图的存储管理
使用位图方法时,内存可能被划分为小到几个字或大到几千字节的分配单元。每个分配单元对应于位图中的一位,0 表示空闲, 1 表示占用(或者相反)。一块内存区域和其对应的位图如下:
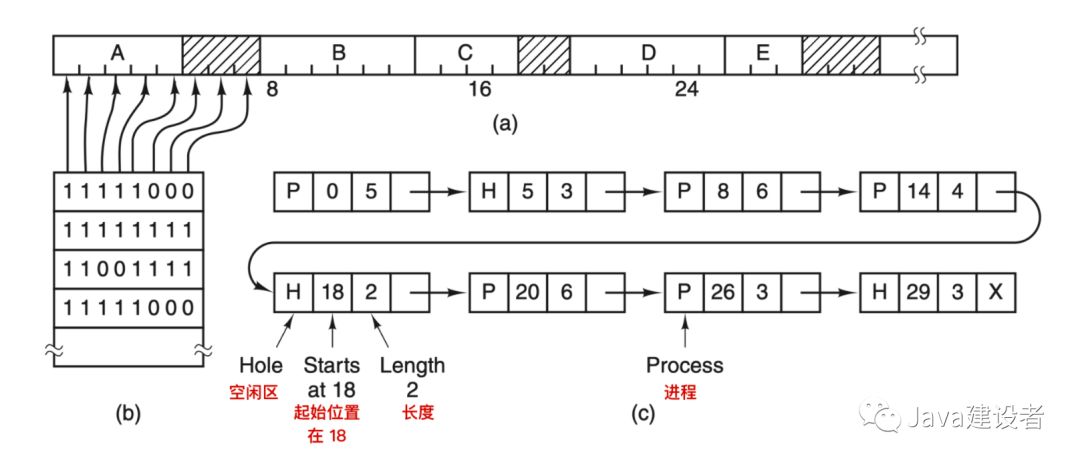
图 a 表示一段有 5 个进程和 3 个空闲区的内存,刻度为内存分配单元,阴影区表示空闲(在位图中用 0 表示);图 b 表示对应的位图;图 c 表示用链表表示同样的信息。
分配单元的大小是一个重要的设计因素,分配单位越小,位图越大。然而,即使只有 4 字节的分配单元,32 位的内存也仅仅只需要位图中的 1 位。32n 位的内存需要 n 位的位图,所以1 个位图只占用了 1/32 的内存。如果选择更大的内存单元,位图应该要更小。如果进程的大小不是分配单元的整数倍,那么在最后一个分配单元中会有大量的内存被浪费。
位图提供了一种简单的方法在固定大小的内存中跟踪内存的使用情况,因为位图的大小取决于内存和分配单元的大小。这种方法有一个问题是,当决定把具有 k 个分配单元的进程放入内存时,内容管理器(memory manager) 必须搜索位图,在位图中找出能够运行 k 个连续 0 位的串。在位图中找出制定长度的连续 0 串是一个很耗时的操作,这是位图的缺点。(可以简单理解为在杂乱无章的数组中,找出具有一大长串空闲的数组单元)
使用链表进行管理
另一种记录内存使用情况的方法是,维护一个记录已分配内存段和空闲内存段的链表,段会包含进程或者是两个进程的空闲区域。可用上面的图 c 来表示内存的使用情况。链表中的每一项都可以代表一个 空闲区(H) 或者是进程(P)的起始标志,长度和下一个链表项的位置。
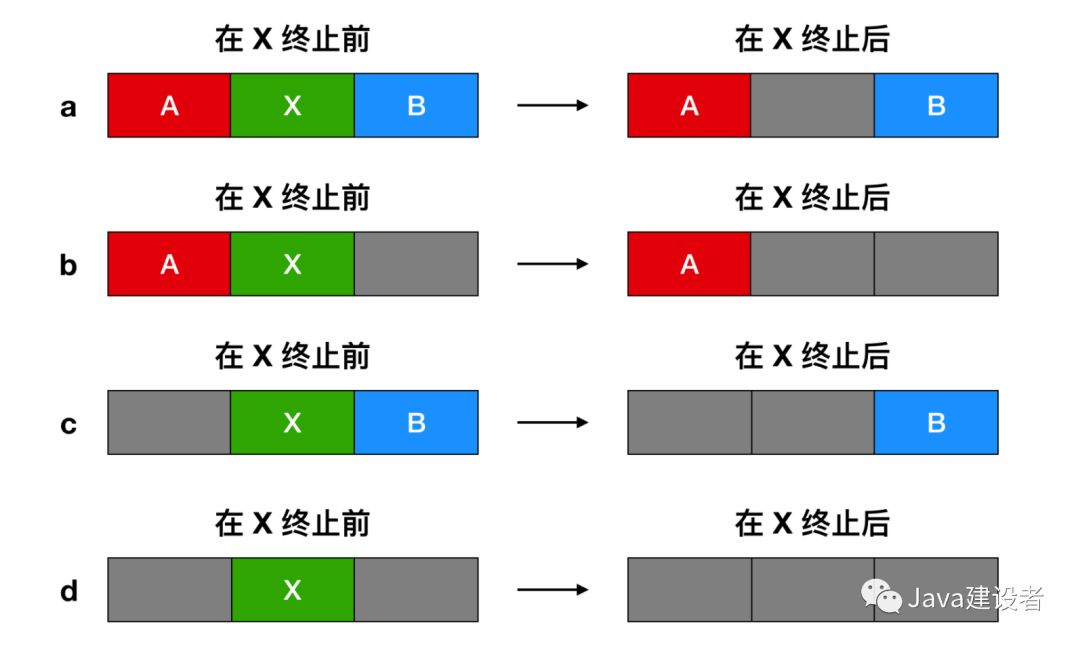
在这个例子中,段链表(segment list)是按照地址排序的。这种方式的优点是,当进程终止或被交换时,更新列表很简单。一个终止进程通常有两个邻居(除了内存的顶部和底部外)。相邻的可能是进程也可能是空闲区,它们有四种组合方式。
当按照地址顺序在链表中存放进程和空闲区时,有几种算法可以为创建的进程(或者从磁盘中换入的进程)分配内存。我们先假设内存管理器知道应该分配多少内存,最简单的算法是使用 首次适配(first fit)。内存管理器会沿着段列表进行扫描,直到找个一个足够大的空闲区为止。除非空闲区大小和要分配的空间大小一样,否则将空闲区分为两部分,一部分供进程使用;一部分生成新的空闲区。首次适配算法是一种速度很快的算法,因为它会尽可能的搜索链表。
首次适配的一个小的变体是 下次适配(next fit)。它和首次匹配的工作方式相同,只有一个不同之处那就是下次适配在每次找到合适的空闲区时就会记录当时的位置,以便下次寻找空闲区时从上次结束的地方开始搜索,而不是像首次匹配算法那样每次都会从头开始搜索。Bays(1997) 证明了下次算法的性能略低于首次匹配算法。
另外一个著名的并且广泛使用的算法是 最佳适配(best fit)。最佳适配会从头到尾寻找整个链表,找出能够容纳进程的最小空闲区。最佳适配算法会试图找出最接近实际需要的空闲区,以最好的匹配请求和可用空闲区,而不是先一次拆分一个以后可能会用到的大的空闲区。比如现在我们需要一个大小为 2 的块,那么首次匹配算法会把这个块分配在位置 5 的空闲区,而最佳适配算法会把该块分配在位置为 18 的空闲区,如下
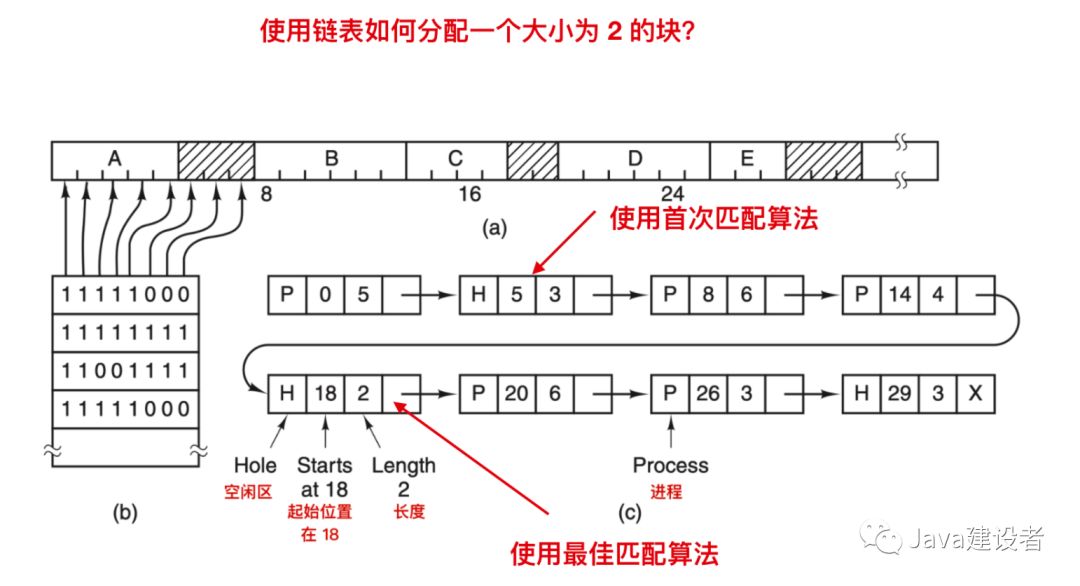
那么最佳适配算法的性能如何呢?优秀适配会遍历整个链表,所以最佳适配算法的性能要比首次匹配算法差。但是令人想不到的是,最佳适配算法要比首次匹配和下次匹配算法浪费更多的内存,因为它会产生大量无用的小缓冲区,首次匹配算法生成的空闲区会更大一些。
最佳适配的空闲区会分裂出很多非常小的缓冲区,为了避免这一问题,可以考虑使用 最差适配(worst fit) 算法。即总是分配比较大的内存区域(所以你现在明白为什么最佳适配算法会分裂出很多小缓冲区了吧),使新分配的空闲区比较大从而可以继续使用。仿真程序表明最差适配算法也不是一个好主意。
如果为进程和空闲区维护各自独立的链表,那么这四个算法的速度都能得到提高。这样,这四种算法的目标都是为了检查空闲区而不是进程。但这种分配速度的提高的一个不可避免的代价是增加复杂度和减慢内存释放速度,因为必须将一个回收的段从进程链表中删除并插入空闲链表区。
如果进程和空闲区使用不同的链表,那么可以按照大小对空闲区链表排序,以便提高优秀适配算法的速度。在使用优秀适配算法搜索由小到大排列的空闲区链表时,只要找到一个合适的空闲区,则这个空闲区就是能容纳这个作业的最小空闲区,因此是最佳匹配。因为空闲区链表以单链表形式组织,所以不需要进一步搜索。空闲区链表按大小排序时,首次适配算法与最佳适配算法一样快,而下次适配算法在这里毫无意义。
另一种分配算法是 快速适配(quick fit) 算法,它为那些常用大小的空闲区维护单独的链表。例如,有一个 n 项的表,该表的第一项是指向大小为 4 KB 的空闲区链表表头指针,第二项是指向大小为 8 KB 的空闲区链表表头指针,第三项是指向大小为 12 KB 的空闲区链表表头指针,以此类推。比如 21 KB 这样的空闲区既可以放在 20 KB 的链表中,也可以放在一个专门存放大小比较特别的空闲区链表中。
快速匹配算法寻找一个指定代销的空闲区也是十分快速的,但它和所有将空闲区按大小排序的方案一样,都有一个共同的缺点,即在一个进程终止或被换出时,寻找它的相邻块并查看是否可以合并的过程都是非常耗时的。如果不进行合并,内存将会很快分裂出大量进程无法利用的小空闲区。