引言:
系统一旦跑起来,我们就希望它能够稳定运行,不要宕机,不出现速度变慢。因此,对于Linux 系统管理员来说每天监控和调试 Linux 系统的性能问题是一项繁重却又重要的工作。监控和保持系统启动并运行是很不容易的一件事。

下面是小编总结的十个实用的 Linux 系统监控命令,让你轻松保持系统的实时性能监控。
uptime命令
uptime命令可以查看系统总共运行了多长时间和系统的平均负载。
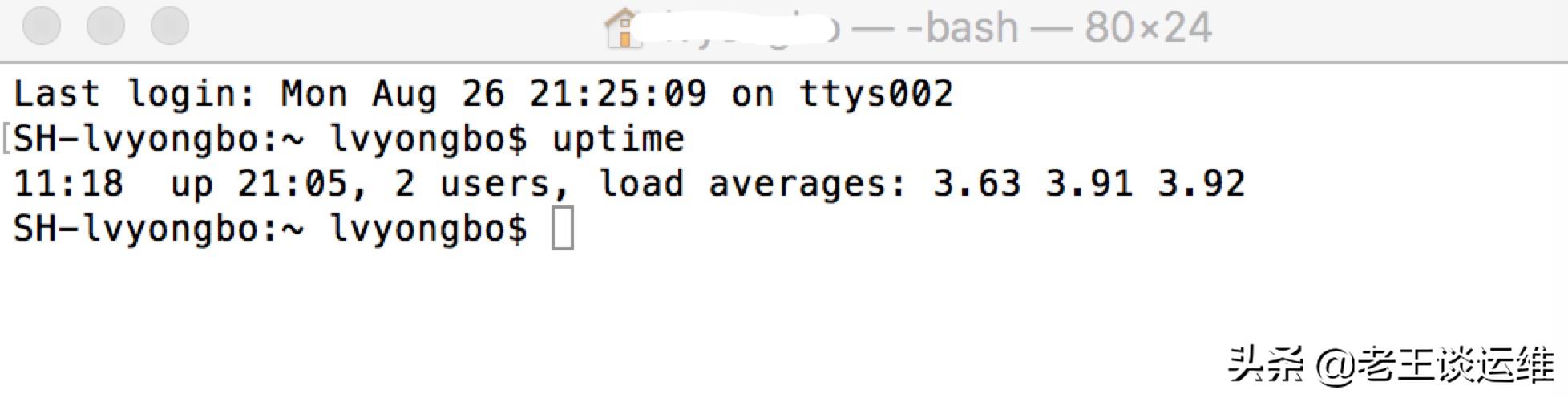
显示的信息显示依次为:
- 现在时间、
- 系统已经运行了多长时间
- 目前有多少登陆用户
- 系统在过去的1分钟、5分钟和15分钟内的平均负载
通过这些数据我们可以清晰的看出来服务器的负载是在趋于紧张还是趋于缓解的状态。
vmstat 命令
vmstat命令的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O等系统整体运行状态。

每2秒获取一次数据
#>vmstat 2
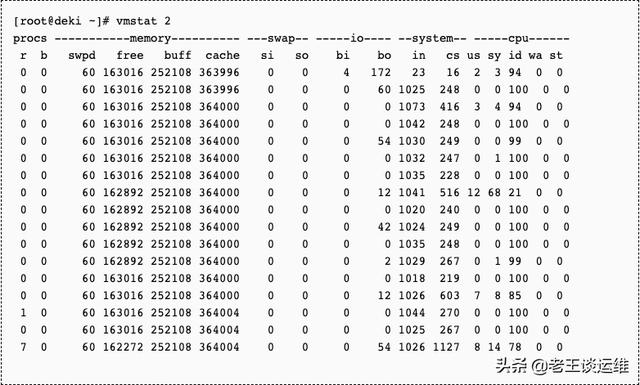
上图中,我们可以看出来vmstat命令,会输出系统的核心指标,我们可以更加详细的了解服务器的性能情况。
pidstat 命令
pidstat命令用来监控被 Linux 内核管理的独立任务(进程)。它输出每个受内核管理的任务的相关信息。pidstat命令也可以用来监控特定进程的子进程。间隔参数用于指定每次报告间的时间间隔。
使用pidstat不加任何参数等价于加上-p参数,但是只有正在活动的任务会被显示出来。
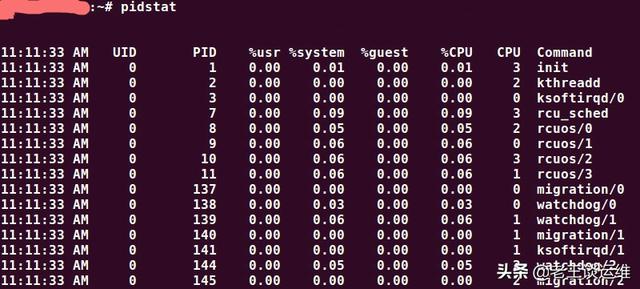
I/O 统计数据
- # pidstat -d -p 8472

IO 输出会显示一些内的条目:
- kB_rd/s - 任务从硬盘上的读取速度(kb)
- kB_wr/s - 任务向硬盘中的写入速度(kb)
- kB_ccwr/s - 任务写入磁盘被取消的速率(kb)
监测内存使用
- # pidstat -r 2 5
会显示5份关于page faults的统计数据结果,间隔2秒。这将会更容易的定位出现问题的进程。
free -m 命令
free -m 命令相对于top 提供了更简洁的查看系统内存使用情况

第一部分Mem行:
- total 内存总数: 378M
- used 已经使用的内存数: 163M
- free 空闲的内存数: 215M
- shared 当前已经废弃不用,总是0
- buffers Buffer 缓存内存数: 11M
- cached Page 缓存内存数:57M
可用内存计算公式:
可用内存 =free +buffers +cached, 实际操作即:215 +11+57 =253MB;
top 命令
top命令很常用,在第三行有显示CPU当前的使用情况。
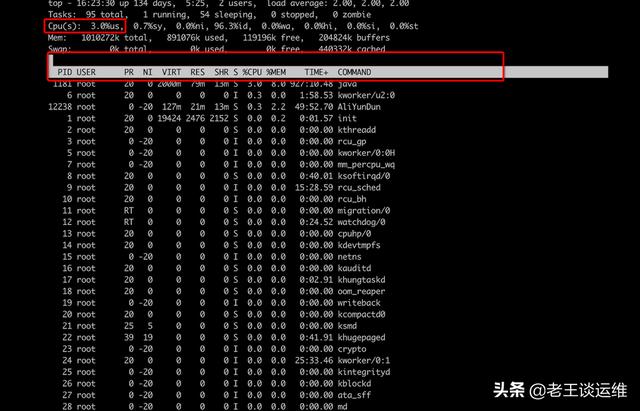
字段说明:
- PID:进程标示号
- USER:进程所有者
- PR:进程优先级
- NI:进程优先级别数值
- VIRT:进程占用的虚拟内存值
- RES:进程占用的物理内存值
- SHR :进程使用的共享内存值
- S :进程的状态,其中S表示休眠,R表示正在运行,Z表示僵死
- %CPU :进程占用的CPU使用率
- %MEM :进程占用的物理内存百分比
- TIME+:进程启动后占用的总的CPU时间
- Command:进程启动的启动命令名称
其他指令
「sar -n DEV 1」可以查看网络设备的吞吐率,吞吐量可以判断是被是否饱和,是检查服务器性能的一个重要指标。
「sar –n TCP,ETCP 1」用于查看TCP连接状态以及连接数量。其中,TCP的连接数量可以用来判断服务器的性能如何,同时还能够判断谁是主动连接,谁是被动连接。
「Iostatb –xz 1」主要用于查看服务器的磁盘IO情况,看是否有满负荷运转的情况发生。
「Dmesg | tail」用于输出查看日志使用,这些日志可以帮助我们排查性能的问题。
作为 IT 运维工程师,定时的关注服务器性能变化,可以帮助在发现异常的第一时间采取措施,保障业务的正常运行。试想,如果拥有一个能够监控全局,实现业务告警风险提醒的运维协作工具呢?定能极大提升工作效率,加强团队运维保障能力!