【51CTO.com原创稿件】笔者所在的公司有一款大 DAU(日活)的休闲游戏。这款游戏的后端架构很简单,可以简单理解为通讯-逻辑-存储三层结构。其中存储层大量使用了 Redis 和 MySQL。
图片来自 Pexels
随着存量用户的增加,Redis 就隔三差五的出现问题。所以笔者打算把遇到的一系列问题以及在项目里的实践都整理记录下来。
项目组每天 14 点都会遭遇惊魂时刻。一条条告警短信把工程师从午后小憩中拉回现实,之后问题又神秘消失。
是 PM 喊你上工了?还是服务器给你开玩笑?下面请看工程师如何一步一步揪出真凶,解决问题。
1、起因
某天下午,后端组的监控系统发出告警,服务器响应时间变长,超过了阈值。过一会儿系统自动恢复了,告警解除。
第二天差不多的时间点,监控系统又发出了同样的告警,过几分钟后又恢复了。于是我们决定排查这个问题。
2、背景
首先要介绍一下应用的架构,是很简单的三层架构的 Web 服务,从外到内大概是这样的:
- Load Balance:对外提供访问入口,对内实现负载均衡。
- Nginx:放在 LB 后面,实现流控等功能。
- App Service:逻辑服务,多机多进程。
- Storage:MySQL 和 Redis 组成的存储层。
我们的服务部署在 AWS 云上,架构里用到了很多 AWS 的服务,比如 ELB,EC2,RDS 等。
3、表象
排查问题的第一步就是要收集信息。从监控和日志系统里提取大量的相关信息,然后再分析、解决问题。
我们收集到的信息大概是这样的,在每天 14 点的时候:
- QPS 突增。
- P99 指标升高。
- App 服务器集群 CPU、内存都升高,TCP 连接数暴涨,入网流量降低。
- MySQL Write IOPS 升高,写入延时升高,数据库连接数升高。
几分钟后,这些指标都回归到正常水平。
4、排查
首先从代码入手,看看是不是有这个时间点的定时任务。结果发现并没有。然后就是第一个怀疑对象 MySQL。
使用 mysqlbinlog 命令统计一下各个时间点的 binlog 数量:
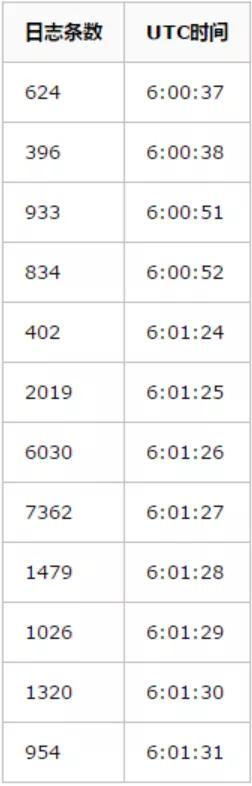
我们又在第二天的这个时间点观察了一下现场,使用 show processlist 命令抓取一下当时 MySQL 连接的状态,结果发现来自 App 服务器的连接竟然都 sleep 了 20 秒左右,什么事儿都没做。
初步推论
根据以上的数据可以还原一下当时的场景:
- App 服务器 Socket 数激增。
- App 服务器不再进行逻辑处理(这个待确认)。
- App 服务器不再进行任何数据库操作。
- App 服务器恢复读写数据库。
- 积压了大量的网络请求让游戏服务器 CPU 增加。
- 大批量的写请求涌向数据库造成数据库各项指标升高。
那么问题来了:
- 激增的 Socket 来自哪里?
- 或者去连接了谁?
- App 服务器为什么会长达 20 秒没有什么数据库操作?
- App 服务器是真的 hang 住了?
带着疑问开始进一步排查。
5、深入排查
先解决第一个问题:多出来的 Socket 来自哪里?
App Service
在 14 点前,选一台 App 服务器,抓取它的 TCP 连接:
- #!/bin/bash
- while [ true ]; do
- currentHour=$(date +%H)
- currentMin=$(date +%M)
- filename=$(date +%y%m%d%H%M%S).txt
- if [ $currentHour -eq 05 ] && [ $currentMin -gt 58 ]; then
- ss -t -a >> $filename
- #/bin/date >> $filename
- elif [ $currentHour -eq 06 ] && [ $currentMin -lt 05 ]; then
- ss -t -a >> $filename
- #/bin/date >> $filename
- elif [ $currentHour -ge 06 ] && [ $currentMin -gt 05 ]; then
- exit;
- fi
- /bin/sleep 1
- done
对大小差异比较大的文件进行比对,发现多出来的连接来自 Nginx。Nginx 只是个代理,那就排查它的上游 Load Balance。
Load Balance
Load Balance 我们使用的是 AWS 的经典产品 ELB。ELB 的日志很大,主要是分析一下这段时间内有没有异常的流量。
经过对比分析 13:55-14:00 和 14:00-14:05 这两个时间段的请求上没有明显的差异。
基本上都是由以下请求构成:
- https://xxxxxxx.xxxx.xxx:443/time
- https://xxxxx.xxxx.xxx:443/gateway/v1
但是从 14:00:53 开始,带 gateway 的请求大部分都返回 504,带 time 的请求都正常返回。504 表示网关超时,就是 App 响应超时了。
根据这个信息又可以推断出一些情况:
- App Service 还在正常提供服务,否则 time 请求不会正常返回。
- App Service 所有写数据库的操作都处于等待的状态。
- Nginx 到 App Service 的连接得不到及时处理,所以连接很长时间没有断开,导致了 Nginx 和 App Service 的 Socket 连接快速增长。
根据以上,基本上可以排除是 ELB,Nginx 带来的问题。那么问题就剩下一个,什么数据库长时间不可写呢? 而且每天都在固定时间。
MySQL
问题又回到了数据库上,首先想到的就是备份,但是我们的备份时间不在出问题的时间段。
我们使用的是 AWS 的 RDS 服务,查阅了一下 RDS 关于备份的文档。只有在数据库备份的时候才可能会出现写 I/O 挂起,导致数据库不可写。
而默认的备份时间窗口是这样的:
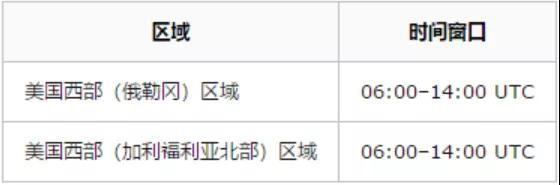
这个开始的时间也刚好在我们出问题的时间,简直是太巧合了。
下一步就是要确认这个问题。是在偷偷的帮我们做备份,还是实例所在的物理机上的其他实例干扰了我们?
在某个 MySQL 实例上建个新的数据库 test,创建一张新表 test:
- CREATE TABLE `test` (
- `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
- `curdate` varchar(100) NOT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
每秒钟往这张表里写条数据,数据的内容是当前时间,这样就能看出来在哪个时间段数据库不可写了。
同时每秒钟读取这张表的最大值,记录下结果和当前时间,这样就能看出来哪个时间段数据库不可读。
测试的脚本如下:
- #!/bin/bash
- host=xxxx.xxx.xxx
- port=3306
- user=xxxxx
- password=xxxxx
- mysql="mysql -u$user -p$password -h$host -P$port --default-character-set=utf8 -A -N"
- fetchsql="show processlist;"
- selectsql="select max(id),now(3) from test.test;"
- insertsql="insert into test.test(curdate) value(now(3));"
- function run(){
- filename_prefix=$1
- mysqlcmd="$($mysql -e "$fetchsql")"
- echo $mysqlcmd >> $filename_prefix.procs.txt
- mysqlcmd="$($mysql -e "$selectsql")"
- echo $mysqlcmd >> $filename_prefix.select.txt
- mysqlcmd="$($mysql -e "$insertsql" )"
- }
- while [ true ]; do
- currentHour=$(date +%H)
- currentMin=$(date +%M)
- filename_prefix=./checksql/$(date +%y%m%d%H%M%S)
- $(run $filename_prefix)
- if [ $currentHour -eq 05 ] && [ $currentMin -gt 59 ]; then
- $(run $filename_prefix);
- elif [ $currentHour -eq 06 ] && [ $currentMin -lt 02 ]; then
- $(run $filename_prefix);
- elif [ $currentHour -ge 06 ] && [ $currentMin -gt 02 ]; then
- exit;
- fi
- /bin/sleep 1
- done
这个脚本同时还每秒钟扫描一次 MySQL 各个客户端的工作状态。最后得到的结论是,出现问题的时间点,数据库可读也可写。
问题好像陷入了困境。怀疑的点被一一证明没有问题。线索也断了。只能再回到起点了,继续从代码下手,看看哪里会造成单点,哪里出现了问题会让所有的游戏服务器集体卡住,或者是让数据库操作卡住。
Redis
终于排查到了罪魁祸首主角,最可疑的有两个点:
- 数据库分片的方案依赖 Redis。Redis 里存储了每个用户的数据库分片 id,用来查找其数据所在的位置。
- 用户的设备和逻辑 id 的映射关系,也存储在 Redis 里。几乎每个 API 请求都要查找这个映射关系。
以上两点几乎是一个 API 请求的开始,如果这两点出现了问题,后续的操作都会被卡住。
经过和 OPS 确认,这两个 Redis 的备份时间窗口确实在 6:00-7:00utc。而且备份都是在从库上进行的,我们程序里的读操作也是在从库上进行的。
通过 Redis 的 info 命令,参考 Redis 最近一次的备份时间,时间点也刚好都在北京时间 14:01 左右。
进一步确认嫌疑:把两个 Redis 的备份时间做出更改。Redis1 更换为 3:00-4:00utc,Redis2 更换为 7:00-8:00utc。
北京时间 11:00 左右 Redis1 正常备份,问题没有复现;北京时间 14:00 左右问题没有复现;北京时间 15:00 左右 Redis2 正常备份,问题复现。
事后查看了一下 Redis1 和 Redis2 的数据量,Redis2 是 Redis1 的 5 倍左右。
Redis1 占用内存 1.3G 左右,Redis2 占用内存 6.0G 左右。Redis1 的备份过程几乎在瞬间完成,对 App 的影响不明显。
6、结论
问题出现的大致过程是这样的:
- Redis2 在北京时间的 14 点左右进行了从库备份。
- 备份期间导致了整个 Reids 从库的读取操作被阻塞住。
- 进一步导致了用户的 API 请求被阻塞住。
- 这期间没有进行任何数据库的操作。
- 被逐渐积累的 API 请求,在备份完成的一小段时间内,给 Nginx,App Service,Redis,RDS 都带来了不小的冲击。
- 所以出现了前文中描述的现象。
7、事后烟
其实问题的根源还在 Redis 的备份上,我们就来聊一下 Redis 的备份。
Redis 的持久化可以分为两种方案:
- 全量方式 RDB
- 增量方式 AOF
详情可以参考官方中文翻译:
http://www.redis.cn/topics/persistence.html
RDB
把内存中的全部数据按格式写入备份文件,这就是全量备份。它又分为两种不同的形式。
涉及到的 Redis 命令是 SAVE/BGSAVE:
- SAVE:众所周知,Redis 服务都是单线程的。SAVE 和其他常见的命令一样,也是运行在主进程里的。可想而知,如果 SAVE 的动作很慢,其他命令都得排队等着它结束。
- BGSAVE:BGSAVE 命令也可以触发全量备份,但是 Redis 会为它 Fork 出来一个子进程,BGSAVE 命令运行在子进程里,它不会影响到 Redis 的主进程执行其他指令。它唯一的影响可能就是会在操作系统层面上和 Redis 主进程竞争资源(CPU,RAM 等)。
AOF
增量的备份方式有点像 MySQL 的 binlog 机制。它把会改变数据的命令都追加写入到备份文件里。这种方式是 Redis 服务的行为,不对外提供命令。
两种方式优缺点对比:
- RDB 文件较小,自定义格式有优势。
- AOF 文件较大,虽然 Redis 会合并掉一些指令,但是流水账还是会很大。
- RDB 备份时间长,无法做到细粒度的备份。
- AOF 每条指令都备份,可以做到细粒度。
- 二者可以结合使用。
Amazon ElastiCache for Redis
我们使用的是 AWS 的托管服务,他们是怎么做备份的呢?
详情可以参考官方文档:
https://docs.aws.amazon.com/zh_cn/AmazonElastiCache/latest/red-ug/backups.html#backups-performance
Redis 2.8.22 以前:使用 BGSAVE 命令,如果预留内存不足,可能会导致备份失败。
Redis 2.8.22 及以后:如果内存不足,使用 SAVE 命令。如果内存充足,使用 BGSAVE 命令。
大概要预留多少内存呢?AWS 官方推荐 25% 的内存。很显然我们的实例的预留内存是不够这个数的,所以导致了问题的出现。我觉得 AWS 可以把备份做的更好。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】