













这次疫情的情况大家也都了解了,各地也都延迟开学或者延迟开工,对于我们来说,正好是一次深入学习的机会。今天,我就带领大家分析一下新型冠状病毒的爆发趋势,也借此作为一次数据分析课程的实战案例,从 数据获取、数据清洗、数据可视化再到产出数据结论,完整的走一遍数据分析流程。
这次使用的数据是霍普金斯大学收集的世界范围内的病毒爆发数据。
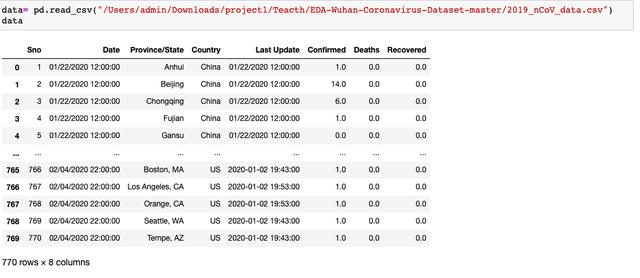
导入所需的包和数据
数据清洗
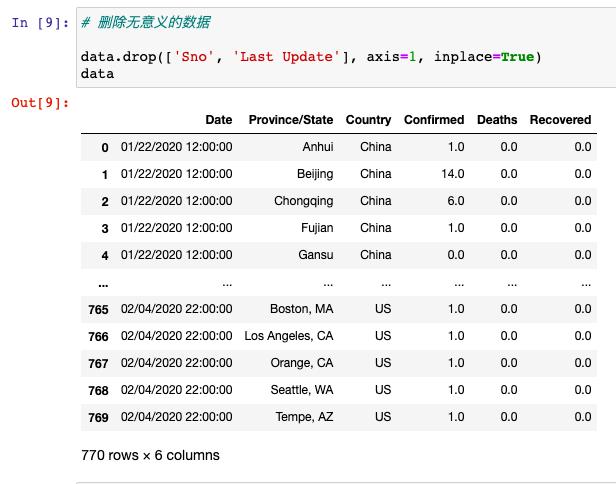
第一:删除不需要的数据列
从数据中我们可以看出,第一列相当于编号,第五列是数据更新的最后时间,这两列对我们的分析来说没有实际意义,所以先把这两列进行删除操作:
第二:对数据集中的空值进行处理
先来看一下数据的整体情况:
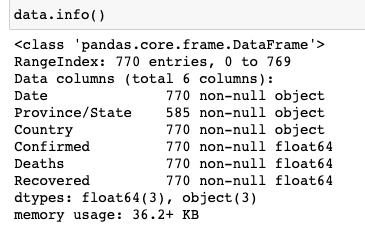
我们发现,只有省份这一个字段是有空值的,那我们再来看一下具体的空值有哪些:
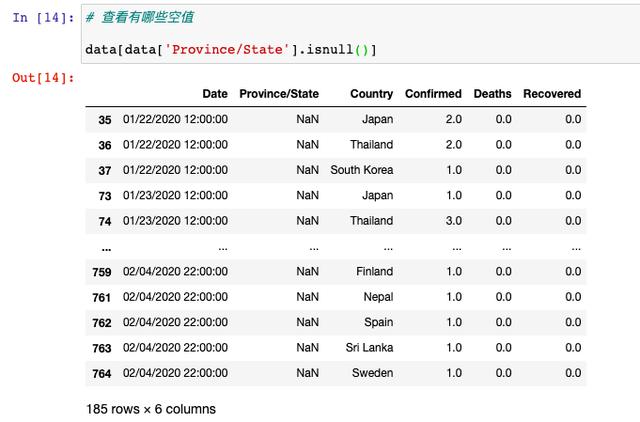
经过筛选发现,空缺的都是一些国外的省份,这是由于数据收集过程中产生的,并且我们无从推断到底是什么,所以,这里的空值我们选择不处理。
第三:删除重复数据
通过使用dumplicate方法,我们发现这个人工整理的数据集不存在重复情况,所以也不需要进行去重操作。
数据洞察
我们首先来看一下,截止到数据完成时间,世界上总共有多少国家已经「沦陷」了:

通过统计发现,总共只有32个国家已经有了确诊患者,但是,细心的同学可能会发现,国家列表当中有「China」和「Mainland China」,第二个表示的是「中国大陆」,其实也是中国,所以我们应该把「Mainland China」也改为「China」统一口径,在实际工作过程中,跨部门的数据经常会出现这种情况,所以,处理这种数据噪音也是数据分析师的日常工作之一。
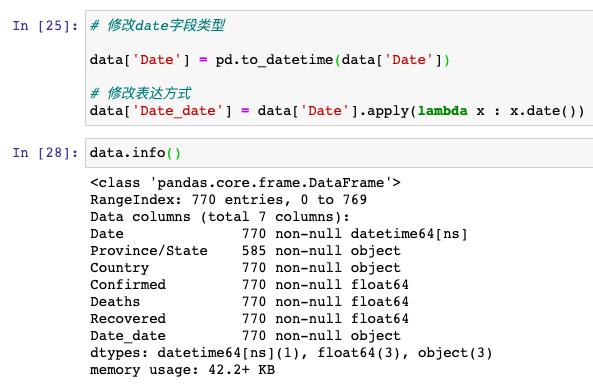
接着,我们看一下时间字段,时间字段的处理也是数据分析过程中不可或缺的一个步骤:

这里的时间,都是精确到「小时」的,为了便于统计,我们把它改成精确到「日」:
接下来,我们以国家作为维度,来统计一下每个国家的确诊人数:
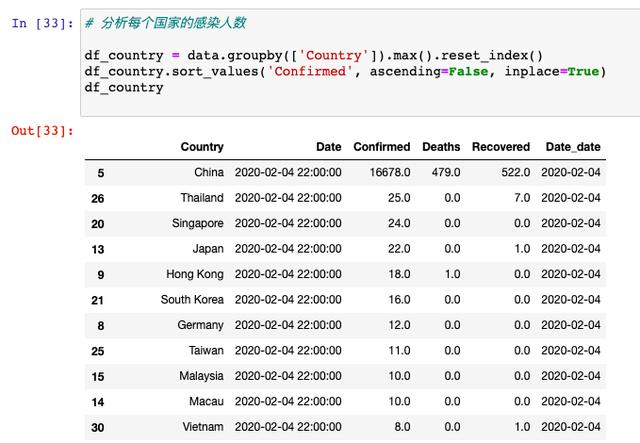
排名第一的肯定是中国,排名靠前的基本都是中国临近的亚洲国家,欧美国家当中,排名第一的是德国,如果是真正工作过程中,德国这一点就是「异常点」,肯定要深入挖掘,在这里我们只是做一个示例。
之后我们以时间作为维度,分析一下每天的感染人群数量的变化:
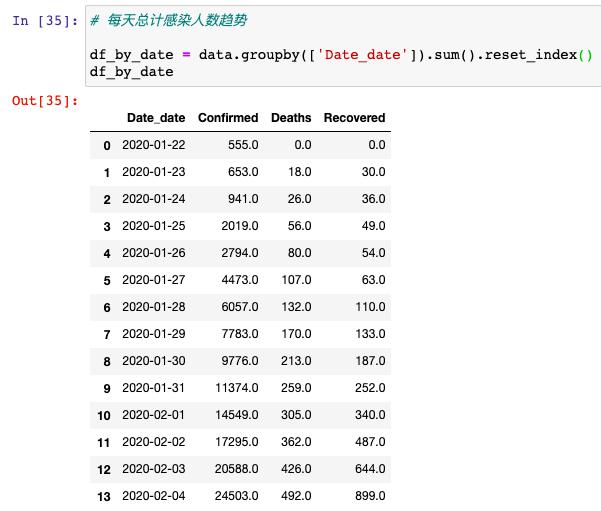
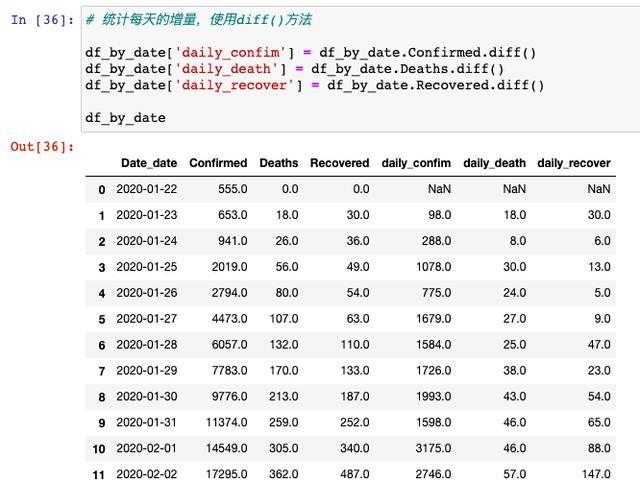
从这里可以看到,14天之内感染人数就从555人增长到24503个人,增长速度还是很快的,那我们接着也要具体分析一下,每天新增的确诊人数有多少人,这里我们需要用到diff( )方法:
数据可视化
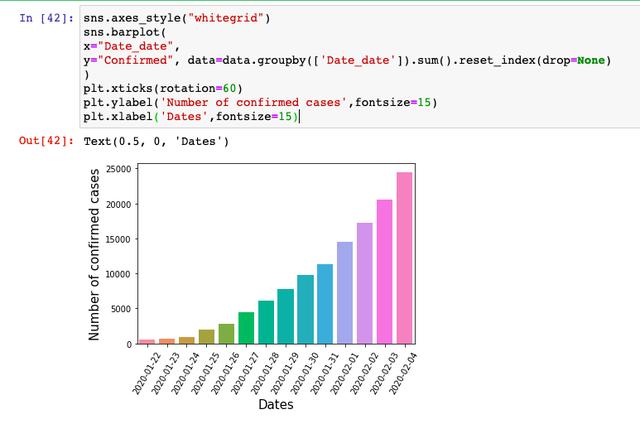
首先来看每天的确诊人数,基本上是指数增长的一个走势,符合传染病的爆发规律,我们要做的就是根据之后的数据,洞察拐点的到来。
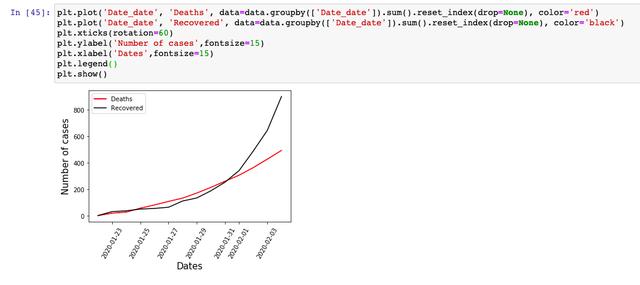
接着,我们看一下,每天的「死亡人数」和「治愈人数」的走势,从这个数据上来看,治愈人数的增长趋势已经超过的死亡人数,所以,从「最好」和「最坏」两个方面来说的话,总体趋势还是向好发展,大家也不必过于担心。
总结
以上分析只是抛砖引玉,使用一部分数据来引导大家参与到数据分析的实战流程当中,欢迎大家在留言区一起讨论学习。












