本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
快排堆排冒泡排。排序,在计算机中是再常见不过的算法。
在机器学习中,排序也经常用于统计数据、信息检索等领域。
那么问题来了,排序算法在函数角度上是分段线性的,也就是说,在几个分段的“节点”处是不可微的。这样,就给反向传播造成了困难。
现在,谷歌大脑针对这一问题,提出了一种快速可微分排序算法,并且,时间复杂度达到了O(nlogn),空间复杂度达为O(n)。
速度比现有方法快出一个数量级!

代码的PyTorch、TensorFlow和JAX版本即将开源。
快速可微分排序算法
现代深度学习架构通常是通过组合参数化功能块来构建,并使用梯度反向传播进行端到端的训练。
这也就激发了像LeCun提出的可微分编程 (differentiable programming)的概念。
虽然在经验上取得了较大的成功,但是许多操作仍旧存在不可微分的问题,这就限制了可以计算梯度的体系结构集。
诸如此类的操作就包括排序 (sorting)和排名 (ranking)。
从函数角度来看都是分段线性函数,排序的问题在于,它的向量包含许多不可微分的“节点”,而排名的秩要比排序还要麻烦。
首先将排序和排名操作转换为在排列多面体(permutahedron)上的线性过程,如下图所示。
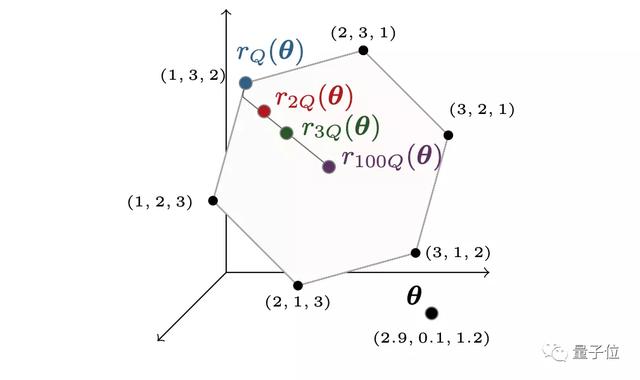
△排列多面体说明
在这一过程后,可以发现对于r(θ),若是θ出现微小“扰动”,就会导致线性程序跳转到另外一个排序,使得r(θ)不连续。
也就意味着导数要么为null,要么就是“未定义”,这就阻碍了梯度反向传播。
为了解决上述的问题,就需要对排序和排名运算符,进行有效可计算的近似设计。
谷歌大脑团队提出的方法,就是通过在线性规划公式中引入强凸正则化来实现这一目标。
这就让它们转换成高效可计算的投影算子(projection operator),可微分,且服从于形式分析(formal analysis)。
在投影到排列多面体之后,可以根据这些投影来定义软排序(soft sorting)和软排名(soft ranking)操作符。
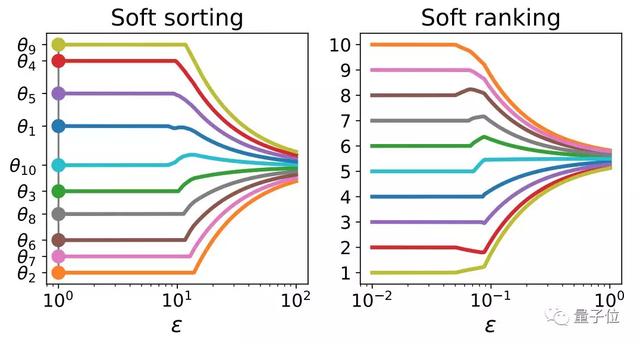
△软排序和软排名操作符
在此基础上,要想完成快速计算和微分,一个关键步骤就是将投影简化为保序优化 (isotonic optimization)。

接下来是将保序优化进行微分,此处采用的是雅可比矩阵(Jacobian),因为它简单的块级结构,使得导数很容易分析。

而后,结合命题3和引理2,可以描述投影到排列多面体上的雅可比矩阵。
需要强调的是,与保序优化的雅可比矩阵不同,投影的雅可比矩阵不是块对角的,因为我们需要对它的行和列进行转置。
最终,可以用O(n)时间和空间中的软算子雅可比矩阵相乘。
实验结果
研究人员在CIFAR-10和CIFAR-100数据集上进行了实验。
实验使用的CNN,包含4个具有2个最大池化层的Conv2D,RelU激活,2个完全连接层;ADAM优化器的步长恒定为10-4,k=1。
与之比较的是O(Tn2)的OT方法,以及O(n2)的All-pairs方法。
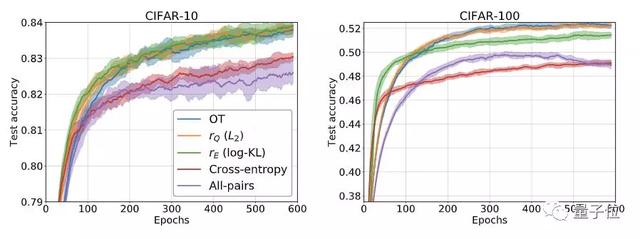
△rQ及rE为新算法
结果表明,在CIFAR-10和CIFAR-100上,新算法都达到了与OT方法相当的精度,并且速度明显更快。
在CIFAR-100上训练600个epoch,OT耗费的时间为29小时,rQ为21小时,rE为23小时,All-pairs为16小时。在CIFAR-10上结果差不多。
在验证输入尺寸对运行时间的影响时,研究人员使用的是64GB RAM的6核Intel Xeon W-2135,以及GeForce GTX 1080Ti。
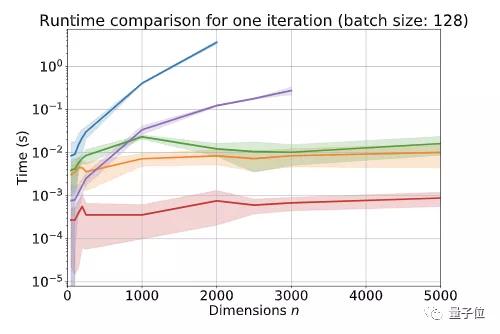
禁用反向传播的情况下,进行1个batch的计算,OT和All-pairs分别在n=2000和n=3000的时候出现内存不足。
启用反向传播时,OT和All-pairs分别在n=1000和n=2500的时候出现内存不足。
开启新的可能性
曾就职于谷歌、NASA的机器学习工程师Brad Neuberg认为,从机器学习的角度来说,快速可微分排序、排名算法看上去十分重要。

而谷歌的这一新排序算法,也在reddit和hacker news等平台上引起了热烈的讨论。
有网友对其带来的“新可能性”做出了更为详细的讨论:
我想,可微分排序生成的梯度信息量更大,使得梯度下降的速度更快,从而能够进一步提升训练速度。

我认为,这意味着某些基于排名的指标,以后可以用可微分的形式来表示。也就是说,神经网络可以轻松地针对这些结果直接进行优化。
对于谷歌而言,这很显然会应用于网络搜索,以及诸如标签分配之类的东西问题。

也有网友指出,虽然该算法并不是第一个解决了排序不可微问题的方法,但它的效率无疑更高。

传送门
论文:https://arxiv.org/pdf/2002.08871.pdf
讨论:https://news.ycombinator.com/item?id=22393790https://www.reddit.com/r/MachineLearning/comments/f85yp4/r_fast_differentiable_sorting_and_ranking/