












初学Python编程的人,面临的是各种未知的挑战。
下面是一个几乎让所有更有抱负的数据科学家都感到意外的场景:
你正在处理一个从多个源收集数据的项目。在进入探索和模型构建部分之前,你需要首先连接这些多个数据集(以表、数据帧等形式)。怎么能做到这一点而不丢失任何信息?
这听起来可能是一个简单的场景,但对于许多新来的人来说,这可能是一个威胁,特别是那些不熟悉Python编程的人。
进一步深入研究,我可以大致将其分为两种情况:
- 首先,具有相似属性的数据可以分布到多个文件中。例如,假设向你提供了多个文件,每个文件都存储一年中某一周内发生的销售信息。因此,全年将有52个文件。每个文件的列数和名称都相同。
- 其次,你可能需要合并来自多个来源的信息。例如,假设你想获得购买产品的人的联系信息。这里有两个文件,第一个有销售信息,第二个有客户信息。
理解手头的问题
本文列举一个通俗易懂的例子。
想一下在一个特定的学校里考试。每个科目都有不同的老师授课。他们更新关于学生成绩和整体表现的档案。这些档案就是多个文件!
本文使用创建的两个这样的文件来演示Python中函数的工作。第一个文件包含关于12班学生的数据,另一个文件包含10班的数据。还将使用第三个文件来存储学生的姓名和学生ID。
注意:虽然这些数据集是从零开始创建的,但鼓励将所学应用于选择的数据集。
在Python中逐步合并数据帧的过程
下面是解决这个问题的方法:
- 用Python加载数据集
- 合并两个相似的数据帧(append)
- 合并来自两个数据帧的信息(merge)
步骤1:用Python加载数据集
本文将使用三个独立的数据集。首先,将这些文件加载到单独的数据帧中。
- import pandas as pd
- marks10th=pd.read_csv('10thClassMarks.csv')
- marks12th=pd.read_csv('12thClassMarks.csv')
- IDandName=pd.read_csv('StudentIDandName.csv')
前两个数据框包含学生的百分比及其学生ID。在第一个数据框中,有10班学生的分数,而第二个数据框包含第12个标准中学生的分数。第三个数据框包含学生的姓名以及各自的学生ID。
来源:btime
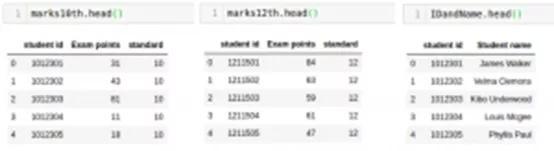
使用“head”函数检查每个数据帧的前几行:
- marks10th.head()
- marks12th.head()
- IDandName.head()
步骤2:合并两个相似的数据帧(Append)
把10、12班的档案合并起来,找出学生的平均分。这里使用Pandas库中的“append”函数:
- allMarks=marks10th.append(marks12th)
- marks10th.shape, marks12th.shape, allMarks.shape
输出((50,3),(50,3),(100,3))
从输出中可以看到,在append函数中垂直添加两个数据帧。
结果数据帧是allMarks。上面比较了所有三个数据帧的形状。
接下来看看“allMarks”的内容并计算平均值:
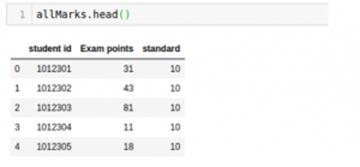
- allMarks['Exam Points'].mean() #Average Marks
输出:49.74
步骤3:合并来自两个数据帧的信息(Merge)
现在,假设想找出在这两个批次中排名第一的学生的名字。这里不需要垂直添加数据帧。为了给学生的名字再加一列,我们将不得不水平缩放。
要做到这一点,我们会发现最高得分:
- allMarks['Exam Points'].max() # Maximum Marks
输出:100
学生的最高成绩是100分。现在,使用“merge”函数查找此学生的姓名:
- mergedData=allMarks.merge(IDandName, on='student id')
- mergedData.head()
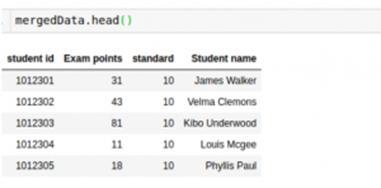
最后,生成的数据框有学生的名字和他们的标记。
merge函数需要一个必要的属性,两个数据帧将在该属性上合并。需要传递此列的名称在“on”参数中。
merge函数的另一个重要论点是“如何”。这指定要在数据帧上执行的联接类型。以下是可以执行的不同连接类型(SQL用户将非常熟悉这一点):
- 内部连接(如果不提供任何参数,则默认执行)
- 外部连接
- 右连接
- 左连接
还可以使用“sort”参数对数据帧进行排序。这些是合并两个数据帧时最常用的参数。
来源:Pexels
现在,我们将看到数据框包含100个“检查点”的行:
- mergedData.loc[mergedData['Exam Points']==100]
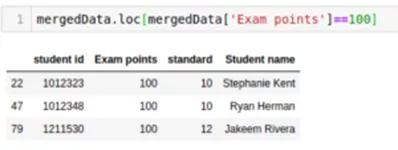
三个学生得了100分,其中两个在10班。做得好!
接下来,我的建议是接受包含3个不同文件的食物预测挑战。
很直截了当,对吧?
你再也不必为此而自责了!你可以继续并将其应用于选择的任何数据集。
















