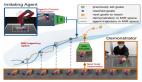
计算机视觉是什么?过于专业,一步劝退?在普通人看来,计算机视觉是软件开发者才能涉足的领域,需要用到很多专业的框架,普通人只能围观。但 GitHub 上的一个项目似乎颠覆了我们的认知。
Excel 基本操作会吧?上网搜索公式会吧?基本的数学理解能力有吧?OK,如果以上你都能做到,你也能上手计算机视觉项目了。
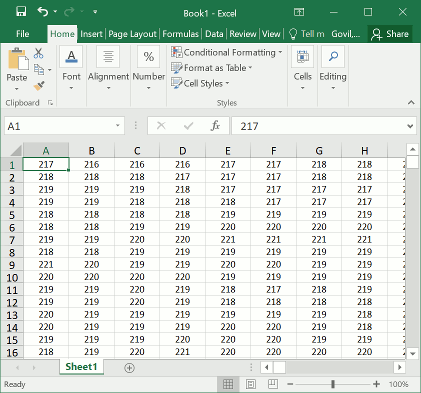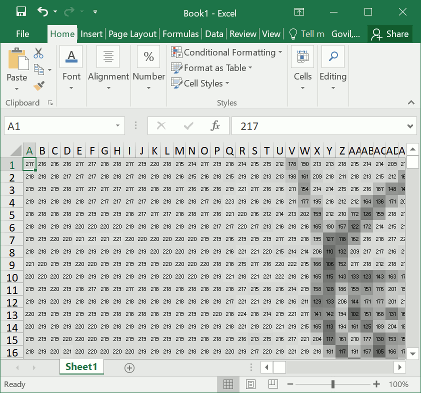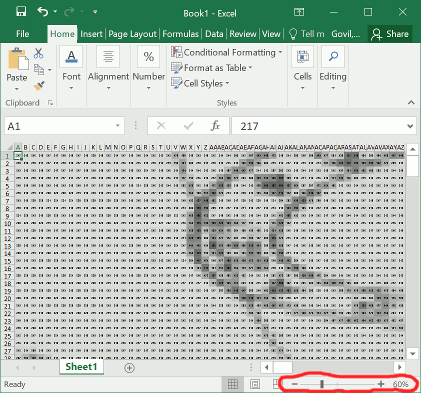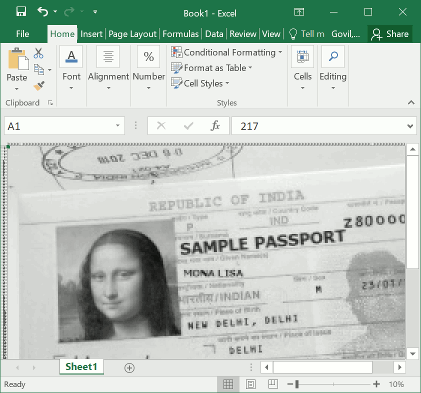
图 1:将一张图像转换为 Excel 单元格表示的灰度图像。可以看到,只要单元格细粒度足够高,就可以存储足够的图像信息。
具体来说,在这个项目中,作者尝试用 Excel 实现的样本算法来帮助我们学习计算机视觉的基础知识。为此,他用到了很多只有一行的 Excel 公式。作者表示,在这个项目中,用 Excel 做人脸检测、霍夫变换都不在话下,而且不依赖任何脚本或第三方插件。
以下是使用 Excel 进行的一些计算机视觉任务。首先,我们有一个示例图像。这是一个护照。如图所示,Excel 的算法可以实现对照片人像的检测(使用传统手工算法)。

同样,这幅图像也可以被 Excel 转换,然后找到边和线的特征。

最后,Excel 还可以进行 OCR 操作。首先对图像进行手工分割,找到相关的图像文本,然后进行 OCR 即可。

这个项目不要求你提前掌握计算机视觉背景知识,但需要了解 Microsoft Excel 基础操作,会阅读 Excel 文档或上网搜索需要用到的公式的相关解释。对于后者,推荐使用 Exceljet。
此外,你还需要具备一些数学理解能力:如果理解不了加权平均数,可能很难继续学下去。掌握偏微分很有帮助,但不是硬性要求。项目中用到的复杂数学概念大多数是特征值。
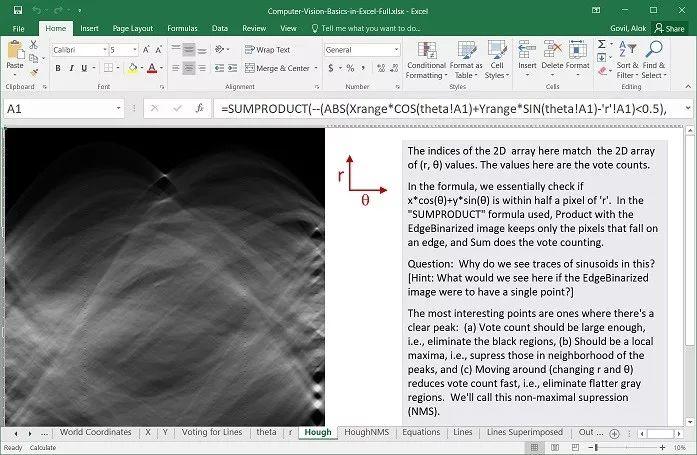
Excel 怎么计算图像数据?
使用 Excel 做计算机视觉,乍一听显得有点魔幻。但其实原理很简单:这个教程利用了 Excel 强大的单元格计算能力,只要将图像的像素数据转换为单元格(如下图所示),然后计算即可。我们知道每个单元格都可以表示一个值,那么很多个单元格是不是就可以表示成矩阵了?

对示例文件的截图(样本图片局部),可以看到 Excel 单元格表示了图像的灰度。
而另一方面,我们可以很方便地利用 Excel 计算单元格的数据。那么整合起来,是不是和矩阵计算很相似了?这样,不同图像位置表示的特征也就很容易被计算出来。自然也就方便完成下游计算机视觉的任务了,不管是传统算法也好,还是机器学习也好。
可是,图像怎样输入到 Excel 中呢?作者提供了一个方法:用 CSV 呀。
你可以用很多种方式转换 RGB 图像到像素点数据,如使用一个程序等:
https://alvinalexander.com/blog/post/java/getting-rgb-values-for-each-pixel-in-image-using-java-bufferedi
当图像的像素转换为 CSV 后,使用 Excel 读取即可。
项目指南
项目需要的关键材料都可以在「Downloads」部分找到。这些材料都带有注释,通俗易懂,可以按部就班,一步一步学。
软件要求
这个项目是在 Excel 2016 上创建的,在其他版本上应该也能打开(目前已经在 Excel 2007 和 Mac 的 Excel 上进行了测试)。
此外,虽然这些文件能在 LibreOffice 上打开(测试版本是 6.4.0.3 (x64)),但速度极慢,可以说没办法用。目前还没有在 Apache OpenOffice 上进行测试。
相关 Excel 公式选项
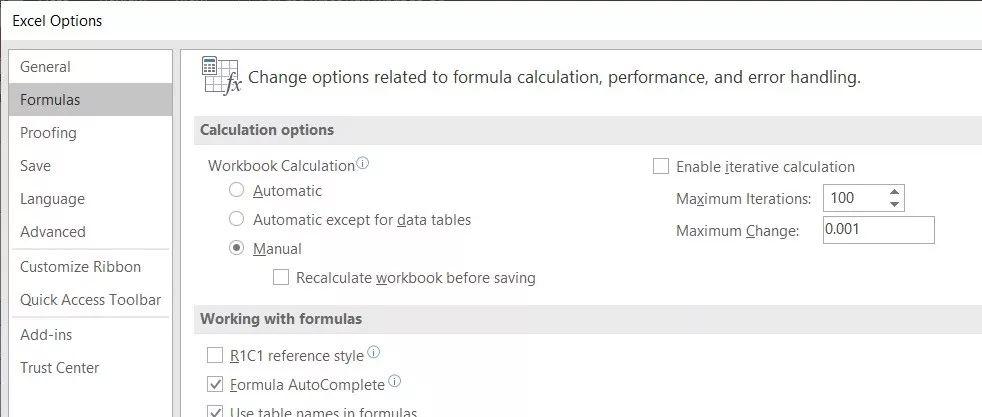
在打开项目中的 Excel 文件之前,请先把 Excel 的「公式」→「计算选项」调为「手动」,因为有些计算(尤其是霍夫变换)非常耗时。然后根据需要手动触发重算。

此外,不要勾选「保存工作簿前重新计算」,否则 Excel 将在每次保存文件时重新计算所有公式。
注意:这个项目做完后,记得把设置改回来。
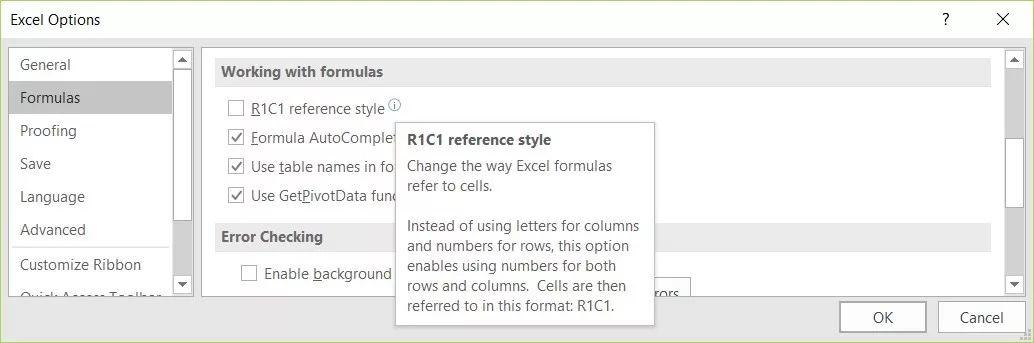
熟悉 Excel 中 R1C1 公式引用样式的人或者喜欢冒险的人,应该尝试通过查看 Excel 选项来切换到 R1C1 引用样式。
参考下面的屏幕截图,勾选 R1C1 引用样式对应的复选框来启用这个选项。如此一来,我们可以把公式从「D5」类型的格式更改为「R[-1]C[2]」这样的相对样式,使其更接近编程语言并有助于理解。
教程目录和代码文件
下图所示为本项目的相关教程目录和项目文件,总共 50MB,大家可以前往 GitHub 下载。
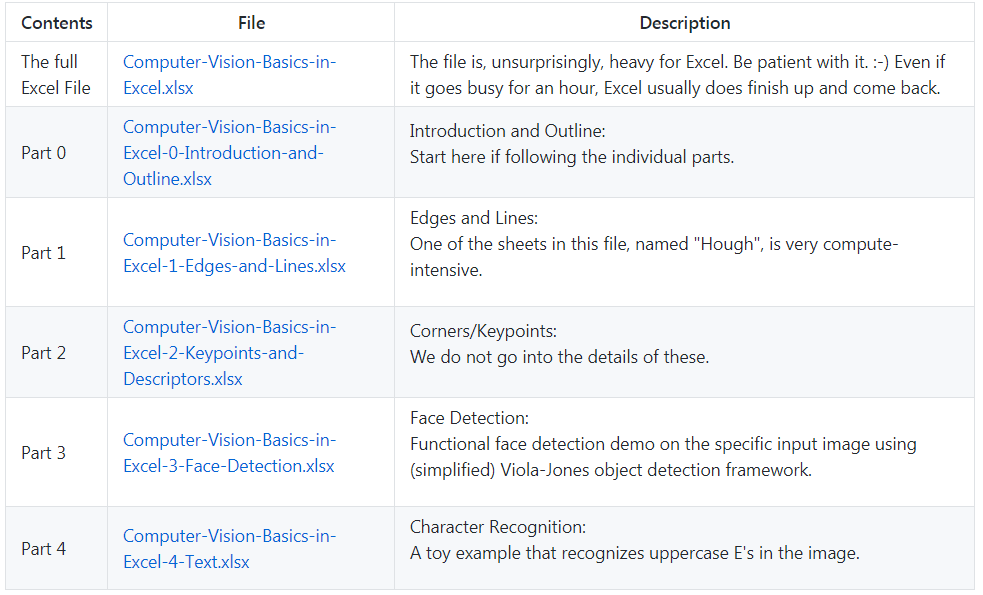
这一项目分为五个部分:
1. 计算机视觉 Excel 基础
2. 边和线
3. 关键点和描述算子
4. 人脸检测
5. 文本识别(OCR)
这些项目都有相关说明和代码,非常详细。
常见问题和解答
作者在留下教程之余,也对相关的一些问题提供了解答。
问题 1:这些技术是否可被深度学习替代?
这些技术依然是相关的。尽管神经网络已经替代了所有复杂的计算机视觉问题,特别是那些传统技术没有解决的问题。但是在简单的计算上,传统方法更快,而且计算效率更高。另外,传统方法依然是边缘设备(智能手机、网络客户端)等的首选,虽然已有很多硬件加速的方法。
问题 2:为什么使用图像的绿通道,而不是红或蓝?如果想在 Excel 中用这种方式展示彩色图像要怎么做?
作者表示,三种基本的颜色通道中,绿通道对亮度的影响最大。理论上,图像会首先被转换为灰度图,即计算其亮度,在教程中为了简便被省略了。关于彩色图像的表示,可以看一下第 6 个问题。
问题 3:护照中带有水印的人脸为什么没被检测到?
作者使用的是一个流行的人脸检测算法,仅使用三个类 Haar 特征和两个步骤。这一算法是针对蒙娜丽莎(示例)中的图像手工设计的。而在实际应用中,机器学习可以学习数千个这样的特征,因此才能准确检测到人脸。
问题 4:在 OCR 示例中如何选择 mask 以及方向?
对于文档 OCR(与场景文本识别相反)来说,在识别文档中的字符之前,文档通常先被拉直。所以,字符一般为直立的。
在示例中,作者使用单神经元来识别大写字母「E」。神经网络利用多层神经元来识别所有感兴趣的字符。然后神经网络输出输入端出现的字符。需要注意的是,组合神经元将在识别每个字符的过程中共享一些神经元。
问题 5:OCR 方法在不同字体上的效果如何?
作为示例,作者使用单卷积神经元来识别大写字母「E」。实际系统通常会使用到神经网络(并不仅是单神经元),并且在不同字体和语言上都表现良好。
具体是如何实现的呢?作者使用单神经元来同时扫描图像和识别字母。通常情况下,扫描不同篇幅的文本需要通过不同的方法单独完成。一旦文本的每个字符被隔离,则字符重新缩放至一个固定大小,然后使用神经网络来识别字母。
手写识别更加困难。当笔画数据为时间函数(如在触摸屏上识别是写输入)时,能够实现最佳效果。此外,在示例中,即使单个神经元的权重是手工的,实际上也不使用训练算法来学习。在实际训练时,单个神经元的效果也比 demo 展示中的要好。
问题 6:作者是如何想到用 Excel 做计算机视觉的呢?
起初,作者要给亚马逊内部员工讲授计算机视觉教程,但他们对该主题不熟悉。所以,作者通过展示图像本质上是数字的 2D 阵列来讲述计算机视觉的基础知识,并想要使用 Excel 来展示。作者大约花费 7 个小时来创建了第一个功能完善的版本,但不涵盖人脸检测和文本识别。之后的版本又做了进一步完善。
自那时起,作者已经创建了以下在 Excel 中展示图像的视频作品或教程(附链接):
- Excel 电子表格中的图像(包括颜色):
https://www.youtube.com/watch?v=UBX2QQHlQ_I
- Excel 光线跟踪:
https://www.youtube.com/watch?v=m28jJ7CMp8A&feature=emb_logo
- Excel 3D 引擎:
https://www.youtube.com/watch?v=bFOL9kantXA
- Excel 3D 图形:
https://www.gamasutra.com/view/feature/131968/microsoft_excel_revolutionary_3d_.php
问题 7:是否有计算机视觉的交互式开发者环境?
由于 Matlab 具有内置或在工具箱中具有很多计算机视觉功能,所以它通常用于计算机视觉任务。其中,「imshow」功能可直接将阵列数据以图像的形式显示出来。此外,基于 Python 和 Notebooks 的工具也很流行。
项目作者
项目作者有两位,分别为 Alok Govil 和合作者 Venkataramanan Subramanian,他们都是亚马逊的首席工程师。
其中,Alok Govil 是一位全栈技术架构师,本科和硕士分别毕业于德里技术大学(Delhi Technological University)和美国南加利福尼亚大学。他毕业后曾先后就职于飞利浦美国研究院、高通等公司,现为亚马逊首席工程师。
Alok Govil。
合作者 Venkataramanan Subramanian 本科毕业于印度马德拉斯大学,之后攻读班加罗尔国际信息技术学院的在职硕士。他毕业后先后就职于 Hexaware Technologies 和甲骨文公司,并于 2011 年入职亚马逊担任首席工程师至今。