众所周知,当今业界性能最强(SOTA)的深度学习模型都会占用巨大的显存空间,很多过去性能算得上强劲的 GPU,现在可能稍显内存不足。在 lambda 最新的一篇显卡横向测评文章中,开发者们探讨了哪些 GPU 可以再不出现内存错误的情况下训练模型。当然,还有这些 GPU 的 AI 性能。

今年的 GPU 评测相比往年有了不小的变化:因为深度学习技术的突飞猛进,以前 12G 内存打天下的局面不复存在了。在 2020 年 2 月,你至少需要花费 2500 美元买上一块英伟达最新款的 Titan RTX 才可以勉强跑通业界性能最好的模型——那到今年年底会是什么样就无法想象了。或许我们应该把目光转向云端 GPU。
一、一句话总结
截止到 2020 年 2 月份,只有以下这几种 GPU 可以训练所有业内顶尖的语言和图像模型:
- RTX 8000:48GB 显存,约 5500 美元
- RTX 6000:24GB 显存,约 4000 美元
- Titan RTX:24GB 显存,约 2500 美元
以下 GPU 可以训练大多数 SOTA 模型,但不是所有模型都能:
- RTX 2080Ti:11GB 显存,约 1150 美元
- GTX 1080Ti:11GB 显存,约 800 美元(二手)
- RTX 2080:8GB 显存,约 720 美元
- RTX 2070:8GB 显存,约 500 美元
超大规模的模型在这一级别的 GPU 上训练,通常需要调小 Batch size,这很可能意味着更低的准确性。
以下 GPU 不太能用作高端 AI 模型的训练:
RTX 2060:6GB 显存,约 359 美元
1. 图像模型测试
为测试当前 GPU 性能,研究者们以 CV 和 NLP 两个方向的顶尖模型进行了测试。处理图像模型而言,基础版 GPU 或 Ti 系的处理的效果都不是很好,且相互差异不大。
相较而言 RTX 的有明显优势且以最新版的 RTX8000 最为突出,不难发现就目前为止对于 GPU 能处理的批量大小基本都是以 2 的倍数来提升。相较于性能方面,总体还是以 RTX 系为最优。
(1) 显存能支持的最大批量大小
如下如果要训练 Pix2Pix HD 模型,至少需要 24GB 的显存,且批大小还只能是一张图像。这主要因为输入图像为 2048x1024 的高清大图,训练所需的显存与计算都非常大。
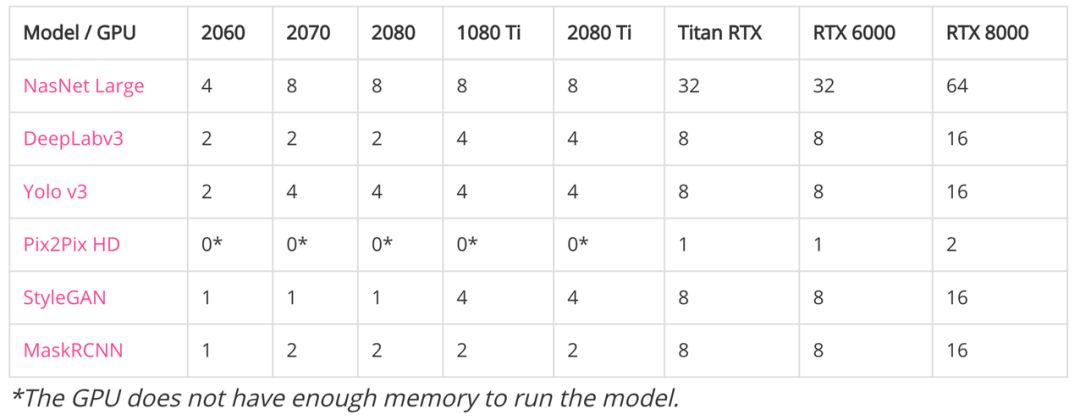
带*符号表示 GPU 显存不足以运行模型
(2) 性能(每秒处理的图像数量)
这些都是大模型,连计算最快的神经架构搜索模型 NasNet Large,之前也一直以算力需求大著称。尽管训练 NasNet Large 的数据集是 ImageNet,其图像分辨率只有 331x331。
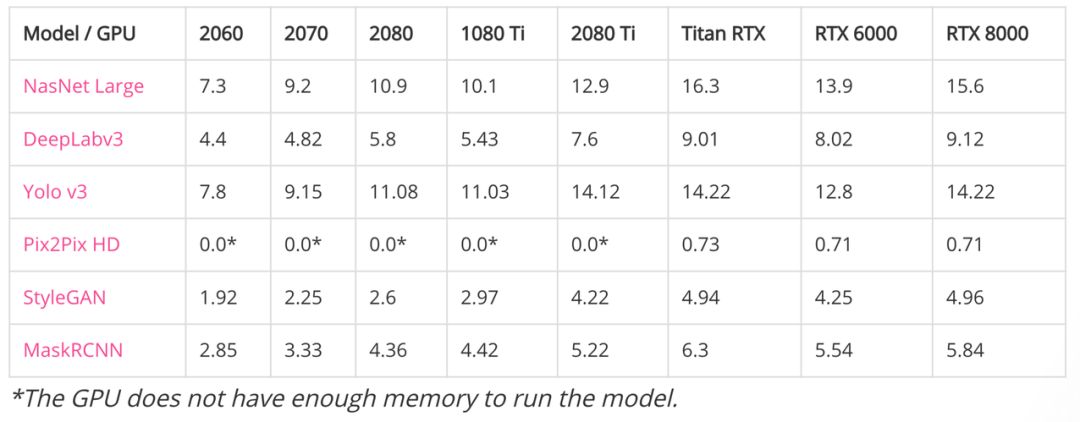
带*符号表示 GPU 显存不足以运行模型
2. 语言类模型测试
对于语言类模型而言,批量处理量方面依旧是 RTX 系为最优。但单从性能角度而言,跟其他各款相比,Titan RTX 却有着不错的表现。
(1) 显存能支持的最大批量大小
如下前面三个都是机器翻译模型,后面三个都是预训练语言模型。两者的计数方式不太一样,一条 Sequences 可能几十到几百个 Token。
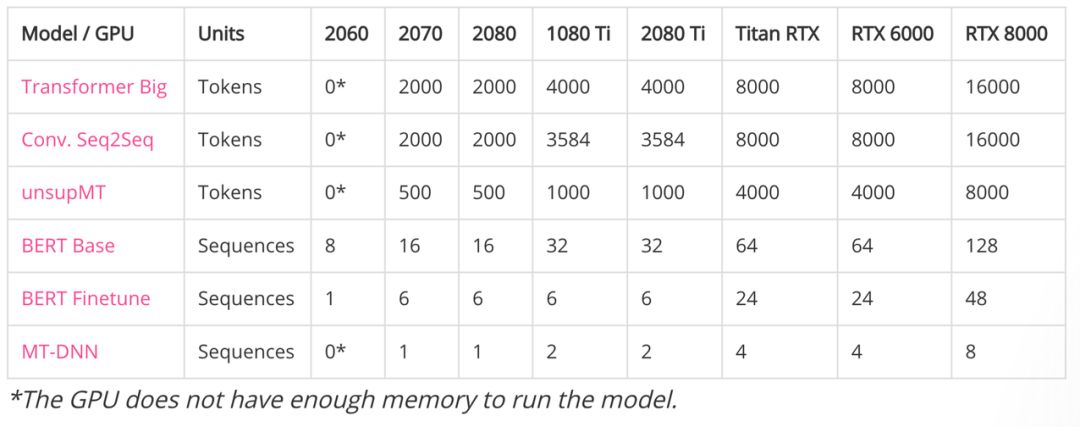
带*符号表示 GPU 显存不足以运行模型
(2) 性能
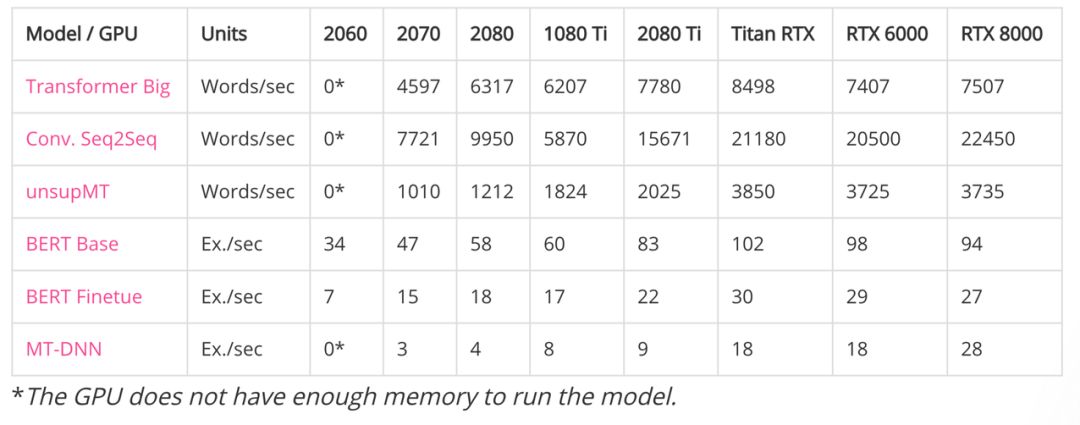
带*符号表示 GPU 显存不足以运行模型
3. 以 RTX 8000 为基准,向右看齐
上面的性能表格可能不够直观,lambda 以 Quadro RTX 8000 为基准,将其设定为「1」,其它 GPU 则针对该 GPU 计算出相对性能。如下所示为不同模型在不同 GPU 上进行训练的数据吞吐量:
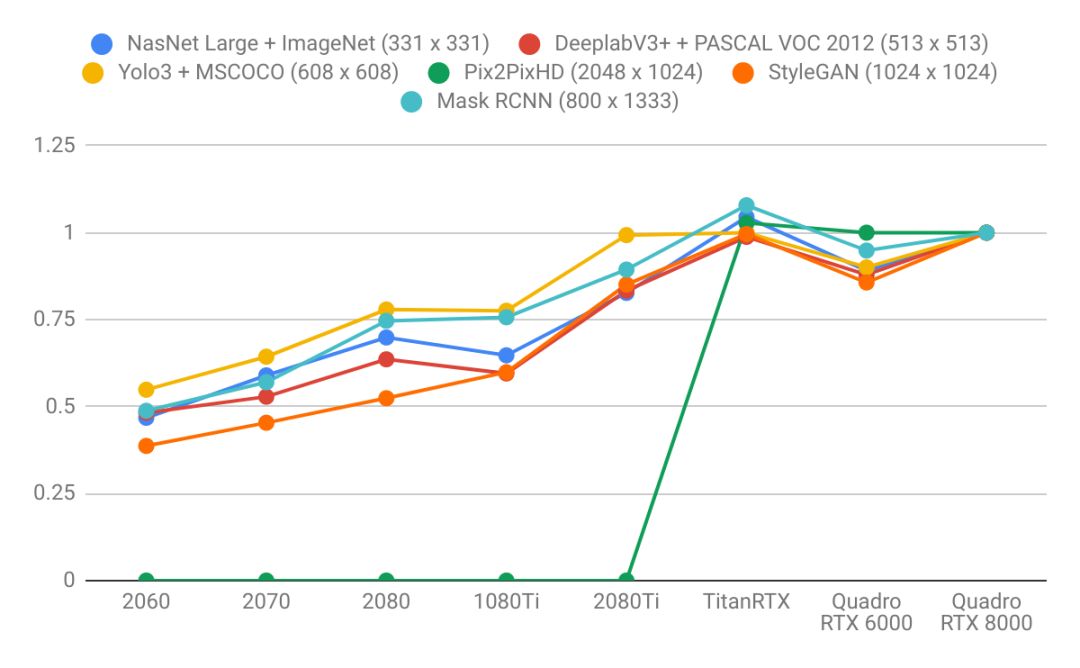

对于所有测试结果,lambda 给出了测试模型与数据集。如说是 CV 中的各种任务,其采用了 ImageNet、MSCOCO 和 CityScape 等主流主数据集,模型也直接用原作者在 GitHub 上开源的代码。如果是 NLP 中的各种任务,除了 WMT 英-德数据集,其它 GLUE 基准中的数据集也有采用。
从图像识别、分割、检测与生成,到机器翻译、语言模型与 GLUE 基准,这些任务差不多覆盖了 GPU 使用的绝大多数场景,这样的测试也是比较合理了。
二、2020 年,深度学习需要什么样的 GPU?
「旧模型」都跑不了,更别说什么开发新模型了。看完上面的测试结果,是不是感觉「生活突然失去了梦想」?除了硬件之外,我们还可以从本次测评中观察到近段时间深度学习发展趋势的变化:
- 语言模型比图像模型更需要大容量显存。注意语言模型那张图的折线变化轨迹要比图像模型那张更加陡峭。这表明语言模型受内存的限制更大,而图像模型受算力的限制更大。
- 显存越高,意味着性能越强大。因为显存越大,batch size 就越大,CUDA 核可以更加接近满负荷工作。
- 更大的显存可以按比例用更大的 Batch size,以此推之:24GB 显存的 GPU 相比 8GB 显存的 GPU 可以用上 3 倍的 batch。
- 对于长序列来说,语言模型的内存占用增长情况不成比例,因为注意力是序列长度的二次方。
有了这些认识,我们就可以愉快地挑选 GPU 了:
- RTX 2060(6GB):如果你想在业余时间探索深度学习。
- RTX 2070 或 2080(8GB):如果你想认真地研究深度学习,但用在 GPU 上的预算仅为 600-800 美元。8G 的显存可以适用于大部分主流深度学习模型。
- RTX 2080Ti(11GB):如果你想要认真地研究深度学习,不过用在 GPU 上的预算可以到 1200 美元。RTX 2080Ti 在深度学习训练上要比 RTX 2080 快大约 40%。
- Titan RTX 和 Quadro RTX 6000(24GB):如果你经常研究 SOTA 模型,但没有富裕到能买 RTX 8000 的话,可以选这两款显卡。
- Quadro RTX 8000(48GB):恭喜你,你的投入正面向未来,你的研究甚至可能会成为 2020 年的新 SOTA。
三、GPU 太贵,我选择薅羊毛
现在训练个模型,GPU 显存至少得上 8GB,对应的价格实在有点劝退。
其实,很多大企业都推出了面向研究和实验的免费 GPU 计算资源,例如我们熟知的 Kaggle Kernel、Google Colab,它们能提供 K80 或 P100 这种非常不错的 GPU 资源,其中 Colab 还能提供免费 TPU。国内其实也有免费 GPU,百度的 AI Studio 能提供 Tesla V100 这种强劲算力。
这三者都有各自的优劣势,Kaggle Kernel 与 Colab 都需要科学上网,且 Kaggle Kernel 只能提供最基础的 K80 GPU,它的算力并不大。Colab 还会提供 T4 和 P100 GPU,算力确实已经足够了,但 Colab 有时会中断你的计算调用,这就需要特殊的技巧解决。
百度 AI Studio 也能提供非常强大的 V100 算力,且现在有免费算力卡计划,每天运行环境都能获得 12 小时的 GPU 使用时长。但问题在于,百度 AI Studio 只能调用 PaddlePaddle 框架,而不能自由选择 TF 或 PyTorch。
1. Colab 薅毛要技巧
很多开发者在使用 Colab 时,总会抱怨时不时的终止,抱怨每一次结束后所有包和文件都会删除。但实际上,除了科学上网,其它很多问题都能解决。
首先最大一个问题是 Colab 会断,但小编用过很多次,差不多每次只要保证页面不关闭,连续运行十多个小时是没问题的。按照我们的经验,最好是在北京时间上午 9 点多开始运行,因为这个时候北美刚过凌晨 12 点,连续运行时间更长一些。像 T4 或 P100 这样的 GPU,连续运行 10 多个小时已经是很划算了,即使复杂的模型也能得到初步训练。
那么如果断了呢?这就要考虑加载 Google Drive 了。Colab 非常好的一点是能与谷歌云硬盘互动,也就是说等训练一些 Epoch 后,可以将模型保存在云端硬盘,这样就能做到持久化训练。每当 Colab 断了时,我们可以从云端硬盘读取保存的模型,并继续训练。
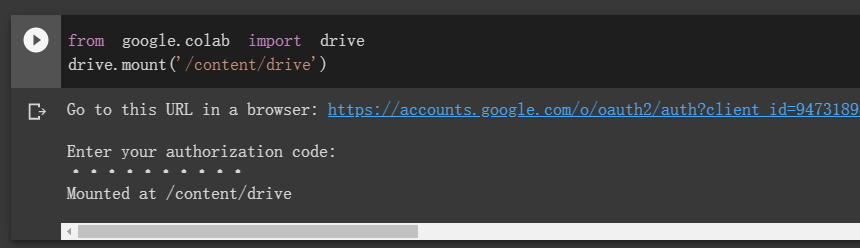
如上两行代码可以将谷歌云硬盘加载到远程实例的「content/drive」目录下,后面各种模型操作与数据集操作都可以在这个目录下完成,即使 Colab 断了连接,所有操作的内容也会保存在谷歌云盘。
只要搞定上面两个小技巧,Colab 的实用性就很强了。当然,如果读者发现分配的 GPU 是 K80,你可以重新启动几次 Colab,即释放内存和本地文件的重新启动,每一次重启都会重新分配 GPU 硬件,你可以「等到」P100。
此外,开发者还探索了更多的秘籍来保证 Colab 连接不会断,例如跑一段模拟鼠标点击的代码,让 Colab 断了也能自己重连:
- function ClickConnect(){
- console.log("Working");
- document.querySelector("colab-toolbar-button#connect").click()
- }
- setInterval(ClickConnect,60000)
2. AI Studio 算力是真强
Colab 的 P100 已经非常不错了,它有 16GB 的显存,训练大模型也没多大问题,但 AI Studio 的 V100 更强大。AI Studio 即使不申请计算卡,每天登陆项目也能获得 12 个 GPU 运算时,连续登陆还能有奖励。
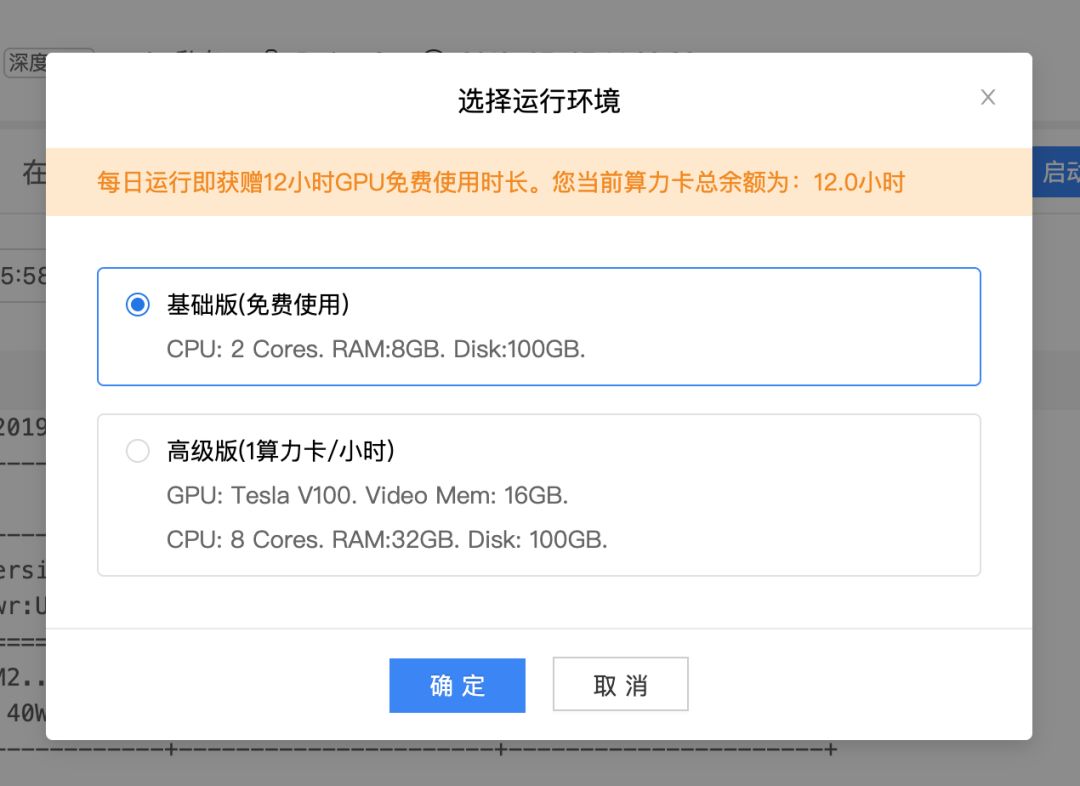
AI Studio 类似 Jupyter Notebook 的编辑界面也非常容易使用,且中断运行环境后保存在磁盘里面的文件并不会删除,这也是 Colab 局限的地方。但该平台只能导入 PaddlePaddle 框架,所以对于熟悉 PaddlePaddle 框架的开发者而言,AI Studio 是最好的免费算力平台。
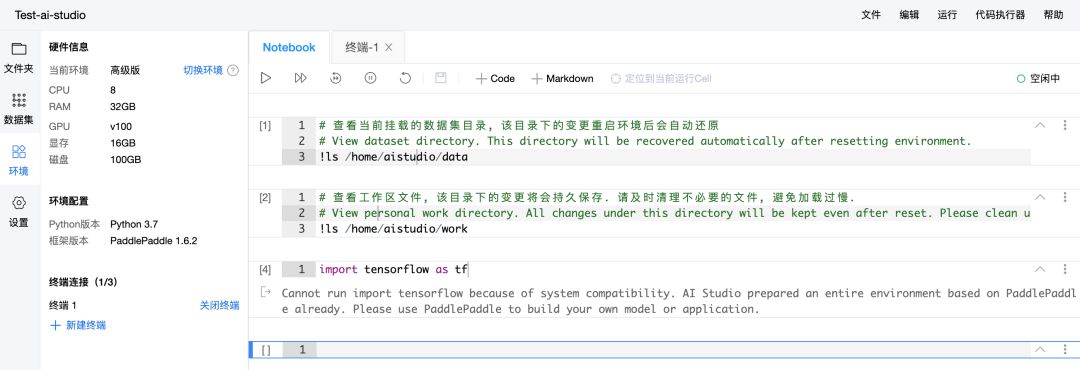
我们尝试了一下,在终端可以安装其他框架,且进入 Python 自带 IDE 后也能导入新安装的框架。但是在 Notebook 界面,会显示只能导入 PaddlePaddle。
最后,看了这么多顶级 GPU 的性能对比,也了解了免费 GPU 计算资源的特性。所以,你是不是该宅在家搞一搞炫酷的深度学习新模型与新能力?
参考内容:https://lambdalabs.com/blog/choosing-a-gpu-for-deep-learning/
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】