由于SSD的实际写入带宽受到业务类型和内部状态的双重影响,因此业界一般会标出在典型工况下的写入带宽。对于用户来说,在系统设计时,4kB随机写入的稳态性能通常被认为是SSD的写入带宽的下限。业界也有很多方法来测试该性能。为了使得测试结果有效,需要在测试前对待测SSD进行清空(Purge)和预处理(Precondition),使得它进入到稳态。
是否可以直接全盘随机写入进行预处理?
在执行4kB随机写入测试之前,通常的预处理包括对于SSD全盘的一次顺序写入和几次随机写入。既然最终的测试是随机性能,为什么在清空后一定需要先进行一次顺序写入再进行随机写入而不是直接通过若干次随机写入使得SSD进入稳态呢?这是由于SSD内部的工作原理决定的:采用上述方法可以最快速度使得SSD进入到随机写的稳态。实际上,SSD在清空后,内部的Flash物理空间被全面释放出来,成为空闲资源。为了使SSD再次进入稳态,需要尽可能向SSD内部写入数据,占据这些空闲的Flash块。只有SSD内部的空闲块基本用完,才能触发它内部的垃圾回收(GC)机制并尽快使得性能下降到稳态。
对于一个容量为1000GB的企业级SSD,存在约15%的超额配置(Over Provisioning),内部的Flash物理空间总共约为1150GB。如果对全盘顺序写入一次,占用的物理空间就是1000GB。而如果采用4kB随机写入的方式,对全盘随机写入1000GB的数据,由于两次写入的位置可能存在重叠,因此虽然占用的物理空间仍然是1000GB,但是这些空间对应的逻辑地址要小于1000GB。那么两者之间的差异到底是多少呢?
为了写入1000GB的数据,采用4kB的写入方式,待写入的空间包含n=1000GB/4kB=2.6×108个4kB的地址。而总计需要写入n次4kB数据。设随机变量Mi=1代表地址i没被写入任何数据这样的事件,对于这n个地址中任意一个,由于所有写入都是独立并且均匀写入到所有地址空间,因此n次随机写入全没有命中指定地址的概率。
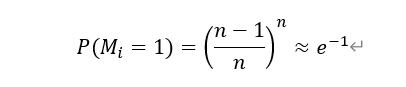
上面的式子利用了 并假设n足够大,其中e=2.718是自然对数的底数。为了计算所有这样的没有任何写入命中地址空间的比例,借助大数定理
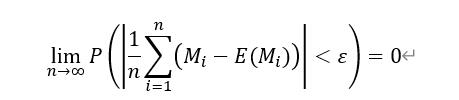
因此,全盘随机写入一次导致从来没有写入数据的地址所占据全盘的比例为e-1,也就是说全盘随机写入一次仅仅相当于写入了1-e-1=63%的地址范围,除此之外37%的地址范围是不包含有效数据仍然处于空盘状态。因此,采用这种方法,即便写入3次,也仍然有5%的地址范围未被覆盖,这相当于凭空增加了5%的超额配置。因此采用全盘随机写入的方法进行预处理的效率是很低的。
有些磁盘性能测试工具可以选择在随机写入的时候指定是否允许写入重叠的地址范围。例如fio在随机写入的时候会记录哪些地址曾经写过,它会避免已经写入的地址重复写入,从而避免了上述填充的效率问题。为了记录已经写入的地址范围,它使用了系统中的一段内存。如果系统内存不足且不需要这个功能,可以通过norandommap开关把这个功能关闭。
该如何加速SSD进入稳态?
而采用先进行一次全盘顺序写,再进行数次随机写的方案,则可以加速进入稳态。这是因为先前的1000GB写入把所有的地址范围全部占用了,在此基础上的随机写入则会占用多余的超额配置空间,使得SSD尽快启动垃圾回收并进入到稳态。此外,写入同样的数据量,顺序写入要比随机写入快不少,可以提高预处理的效率。
在这个过程中,我们甚至可以观察到SSD的写入带宽从顺序写的较高性能,先跌入到一个谷底而后再逐渐恢复到随机写的稳态性能。这个带宽的谷底又是怎么回事?这仅仅是由于SSD垃圾回收采用了惰性策略导致不及时进行垃圾回收所致吗?

实际上,这个性能的低谷才是SSD写入性能的下界。这个谷底的产生是因为写压力从顺序转换成随机,导致Flash物理块的淘汰策略发生切换所致。由于之前的压力为纯顺序写入,在SSD内部物理数据块的淘汰采用了论资排辈的先写入先淘汰的方法,而一旦切换到随机写入,原来这些“年龄”偏大的物理块不再被继续选择出来淘汰,而新的写入方法尚未建立起稳定的待回收的数据块供应,因此这个时候所有等待回收的物理块中有效数据全面偏多,造成性能的谷底。
小结
这就好比在2000年的时候,通信行业非常火爆,院校里通信和电子类专业非常热门。但是等这些专业学生毕业的时候,通信行业的需求已经有饱和的趋势,而计算机则成了新的热门,再往后是金融。如果处在选择专业的高中毕业生只关注当下的行业需求,缺少对未来的分析和判断,那么往往选择的专业在就业的时候就成为了明日黄花,只有有了预判能力,才能把握住时代的需求。对于一个有预判能力的SSD,就应该根据用户业务类型和内部的数据块中有效内容的分布规律,提前和合理安排垃圾回收,才能避免这个写入性能的谷底,保持一个接近全盘随机写的性能下限。