导读:InfluxDB是最常用的时间序列数据库之一,大家广泛使用其开源版本。然而其开源版本缺乏一些高可用相关的特性,本文介绍Hulu在使用InfluxDB的过程中碰见的问题和解决方案,十分值得一读。
随着Hulu的持续增长,时间序列数据库已成为公司监控系统的关键部分。 这可以像机器性能指标或应用程序本身的数据一样简单处理。 由于我们拥有的数据量很大,因此创建一个支持冗余和可扩展的体系结构至关重要。
为什么时间序列数据很重要?
时间序列数据使我们能够评估趋势,以便发现问题并采取措施。
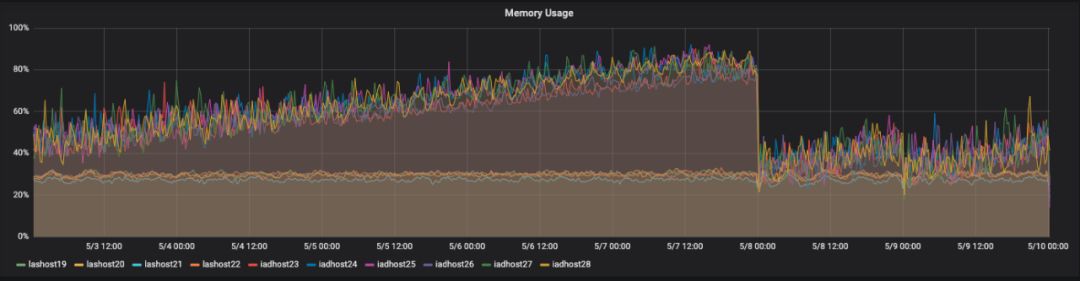
下图用于确定最近的内存泄漏,该问题会影响在特定数据中心运行的应用程序版本。
Graphite 架构
最初,每个开发团队都有自己的时间序列数据解决方案。 由于大多数团队都有类似的需求,这种情况无疑是浪费资源的。 为了解决这个问题,我们建立了原始的时间序列数据管道,该管道为整个工程团队提供了时间序列数据库。
该管道基于Graphite,并将数据存储到OpenTSDB。 在高峰时,该Graphite集群的吞吐量为每秒140万个指标。 在维持这一流程的同时,我们遇到了许多问题,这些问题随着我们继续增长而变得越来越常见。
其中许多问题源于为Hulu所有开发团队提供数据管道共享服务, 这样就需要支持巨大吞吐量和基数,其他问题是来自于可伸缩性的固有问题。
数据管道遇到的挑战
使用方经常且无意间会在其标准名称空间中发送唯一数据,例如时间戳或另一个唯一标识符。 例如:
- stats.application.dc1.1557471341.count 1 1557471341
- stats.application.dc1.1557471345.count 1 1557471345
- stats.application.dc1.1557471346.count 1 1557471346
这导致了命名空间中基数爆炸式增长,从而影响了接收速度和整个管道的稳定性。尽管可以阻止这些行为,但是这样做非常困难,因为需要匹配有问题的指标,而不能影响合法指标。
由于吞吐量的限制,我们在创建规则的复杂性和数量方面受到限制,因为必须针对接收到的每个指标使用所有规则进行评估。这需要在指标数据涉及的许多节点上以滚动的方式完成。因此通常很少会添加条件来阻止有问题的指标,一般倾向于让应用程序停止发送指标。不幸的是,在大多数情况下,花费的时间导致数据丢失。
检索数据时,许多用户会无意中运行很长时间或占用大量资源的查询,这最终将导致为其提供数据的后端超时并宕机。没有叫停这种行为的限制,这也影响了整个系统的稳定性。
发送的指标也是有问题的。由于格式并没有标准化,因此找出哪个服务正在发送特定指标需要进行大量猜测,而在我们实际需要这样做时非常困难。
最后,由于我们的设置,所有指标都被发送到了两个数据中心之一。如果发生故障,则整个数据中心的指标将无法访问。此外,由于我们只有一个统一的接口来检索这些指标,因此我们优先于一个数据中心。这是有问题的,因为如果用户向第一个优先级数据中心发送了一个指标,但随后决定使用另一个数据中心,由于第一个数据中心已经存在命名空间,因此将无法访问他们的新指标,从而导致问题。
InfluxDB初始架构
为了解决这些问题,我们决定基于InfluxDB从头开始重新构建统计数据管道。 对于我们的第一次尝试,我们创建了两个集群,在两个主要数据中心(DC1和DC2)中各有一个。 两个群集将包含相同的数据。
在此基础上构建了一个指标中继群集。 所有指标都将发送到中继群集。 该集群的唯一目的是将收到的所有指标推送到两个InfluxDB集群中。 这样就可以从任何数据中心检索所有指标,从而完全消除了在Graphite体系结构中遇到的指标可用性问题。 我们在每个数据中心都有指标中继层。
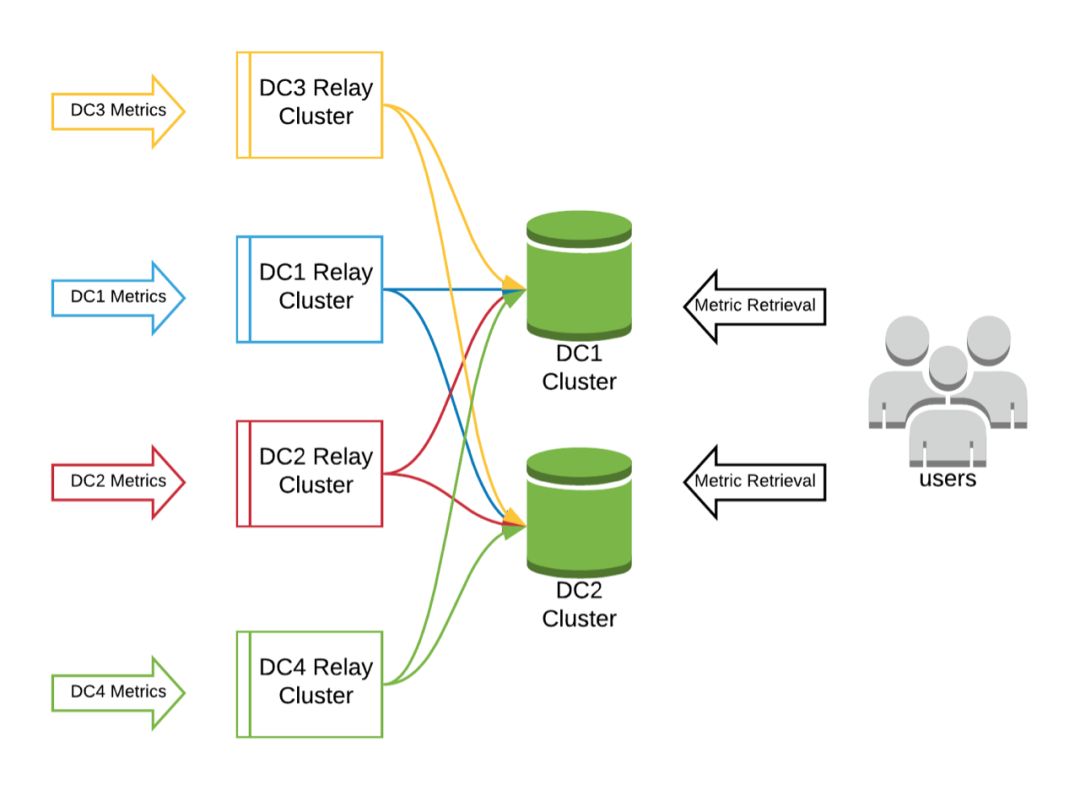
在此指标中继层上,我们还实现了必需标签,这是Hulu中每个应用程序的唯一标识符。这使我们可以轻松地追溯每个指标的来源。没有此必需标签的所有指标都会被删除。
Hulu的所有机器上都运行了Telegraf守护程序(https://github.com/influxdata/telegraf)。 我们已将该守护程序配置为报告所有计算机统计信息,并且还监听localhost上的指标。我们鼓励所有开发人员将指标发送到localhost,因为我们已将Telegraf配置为自动为其接收的所有指标添加标准标签。这些标签包括原始数据中心,计算机名称和计算机ID。
此设置效果很好。我们测试过大于每秒200万个指标的吞吐量,没有任何问题。然而我们很快遇到了一个问题,导致我们重新评估了当前设置。
具体来说,我们的一个集群在一段时间内不可用,导致所有指标仅被推送到单个(在线)数据中心,然后在被复制到另一个集群之前被丢弃。一旦有问题的群集再次可用,数据就会出现差异,需要手动重新同步群集。我们意识到我们需要一种方法来更优雅地解决此类问题,并减少人工干预。
InfluxDB改进架构
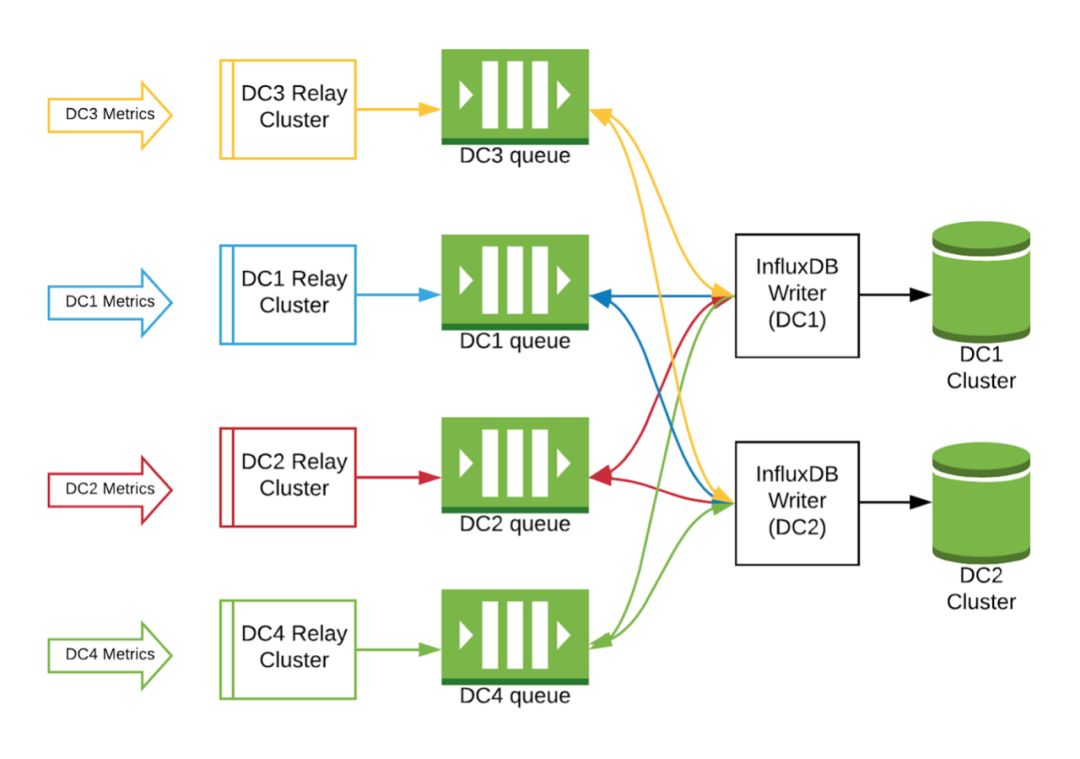
我们在设计中创建了两个新层,其中包括每个数据中心内的Kafka队列,以及一个InfluxDB writer层以解决此问题。
指标仍会发送到原始中继群集,但不再从那里直接路由到InfluxDB群集。而是将其发送到数据中心内的Kafka队列。
InfluxDB writer层是在InfluxDB群集所在的每个数据中心中创建的。该层的唯一目的是连接到所有数据中心中的Kafka队列,并将它们写入其本地InfluxDB集群。如果其中一个InfluxDB集群发生故障,则该数据中心内的writer将停止向该集群写入数据,但另一个数据中心将继续提取其指标。一旦有问题的群集重新联机后,该数据中心内的writer将继续工作,并写入本地的群集。最终两个群集将再次处于一致状态。
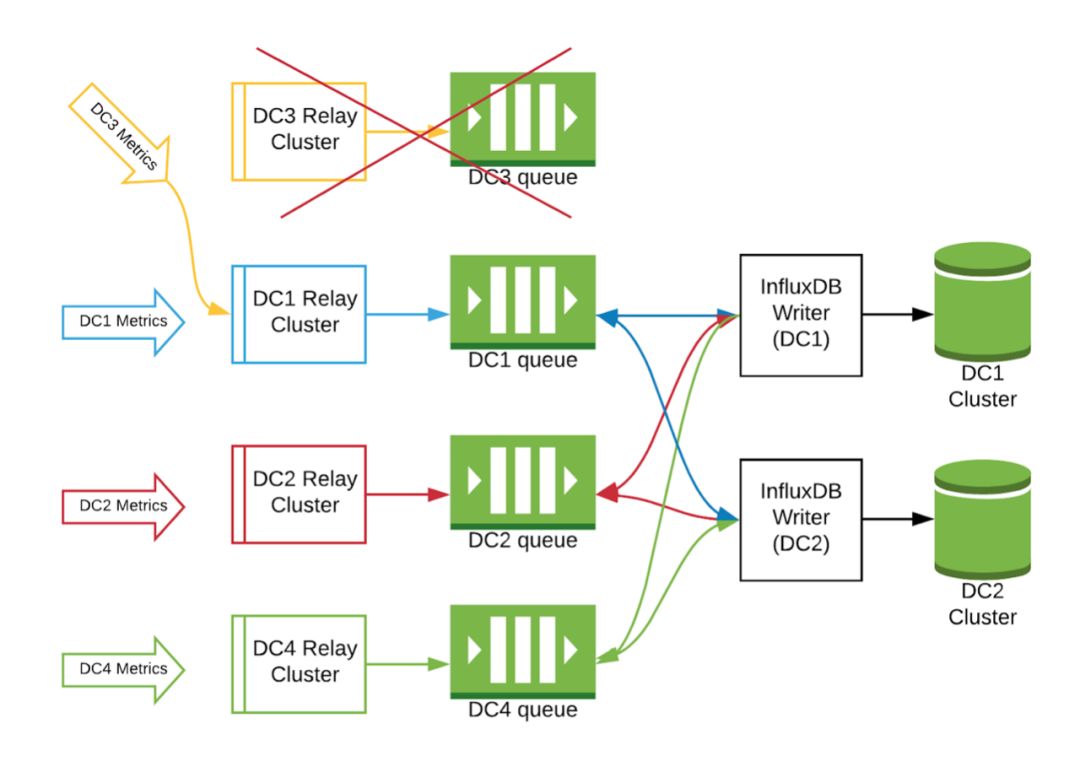
这种设计还使我们能够完全禁用大部分基础设施(甚至整个数据中心),并将它们路由到另一个数据中心,而对最终用户没有任何影响。
虽然此设计解决了我们的许多问题,但是依然有两个问题没有解决。
查询限制
我们仍然遇到长时间运行的查询或者说有问题查询的问题。 使用者有时会进行很长时间的查询(通常是偶然的),这会导致其他用户使用时的性能下降。 我们为此目的创建了一个新的微服务Influx Imposer。
该应用程序登录到我们的两个InfluxDB集群,并每分钟检查一次正在运行的查询。 如果超过某些阈值(例如60秒)或是危险/资源密集型查询,则将其杀死。 我们还实现了终止查询的日志记录,并且已经大大提高了系统稳定性。
阻止/过滤“不良”指标
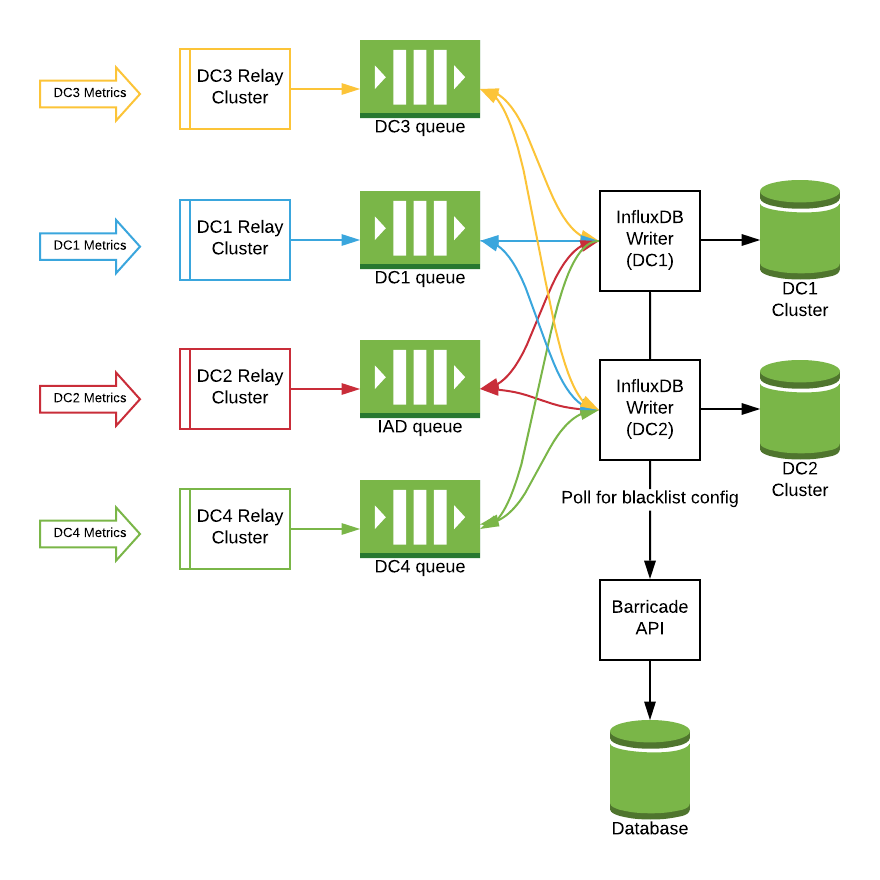
使用者可能仍会在命名空间中发送带有时间戳的指标,或者发送一些可能导致数据集基数非常大的数据。 为了解决这个特定问题,我们创建了另一个名为Barricade的微服务。
Barricade是由数据库支持的API,其中包含动态黑名单。 如果任何时候需要将标签,指标或几乎任何其他信息列入黑名单,都会将其添加到此数据库中。数据库更改将同步到InfluxDB writer上的所有本地配置。 这些机器不断轮询Barricade以获取其更新的黑名单规则。 如果检测到更改,则writer将重新生成其本地备用配置。 之所以在InfluxDB writer层执行此操作,是因为该层上的任何更改都不会导致指标获取中断,因此添加新的黑名单对上层查询是没有影响的。
时间序列数据一直是并将继续是Hulu评估趋势并对之做出反应的能力的重要组成部分。 我们能够解决先前管道中的所有问题,现在正在将所有用户移出旧平台。 在撰写本文时,我们的新统计信息流已经处理超过每秒一百万个指标,并且这个数据每天都在增长。