环境的搭建和安装网上有很多教程,在这里就不再重复了。
1. Redis 是什么?
Redis (全称: Remote Dictionary Server 远程字典服务)是一个开源的使用 ANSI C语言 编写、支持网络、可基于内存亦可持久化的日志型、 Key-Value数据库 。
大家可能知道 Redis 是做缓存用的,它实际上也是一种数据库,可以对经常使用到的数据进行存储,也就是大家所说的缓存。
官方给出的数据是, Redis 能达到 10w+ 的 QPS( 每秒查询速度 ) 。
为什么 Redis 的速度比 Mysql 等这种数据快呢?
因为 Redis 存储的是 key-values 格式的数据,时间复杂度是 O(1) ,即直接通过 key 查询对应的 value 。 而如 Mysql 数据库,底层的实现是 B+ 树,时间复杂度是 O(logn) 。
最重要的一点是,数据库的数据是存储在磁盘中的,而 Redis 是存储在内存当中的,它们的速度差距不言而喻。但 Redis 也支持持久化存储,这个后面的常见问题里会提到。
2. Redis 数据类型
Redis 支持 5 种数据类型: string (字符串)、 hash (哈希)、 list (列表,有序可重复)、 set (集合,无序不可重复)、 zset (有序集合,有序不可重复)。
Redis 中所有数据都是字符串, key 是区分大小写的。
- string 是最基本的类型,可以包含任何数据,但是 string 类型的值最大能存储 512MB 。
- hash 的 value 相当于一个 map , value 里面也有对应的 key-value ,特别适合存储对象。一个 hash 可以存储 2^32-1 个键值对,基本用不完。并且可以修改某一个属性值,所以一般用于存储用户或其他实体类的值。
- list 中的 value 按照插入顺序排序,可以在列表的头部和尾部添加新元素。一般用于最新消息的排行或消息队列。
- set 存放的是不重复值的集合,是无序的。并提供了求交集、并集、差集等操作,所以一般用于统计等功能。
- 与 set 不同的是, zset 是通过分数( score )从小到大进行排序的,我们可以指定每个值的分数,分数可以重复。一般用于排行等功能。
3.Redis常用命令
基于对上面 5 种数据类型的了解,接着学习一下 Redis 常用命令。更多了命令学习,推荐大家看一看官方文档 http://www.redis.cn/commands.html
(1)对stirng的操作
redis命令不区分大小写。
下面命令中,str就是key,hello就是value,append为追加命令,如果原来没有str,就新建一个。
append str hello //对key为str的键追加hello字符串append str redis //str的value变为helloredisset str1 1 //set命令设置一个key的value值 str1是key,1是valueget str1 //get命令,获取一个key的值 incr str1 //incr命令,执行加1操作,比如str1的值会变成2,如果指定的key的value不能表示一个整数,就会返回一个错误decr str1 //减一操作- 1.
(2)对hash的操作
上面说到过,hash的value相当于一个map,所以只设置值的时候myhash是key,h1是value里面的key,hello是h1的value
hset myhash h1 hello //设置一个key的value值hget myhash h1 //返回hello,myhash为key,h1是value里面的key,两个都需要指定hlen myhash //获取myhash的字段数量,这里返回1hkeys myhash //获取myhash所以字段,这里返回h1- 1.
(3)对list的操作
mylst是key,a,b,c,d都是value,并且有顺序,所以实际存进去后是d,c,b,a
lpush mylist a b c d //lpush,从队列左边入队一个或多个元素lrange mylist 0 -1 //获取指定范围的值,从0开始,-1代表全部,注意这里返回d,c,b,a。rpush mylist 1 2 3 //从右边入队,再次lrange的话就是d,c,b,a,1,2,3lpop mylist //从左边弹出一个元素,这里弹出d,此时的mylist就没有d了- 1.
(4)对set的操作
如果我们添加了重复的元素,不会报错,但只会存一个。如a b b,只会存a b
两个集合之间不受影响,即key为myset和myset2两个集合里面都可以有a b
sadd myset a b c d //添加一个或多个元素到集合里面smembers myset //获取集合里所有元素,输出是无序的,随机的。这里可能是b,d,c,asrem myset a c //移除myset中的a和c元素,由于不可能重复也没顺序,所以可以直接指定元素值来移除- 1.
(5)对zset的操作
myzset为key,a b c前面的数字就是score
zadd myzset 2 b 1 a 3 c //添加一个或多个元素zrange myzset 0 -1 //获取指定范围的值,0开始,-1代表全部。这里返回a,b,c- 1.
更多的命令可以看上面网站中的文档,写的非常详细,下面的常见问题中也会提及一些。
4.Redis常见问题
(1)在大量的key中查询某一固定前缀的key
在实际的业务当中,key的命名是有规范的,比如缓存用户信息,key的前缀可能会是user。
现在有几千万条数据,查询user为前缀的key的话,第一下想到的可能会是keys命令
keys user* //user*为正则表达式- 1.
其时间复杂度为O(n),虽然性能也算可以,但是在查询几千万条数据时明显太慢了,花上几分钟都不稀奇,而且在查询出来之前,可能会造成服务卡顿,占用大量内存,显然是不可取的。
那么这种情况就可以使用scan命令
下面的命令中,math count为可选项,可用可不用,所以需要显示的写出来。math意味后面会匹配一个正则表达式。count代表一次查询10条。
这个10条不是强制的,可能会比10条少。
scan 0 math user* count 10 //从0开始,查询user为前缀的key,一次查询10条并返回- 1.
执行上面一句话后,会返回两个东西,一个游标,代表执行到哪了,比如执行到了14325。返回的另一个就是user为前缀的key了。
下次再执行这条语句时,把0换成14325,接着上次的位置继续查询。但是游标不一定是递增的,也许下次的游标比这次还小,所以存在重复的隐患。
我们可以在业务代码处循环查询,记录每次返回的游标,并把查询的key存入到set当中,起到去重的效果。
scan,实际上就是分批查询,速度显然没有keys快,在查询大量数据时,不会对服务器造成压力。数据量不大时依旧推荐keys。
(2)利用Redis实现分布式锁
首先了解什么是分布式锁。即控制分布式系统访问共享资源的一种方式。
比如系统(或主机)A和B都需要访问资源DataA时,当A先访问到了DataA,这时候就需要分布式锁来把B挡住,防止A和B彼此干扰,保证数据的一致性。
额外提一点就是,Redis命令的操作是原子性的,原子性在数据库的事务中有体现,Redis的命令也是原子性的,要么执行要么不执行,不会出现一个命令执行到一半失败了,但还是改变了数据的问题。
实现分布式锁,需要解决一下几个问题:
1.互斥性,即任意时刻只能有一个客户端获取锁。
2.安全性,锁只能有持有它的客户端删除,不能由其他客户端删除。
3.死锁,即由于某些原因,一些客户端出现问题不能及时释放锁,导致其他客户端也不能获取锁。
4.容错,当某些Redis节点出现问题时,客户端也要能获取到锁。
我们可以用setnx实现锁的功能。语法:setnx key value
仅当key不存在时,才会设置成功。成功返回1,否则返回0。
1.在对应的访问资源的业务代码处,对指定的key设值,如果成功了,则代表没有其他线程执行过这段代码,也就是没有其他线程访问这个资源。
如果设值失败,就代表有其他线程占用该资源,就一直等待,直到setnx成功。
2.还有个问题就是,这个key是长期有效的,所以还需要用到expire命令,语法:expire key seconds,seconds单位为秒,用以设置对应key的过期时间。
上面两步似乎好像是实现了锁的功能,但是缺陷也非常明显,如果成功设值后,在我设置时间之前客户端就出现问题了怎么办? 用两个命令实现一个功能有悖于Redis的原子性 。
在Redis2.6.12版本开始,set有两个参数,就是实现了以上两个功能。虽然上面两步分开的做法是错的,但是思路是一样的。
具体语法: set key value ex 10 nx 。ex代表过期时间,这里设置10秒过期,nx代表key是要唯一的,即一个命令实现了以上两个步骤。
最后还有一个小问题,如果不同资源同时设置了锁key,过期时间也是一样的,到期后Redis同时删除大量key时,难免会出现卡顿。
解决方法就是在设置过期值时加上随机值。
3.利用Redis实现消息队列
消息队列,简称MQ,即消息和队列两个单词的首字母缩写。常见的消息队列有RabbitMQ和RocketMQ等,利用Redis实现消息队列只是熟悉下其特点,实际当中一般会使用专门的消息队列中间件。
如果之前没了解过消息队列,建议搜索一下消息队列相关知识进行一下简单的学习。
简单地说,消息队列的作用就是接受客户端的请求,然后对这些请求依次处理,一般应用请求量特别大时,比如秒杀抢购等。上面介绍数据类型时就说到了list一般用于消息队列。
看一下list的常见操作,虽然叫做列表,但其特点和数据结构的队列基本一模一样。所以在用Redis实现消息队列时,首先肯定会想到list。
1.利用list的话,仿佛 使用rpush生产消息,lpop消费消息 就行了。但是有一个小问题,lpop不会等待rpush的,当rpush还没来得及生成数据时,这时lpop会直接返回null的。
2.既然要等待rpush生成数据,难免又会想到一个命令blpop,其语法为:blpop key seconds。 和lpop功能一样,但是会等待指定的时间,这段时间内rpush如果生成数据的话,blpop会及时返回。
3. 但是blpop的缺点也很明显,当然这个缺点也存在于lpop当中,就是blpop执行完后,代表出队,rpush生成的这条消息就没了,而消息队列中有的需求是需要多个消费者去接收的。
这时候就可以用上 Redis的订阅者模式 ,Redis客户端可以订阅任意数量的频道(Topic)
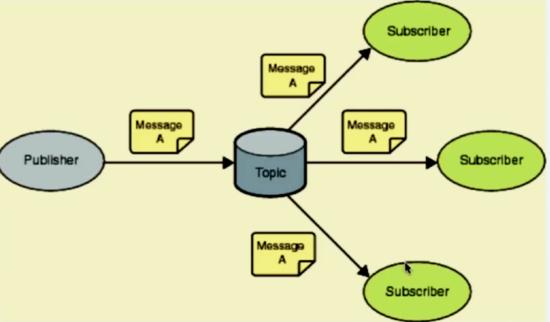
在Redis当中用subscribe命令订阅一个频道,语法subscribe topic,topic就是自定义的频道名称,注意是topic不是key, 不需要事先定义,直接订阅就行了。
然后用publish生产消息,语法publish topic value,topic就是你想发布到哪个频道,value就是数据内容,而订阅了这个频道的所有消费者都会接收到消息。 注意是及时收到,不需要你再去手动用命令获取。
订阅者模式,的确解决了以上两种方法的缺点,但是其缺陷也很明显,就是只有处于订阅者模式,也就是监听状态下,消费者才会接受到生产者的消息,也就是及时发送及时接收的,一旦Redis客户端下线,就永远不会接收到这个消息了。
这就回到了前面说到的一句话,实际当中会使用专门的消息队列中间件来说实现这些功能,以上三种方法或多或少可以实现消息队列的功能,但是缺陷也非常明显。
4.Redis如何做持久化
Redis是基于内存当中的,那么肯定就会有疑问了,当我关闭主机或者关闭了Redis,那Redis的数据是不是就全没了。
持久化的作用就是,把Redis的数据存储到磁盘当中,以免Redis的数据丢失。
Redis有两种持久化机制,默认的一种是RDB,另一种是AOF。
1.RDB(快照)持久化会在某个时间点保存全量的数据,快照即针对内存进行的快速读取技术。而这个时间点可以由我们的实际业务进行时间策略配置。
RDB会按照时间周期策略对数据以快照的方式保存到磁盘里,并产生一个 dump.rdb的二进制文件 。我们可以在redis.conf配置文件中save参数查看和配置时间策略。
dump.rdb文件是如何创建的呢? rdb文件可以通过两个命令创建 ,一个是save,一个是bgsave。 要注意这里的save是redis命令,上面提到的save是配置文件里面的参数。
save命令会阻塞Redis服务器进程,直到rdb文件创建完成,一般很少使用。
bgsave命令会fork出一个子进程来创建rdb文件,不会阻塞服务器进程。fork即创建一个与父进程几乎一样的子进程。
bgsave的基本原理:当我们使用bgsave命令时,首先会检查是否存在RDB/AOF子进程正在进行,有的话就返回错误,即当我们第一次执行了bgsave,在执行完之前其他的bgsave会被拒绝执行。
如果没有正在进行的子进程,就会调用redis源码里面的rdbSaveBackground这个方法,然后利用fork创建一个子进程。
RDB的缺点:
1.1.前面提到,在某个时间点会进行全量数据保存,数据量大的话由于I/O而严重影响到性能。
1.2.由于RDB是根据配置文件里面的时间策略进行保存的,如果发生意外情况,那么上次保存到当前时间段内的数据会发生丢失。
2.AOF(Append-Only-File)持久化 会以追加的方式(append)保存除了查询指令以外所有变更的数据,其默认的文件名称为 appendonly.aof 。
AOF持久化默认是关闭的,我们可以 在配置文件当中找到appendonly参数,把它的参数内容改为yes。
前面说到AOF文件会记录所有非查询的所有指令,最后肯定难以避免文件不断增大的问题,最主要的问题是记录的很多数据是不必要的。
比如循环更新一个数100次,AOF会记录这100个过程,而我们只需要最终结果就行了。
所以, Redis提供了一个日志重写的功能解决文件不断增大的问题 ,可以用BGREWRITEAOF命令手动执行。日志重写在服务不中断的情况下也能执行, 其基本原理如下 :
1.使用fork创建一个子进程。2.子进程把新的AOF写道一个临时文件里,并不会依赖现有的AOF文件,只需要读取内存中的数据。这里就优化了很多不必要的数据。
3.主进程这时候会依旧将新的变动写到内存里,也会写到现有的AOF文件里,即使子进程重写失败,数据也不会丢失。4.主进程获取到子进程AOF重写完成的信号后,会把新的变动追加到新的AOF文件里。
5.最后使用新的AOF文件替换掉原来的AOF文件。
如果启用了AOF持久化,Redis启动时会先检查AOF文件是否存在,如果存在就直接加载AOF文件,如果不存在就检查RDB文件是否存在,如果存在就加载,不存在就直接启动Redis。
在Redis4.0之后,推出了RDB-AOF混合持久化方式并作为默认方式,RDB全量保存,AOF增量保存,集成了它们各自的优点。
5.SpringBoot整合Redis
首先在依赖项里面添加redis启动器
spring-boot-starter-data-redis- 1.
然后在配置文件里面进行相关的配置,更多的配置可以看RedisProperties.java源码查看。
spring.redis.host=127.0.0.1 #redis地址spring.redis.port=6379 #redis服务端口号- 1.
最后注入相关的类
//操作的是复杂类型,比如各种实体类@AutowiredRedisTemplate redisTemplate//操作的是字符串@AutowiredStringRedisTemplate stringRedisTemplate- 1.
SpringBoot框架下对Redis的操作不像Jedis那样可以直接使用原生的Redis命令,具体的API大家可以自行搜索相关的文档。
不过推荐使用一些SpringBoot的Redis工具类,工具类会对 RedisTemplate和StringRedisTemplate的方法进行封装,而封装后的方法名和Redis原生命令是一样的。
在这里分享一篇Redis实战电子篇给大家,感兴趣的朋友转发+私信Redis即可获取