












阿里妹导读:在这场抗击新型冠状肺炎的战役中,普通人能做些什么呢?可能「宅」是现在大多数人能作出的重要贡献之一。在这些深「宅」时光里,用手机或电脑打打游戏、追追剧成了很多人暂时忘掉现实的「良药」。可是!正要上分的游戏突然崩了,正演到关键的剧情突然挂掉,最近“某某 app 崩了”带着广大网友都能领悟的痛频上热搜。网友纷纷呼唤程序员小哥哥快上班,其实疫情期间线上流量激增,很多线上应用都面临着巨大挑战……要解决高流量和突发流量这种业务冲击下,线上应用频繁崩溃的问题,首先需要审视企业目前 IT 架构是否能支撑未来的业务发展。
阿里巴巴在多年 双11 高并发,高可用和高客户体验要求背景下积累了相应的技术体系,并赋能罗辑思维等客户,帮助他们落地全链路压测。本文整理自高用户、突发高流量场景下的真实案例,公布阿里在高可用架构建设过程中的实践笔记,期待帮助更多企业从容应对接下来的高流量场景。
你的应用为什么崩了?
非常复杂的服务端
在我们的日常生活中因为 app 侧相对稳定,“崩”一般发生在看不见摸不着的“服务端”(或者叫云端),而这个服务端有多复杂?
以一个较为成熟的云上架构为例,光是阿里云中构建一个在线服务可以用到的云计算基础、安全和企业应用三个分类的云产品数量就达到几乎 200 款。而我们从客户端(App/PC)到达服务端会涉及到的关键节点就有 CDN、动态加速、高防、应用防火墙、4/7 层负载均衡、前后端服务集、缓存、数据库存储、中间件、基础设施层等等,整个链路都面临着不确定性,比如负载均衡中影响流量的产品规格就有 5 个,后端服务的服务规模化问题更是复杂和难以评估检验,这其中任何一个节点出问题都会导致服务不可用,给最终用户一个“崩”的感觉。同样的问题在专有云、混合云和自建 IDC 都有。
如何能有效的全面检验服务端吞吐能力、发现所有问题甚至是做好容量规划,具备对峰值的流控调度能力是所有企业都需要思考和应对的。
没有提前规划的服务能力
如果应用没有对自己的服务能力进行提前规划,没有提前做好关键节点的规划,对线上的应急措施如弹性扩容,线上防护,熔断降级等都不具备,在面对业务突发时,就很难保证核心接口能够稳定对外服务。一旦,出现应用“崩了”的情况下,很多企业无法采取正确的手段,匆匆扩容非但不能解决问题,反而带来更多不可预期的问题,导致“崩了”进一步的恶化。
除去因问题发现、容量规划、流控和熔断降级引起的“崩”外,运维态的隐患问题如故障影响面、配置一致性、监控和根因分析相关工具、复杂的人员组织的高可用程度等,如果没有足够的演练和验证方案,一样会在关键时刻让你的应用出现“崩”的情况。
阿里巴巴工程师的高可用架构建设笔记
下面我们将阿里巴巴工程师在高可用架构建设实践中,积累的真实经验以笔记的形式分享给大家。
架构设计
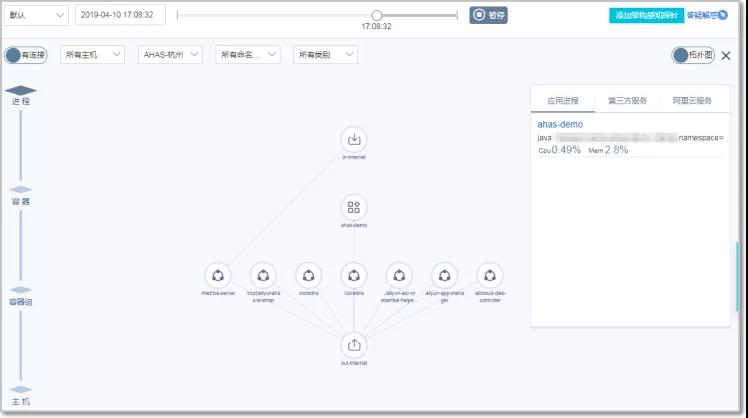
首先要实现架构可视化。利用 AHAS 的架构感知可以全面了解云上系统架构,以可视化的方式直观呈现云资源、容器和应用间分层依赖关系。服务器、存储、网络是现代云平台的基础设施。随着上云战略的推进,越来越多的企业将业务、服务、系统构建在云平台上。
开源软件和云服务的多样性,开发语言的异构性,以及企业 IT 团队的组织和能力差异,都提高了标准化的复杂性。架构感知功能应运而生,通过采集和分析操作系统及第三方标准接口,捕捉进程级的调用关系,并使用特征库算法识别进程所使用的技术组件,最后在服务器、容器和进程这三个维度上以可视化的方式展示应用架构,给用户一张全面清晰的云上架构地图。围绕这张基础的视图,会持续衍生出云资源、容器和应用架构多维度的架构视图,还有搬站、重构梳理和资产管理等场景化的视图,真正做到CMDB可视化,驱动问题发现助推业务增长,释放云上的更多维度的红利。
而关于强弱依赖治理,因为强依赖本身意味着一荣俱荣,一损俱损。结合 AHAS SDK 的引入和预埋,一旦当平台最大吞吐能力到达瓶颈时,除了入口或者web类应用的业务峰值流量限流可以起到第一层的保护作用外,还可以将预先标记为弱依赖的服务平滑下线,从而达到节省更多资源保障核心计算能力的目的,同时还可以去除非核心对核心服务的影响,最终通过合理高效的服务降级最大程度获得业务和成本的平衡。而使用了AHAS SDK之后在编码时,只需要关心如何定义资源,即哪些方法/代码块需要保护,而不需要关注如何保护这个资源。然后通过添加规则来保护资源,规则添加即时生效。
容量规划
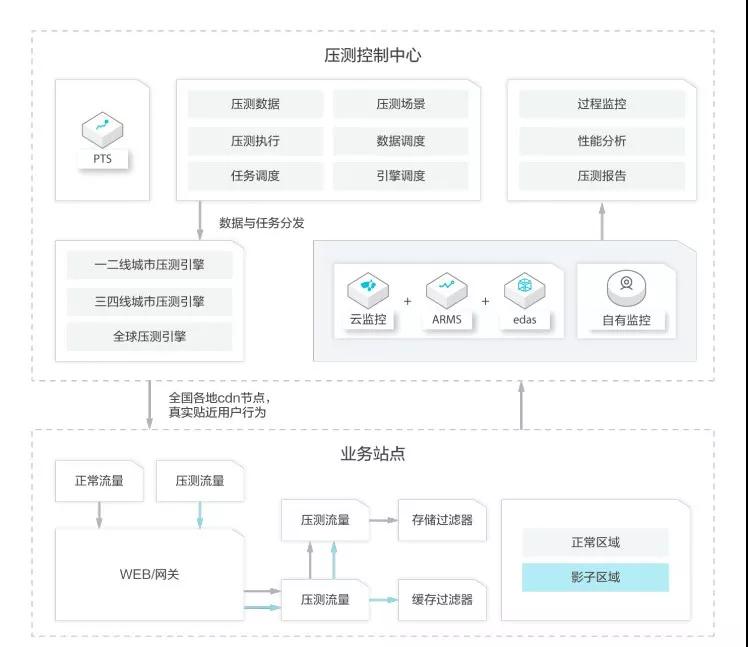
外网仿真压测:首先可以通过 PTS 高效快速构建同模型和量级的业务流量,对于开源主流的 JMeter 脚本可以直接 100%兼容,对于没有现成脚本的情况可以使用PTS自研的可视化交互进行0编码编排,编排完成后从公网的各地域运营商发起,真实模拟特定业务场景下的外网流量,从而全面验证和探测云上或云下整体架构(从网络接入到应用服务内再到存储层和基础设施)的瓶颈和问题。
全链路压测:更进一步的,如果在生产环境想直接精准衡量业务容量的情况,可以通过 PTS 相关解决方案使生产环境具备压测流量识别和路由到指定影子存储区域的能力,结合相关影子存储区域的准备,然后做到同样规模基础数据上的业务流量压测同样的生产环境,最终达到精准衡量线上生产环境的能力,当然,对于压测流水数据由于已经隔离开,所以可以方便安全的清理和维护。
业务监控
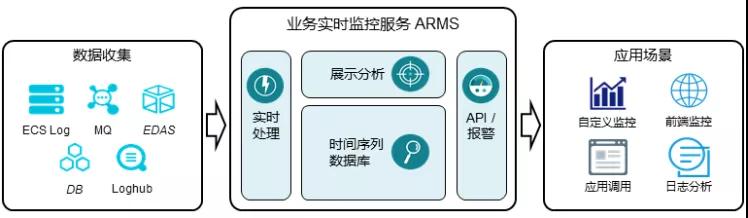
面对复杂的应用环境和高速增长的业务,ARMS 能帮助用户快速构建各种环境下完整的监控体系,实现从页面到数据库、从应用性能到基础架构资源、从 IT 到业务的端到端监控。减少故障排查时间,降低跨部门沟通成本,最终降低因为故障和体验差给企业带来的损失。
线上管控
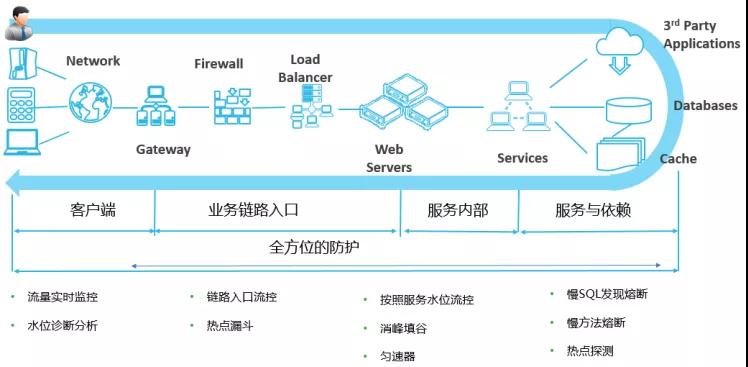
于运行态或已有应用可以通过 AHAS 探针形态(除AHAS SDK外更轻的方案)在不修改代码的情况下进行业务洪峰的流量强力控制、消息场景的削峰填谷,而对于结构复杂的可以将系统内或外不稳定的因素迅速降级让业务保持稳定,同时还有单机过载保护(根据 RT 动态调节入口流量)的兜底能力,甚至很多时候系统来不及压测或者不知道配置什么规则的时候单机智能过载保护是个很好的功能和方法。以上都在运行态和运维侧即可完成引入和控制。对于线上配置项和业务属性值通过 AHAS 开关模块的轻量级方案进行安全和统一管控,这部分能力即将开放,敬请期待。
日常巡检
风险的提前暴露,通过 Advisor 智能顾问对云上主要云资源进行全面的巡检和风险识别,规则都来自于阿里云一线TAM同学面向客户的技术体系积累及阿里生态内 SRE 最佳实践的融合。基于前述的架构地图和用户的输入,可进行更深层次的应用/业务架构层面的巡检和建议。
常态化演练
AHAS 的故障演练模块遵循混沌工程实验原理并融合了阿里巴巴内部实践的经验,基于此用户可以建立流程完整而且可视化程度很高的故障演练体系,可方便的对基础资源、应用服务、容器服务和云平台4层进行超多维度的编排和定制,同时产品还提供了丰富的成熟故障经验库。从而帮助用户实现包括架构、业务、人员的全面高可用提升。故障演练在依赖治理、业务连续性提升和故障修复验证等场景中都有巨大作用。
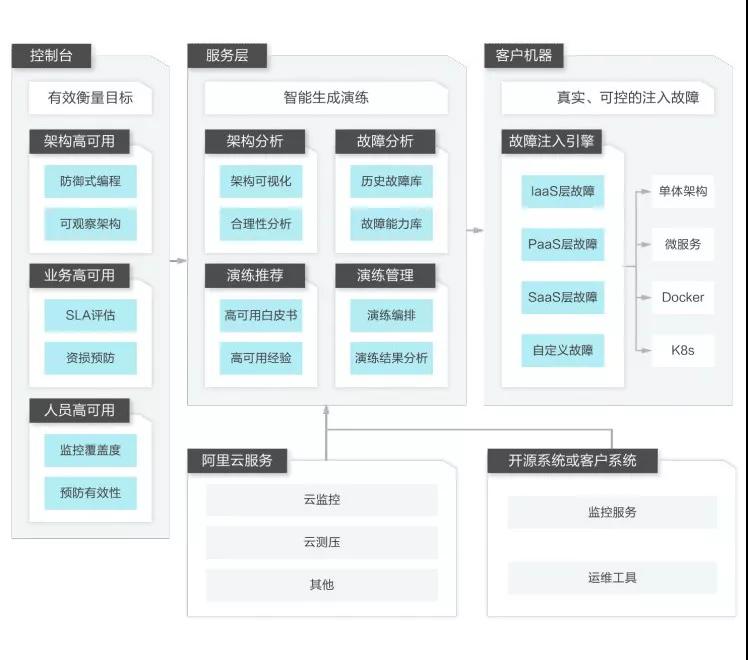
工具一览表
1、应用高可用服务 AHAS
专注于提高应用高可用能力的云工具产品,提供应用架构自动探测,故障注入式高可用能力评测和一键流控降级等功能,可以快速低成本的提升应用可用性。
https://www.aliyun.com/product/ahas
2、性能测试 PTS
面向所有技术背景人员的云化测试工具。有别于传统工具的繁复,PTS以互联网化的交互,提供性能测试、API调试和监测等多种能力。自研和适配开源的功能都可以轻松模拟任意体量的用户访问业务的场景,任务随时发起,免去繁琐的搭建和维护成本。更是紧密结合监控、流控等兄弟产品提供一站式高可用能力,高效检验和管理业务性能。
https://www.aliyun.com/product/pts
3、智能顾问Advisor
智能顾问 Advisor 根据用户情况,结合阿里云长期以来的客户侧最佳实践,基于TAM(Technical Account Management)服务体系的核心基础能力,全方位地为用户提供云资源、应用架构、业务性能及安全上的诊断和优化建议。现在,越来越多的阿里云云原生客户可以通过 Advisor 便捷地享受专业的 TAM基 础服务,更好地用好云。同时,我们也会围绕 Advisor 为有相关需求的客户提供专项深度的 TAM 服务。
https://www.aliyun.com/product/advisor
4、企业级高可用架构解决方案
脱胎于阿里巴巴电商业务下的高可用技术体系经过所有的双11流量洪峰考验、日常稳定性考验,已经服务于阿里全生态并开始服务外部的企业客户,解决方案为企业提供的包括营销活动支撑、整体成本控制(全链路压测、容量规划、流量控制、调度)、应急应对能力(开关和预案)、容灾逃逸能力(架构感知、故障演练、异地多活、单元化)。
https://www.aliyun.com/solution/ehasl
5、混沌测试工具 ChaosBlade
ChaosBlade 是一款遵循混沌工程实验原理,建立在阿里巴巴近十年故障测试和演练实践基础上,并结合了集团各业务的最佳创意和实践,提供丰富故障场景实现,帮助分布式系统提升容错性和可恢复性的混沌工程工具。
https://github.com/chaosblade-io/chaosblade
6、轻量级流量控制框架 sentinel
以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助您保护服务的稳定性。
https://github.com/alibaba/Sentinel/wiki





















