【51CTO.com原创稿件】电子竞技作为近年来竞技体育项目中发展最迅猛的一个独特分支,正在引起大量的社会关注和重视。和其他竞技体育项目一样,电子竞技对于数据的分析和应用有着独特的要求。电子竞技项目中,由于职业玩家和业余玩家的距离更近、业余玩家对于项目的参与度更高,使得其比赛数据的体量和数据分析的技术要求较之传统体育有着几何级数的增长。
本期《大咖·来了》栏目邀请了VPGame CTO 俞圆圆(Y3),进行了主题为《从游戏到科学:AI和电子竞技》的分享,围绕如何利用前沿技术对海量电竞数据进行处理、存储与分析展开。
FunData大数据系统
电竞数据的量级远远大于传统竞技体育,所以VPGame是采用什么技术框架进行处理的呢?下面介绍一下FunData大数据系统以及其ETL层、接口层、数据处理层等部分的具体细节。如下图,为通用FunData大数据系统架构
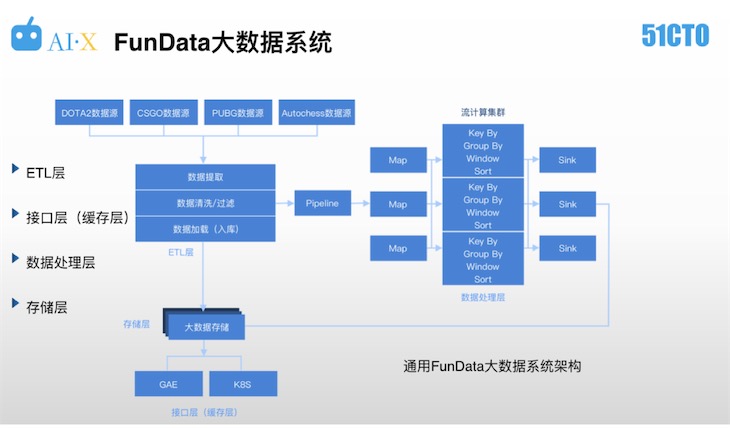
FunData大数据系统分为四层:ETL层的作用是数据提取、清洗过滤和加载,接口层的作用是为前端产品应用提供服务,数据处理层的作用是运用流计算、批计算等方式、对原始数据进行提取,最终得到可用性较高的总结性、概览性数据,存储层作用是对数据进行分级,选取不同的技术方案进行存储。
FunData大数据系统之ETL范式
如下图,为FunData ETL整体范式。
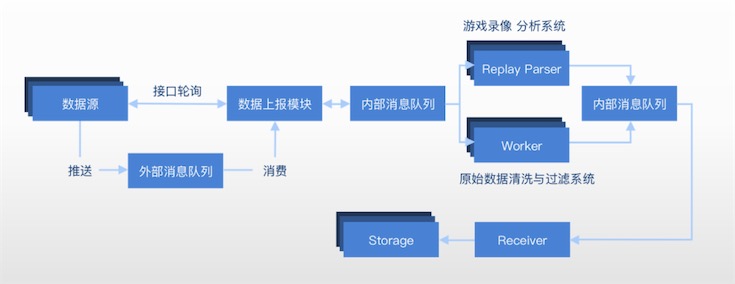
从厂商数据接口、直播视频或录像文件等渠道获取到的数据源,通过外部消息队列推送到据上报模块,由内部消息列队通知不同的数据清洗和分析系统,将原始数据进行分门别类的归档和存储,再次通过内部消息队列一步步将这些数据加载或存入到不同的底层存储服务中。
FunData大数据系统之接口层
如下图,为基于Kubernetes的弹性API系统架构。
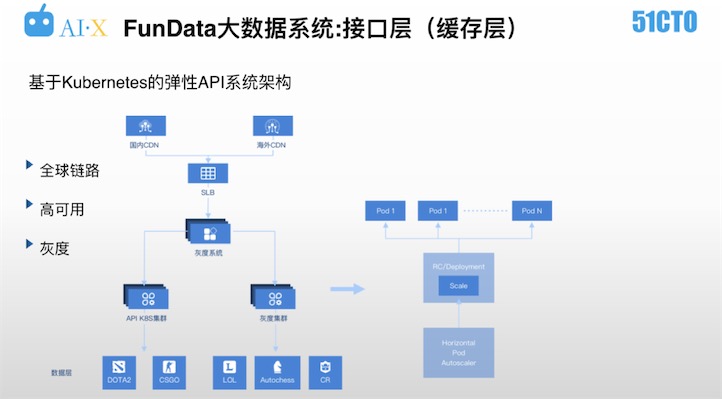
数据要如何运用呢?不管是服务于VPGame应用,还是第三方应用,都是通过基于Kubernetes搭建的API集群实现的。API系统架构不是一成不变的,当不断深入或拓展到其他游戏IP时,会同步进行很多优化,同一个游戏在不同阶段会提供丰富度不同的API,当然整个扩容的过程一定是平滑的。API系统架构一定要具备弹性扩容能力,以便可以很好的应对比赛过程中出现的API请求激增的情况。
FunData大数据系统之数据处理层
数据处理层的挑战在于不同游戏,甚至同一个游戏的不同场景,数据逻辑都是不一样的,所以如果是采用基于虚拟机的单体程序设计的话,对于弹性流量的适应会存在很大困难。如下图,为数据处理层的工作逻辑。
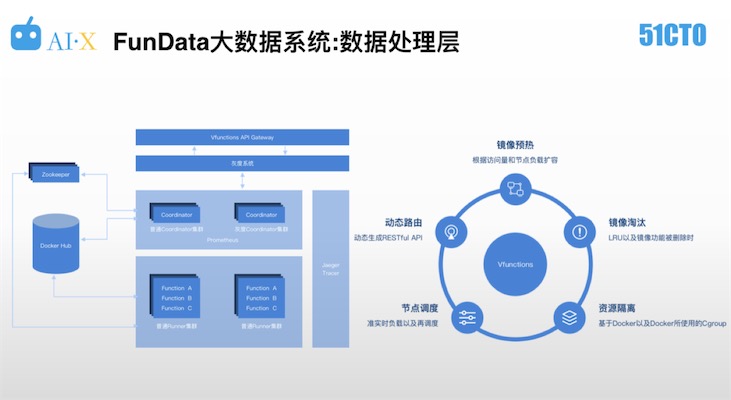
VPGame的数据处理逻辑构建基于Serverless的弹性框架,对实时激增的数据进行处理和计算。于整个框架而言,对业务方的要求仅仅是编写好业务逻辑即可,不必操心容量规划方面的问题。
如下为VM系统与Serverless架构对比图。

VM系统与Serverless架构存在明显差异,主要体现在资源利用率、资源的虚拟化和计算能力等方面。对于VM系统,当访问量增加时需要联系运维新增机器,恢复正常访问量再联系运维减少机器。对于Serverless架构,可以依据实际请求量和机器状况动态分布,统一由Vfunctions管理,不需要运维和业务方的介入。还有就是随时间推移,游戏数据量会存在突刺,热门时间(大赛/节假日)比赛数量激增的情况,原来基于VM的方式处理数据会导致大量数据处理任务堆积,系统压力飙升,部分处理任务超时,不得不人工接入进行扩容。改为Serverless架构,收到新的数据后,由Serverless调度器随机分配一个Worker启动对应的算法容器进行数据处理与提取。
数据处理层还要面对的问题是,不同维度和层面的数据,对于实时性的要求不同,对于资源和时间的计算、处理,其要求也是不同的。这里就需要把处理模块大致分为Hadoop (数据批处理)和Flink (数据流处理)。
批处理的数据一般是全局性的统计数据,如这场比赛出现多少英雄,他们的装备、技能选择等数据,这些数据相对深入,访问频次相对较低,故对及时性的相对要求也不高。但像单局比赛的基础数据,就属于热点数据,需要比赛结束后第一时间进行处理,这里就需要采用流处理框架,保障收到数据后,秒级产出数据结果。以DOTA2单局比赛个人数据处理为例,详见下图。
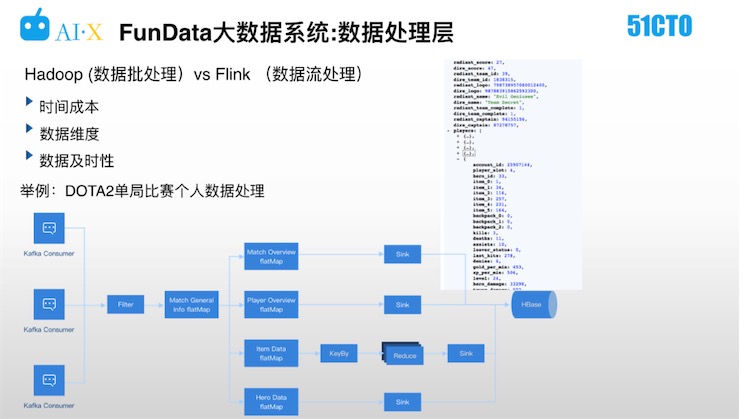
通过消息队列进来的数据信号会知道这些ID有新的比赛产生,接着Filter会把无效的比赛ID过滤掉之后,进一步对数据结构做部分转化,清理不需要的字段,将这些处理流写入不同维度的算子,最后用Reduce算子做一些聚合。
综上所述关于大数据系统的内容为本次分享的第一部分,后面还有对FunData海量存储和基于OCR与机器学习的数据识别和挖掘两部分精彩内容,请戳视频:http://aix.51cto.com/activity/10021.html
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】