之前写过一篇专门介绍HashMap的文章,反响很不错,不过在留言区问的最多的问题就是HashMap的负载因子初始值为什么是0.75,私下又好好地研究了一番,总结了这篇文章。
本篇文章基于JDK1.8,特在此说明。
OK。下面我们就开始进行分析。
一、负载因子的作用
对于HashMap的研究,我之前一直停留在考虑源码是如何实现的,现在当我重新再来看的时候,才发现,系统默认的各种参数值,才是HashMap的精华所在。
负载因子是和扩容机制有关的,意思是如果当前容器的容量,达到了我们设定的最大值,就要开始执行扩容操作。举个例子来解释,避免小白听不懂:
比如说当前的容器容量是16,负载因子是0.75,16*0.75=12,也就是说,当容量达到了12的时候就会进行扩容操作。
他的作用很简单,相当于是一个扩容机制的阈值。当超过了这个阈值,就会触发扩容机制。HashMap源码已经为我们默认指定了负载因子是0.75。
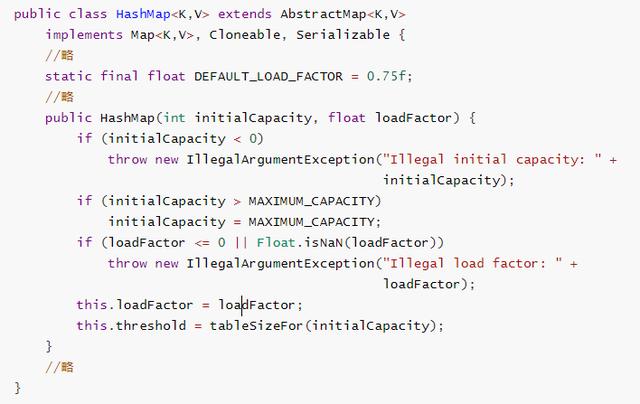
我截取了部分源码,从这里可以看出,系统默认的负载因子值就是0.75,而且我们还可以在构造方法中去指定。下面我们就正式来分析一下为什么是默认的0.75。
二、原因解释(重点)
我们在考虑HashMap的时候,首先要想到的是HashMap只是一个数据结构,既然是数据结构最主要的就是节省时间和空间。负载因子的作用肯定也是节省时间和空间。为什么节省呢?我们考虑两种极端情况。
1、负载因子是1.0
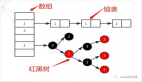
我们先看HashMap的底层数据结构
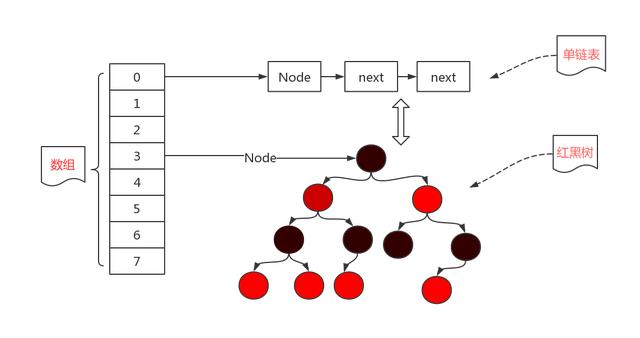
我们的数据一开始是保存在数组里面的,当发生了Hash碰撞的时候,就是在这个数据节点上,生出一个链表,当链表长度达到一定长度的时候,就会把链表转化为红黑树。
当负载因子是1.0的时候,也就意味着,只有当数组的8个值(这个图表示了8个)全部填充了,才会发生扩容。这就带来了很大的问题,因为Hash冲突时避免不了的。当负载因子是1.0的时候,意味着会出现大量的Hash的冲突,底层的红黑树变得异常复杂。对于查询效率极其不利。这种情况就是牺牲了时间来保证空间的利用率。
因此一句话总结就是负载因子过大,虽然空间利用率上去了,但是时间效率降低了。
2、负载因子是0.5
负载因子是0.5的时候,这也就意味着,当数组中的元素达到了一半就开始扩容,既然填充的元素少了,Hash冲突也会减少,那么底层的链表长度或者是红黑树的高度就会降低。查询效率就会增加。
但是,兄弟们,这时候空间利用率就会大大的降低,原本存储1M的数据,现在就意味着需要2M的空间。
一句话总结就是负载因子太小,虽然时间效率提升了,但是空间利用率降低了。
3、负载因子0.75
经过前面的分析,基本上为什么是0.75的答案也就出来了,这是时间和空间的权衡。当然这个答案不是我自己想出来的。答案就在源码上,我们可以看看:

大致意思就是说负载因子是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。
OK,写到这答案基本上就出来了,一句话能总结的写成了一篇文章。如有问题,还请批评指正。