












【51CTO.com快译】在本文中,我们将先介绍数据网格(Data Grid)的基本概念、属性、以及能够提供的服务,然后讨论如何设计可扩展的数据网格,以满足实际场景的业务需求。
什么是数据网格?
数据网格是一组能够提供共享数据管理的服务,它可以通过网格状的结构,去访问源自各种应用程序与服务的异构数据。在技术实现上,我们通常可以采用功能强大的中间件应用程序和服务,实现对于源于各种应用请求的数据输入与查询。
网格中的数据往往可以通过诸如REST、以及JSON格式的API被访问到。这些数据既可以被保存到磁盘上,也能够备份到另一个数据库里。不同的服务可以将JSON格式的数据保存到网格之中,并在不到一毫秒的时间内实现数据查询(类似于缓存)。
以下便是数据网格的基本属性:
- 使用API(基于REST的JSON格式)从网格进行数据访问。
- 其本质上具有真正的弹性,即:可以水平缩放而没有上限。
- 能够支持任何体量的数据。
- 具有耐用性,可应对各种宕机和系统故障。
- 提供低延迟的响应。
它的选配属性则包括:
- 可以利用诸如:JWT、TSL客户端验证等方案,对网格中的每一种数据请求进行授权。
- 能够清除数据,并为更多相关数据留出空间。
- 能够将数据持久地保存到磁盘上。
- 能够从诸如:RDBMS或NoSQL存储等其他数据源,进行数据的热加载(hot-load)。
数据网格的使用
在一个真正的微服务架构系统中,每一项服务都拥有自己的私有数据库(即:每个服务模型都配有一个数据库)。如果其中的任何一项服务需要横跨多个服务获取数据的话,那么我们就需要以诸如:JSON、XML或二进制格式,来处理这些服务的响应。而有些请求既可能使用的是REST标准的HTTP(S)请求,也可能使用SOAP请求,还有可能使用RPC等请求。
不过,真正的挑战并非在技术上,而是在处理诸如安全异常、数据验证、握手、网络、数据解析等失败的情况下,微服务将如何应对。在实际应用中,我们常常会碰到高度依赖性的问题。也就是说:生产者(producer)服务中的任何变更都可能会更改响应的结构,而消费者(consumer)服务也可能需要跟着适应此类变更。如果消费者服务仅从其他服务中查询数据(而非请求任何计算结果),那么该方式则可能无效。
为了解决上述问题,我们引入了数据网格的方法,该方法几乎能够提供任意数量的自定义数据存储,并且具有高度可扩展性和易于维护的低延迟响应。在此,我们将Apache Ignite(https://ignite.apache.org/,以下简称为Ignite)作为数据网格设计中的主要组件之一,由它提供具有持久性、弹性和分布式的内存平台。此外,Ignite还提供了多种缓存选项,可连接RDBMS和NoSQL存储,以及计算服务等功能。
数据定义
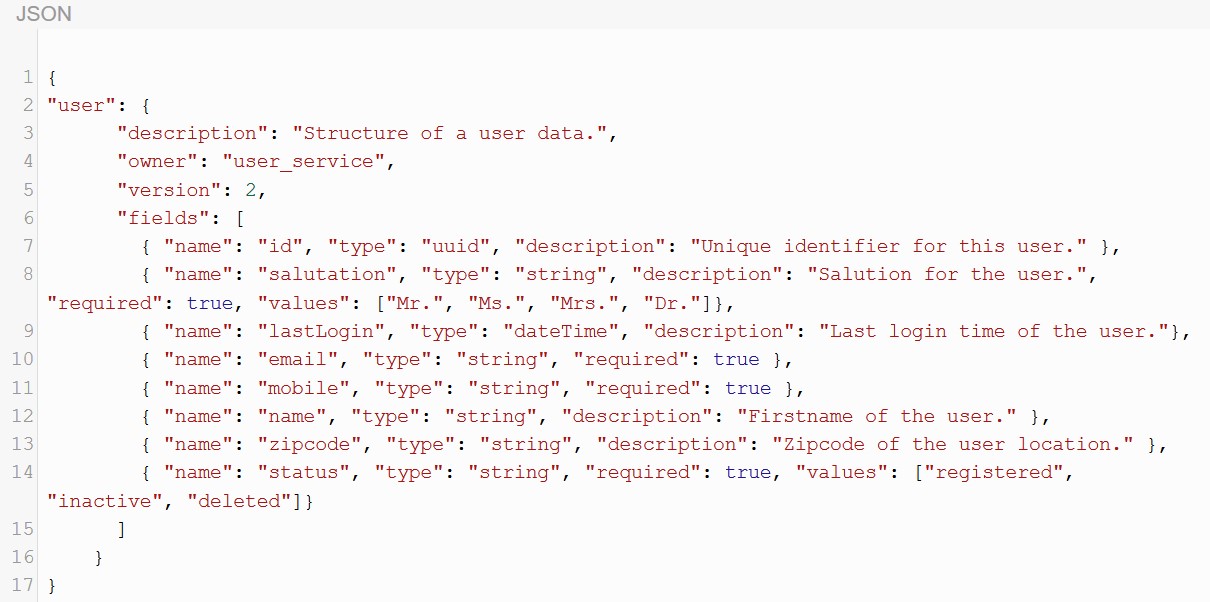
通常,若要为基础架构构建数据网格,所有的微服务都应当发布各自写入网格的数据格式。例如:用户服务(即:管理某个系统中所有用户信息的服务)应当发布所有具有upsert和delete操作的用户信息,以及用户数据结构的定义。同时,此类数据定义应当能够支持版本控制,以便任何新的服务都可以查询到特定的最新版本。据此,所有相关的消费者服务也都可以从“数据网格”中查询到数据定义,进而构建相应的服务功能。以下是一个已发布的用户数据结构(版本1)的代码示例。其对应的URL为:https:///grid/datadefinition&type=user&version=1.

如下是对于用户数据定义版本2的查询代码,其对应的URL为:https:///grid/datadefinition&type=user&version=2.
高级设计
我们可以使用某个在线购物网站为例,来展示数据网格的系统设计。该购物网站是采用各种微服务(例如:用户服务、订单服务、产品目录服务、以及其他服务)来构建的。这些微服务有助于实现从各种目录中订购产品,并最终将其交付给客户。下图是数据网格的完整工作流程。
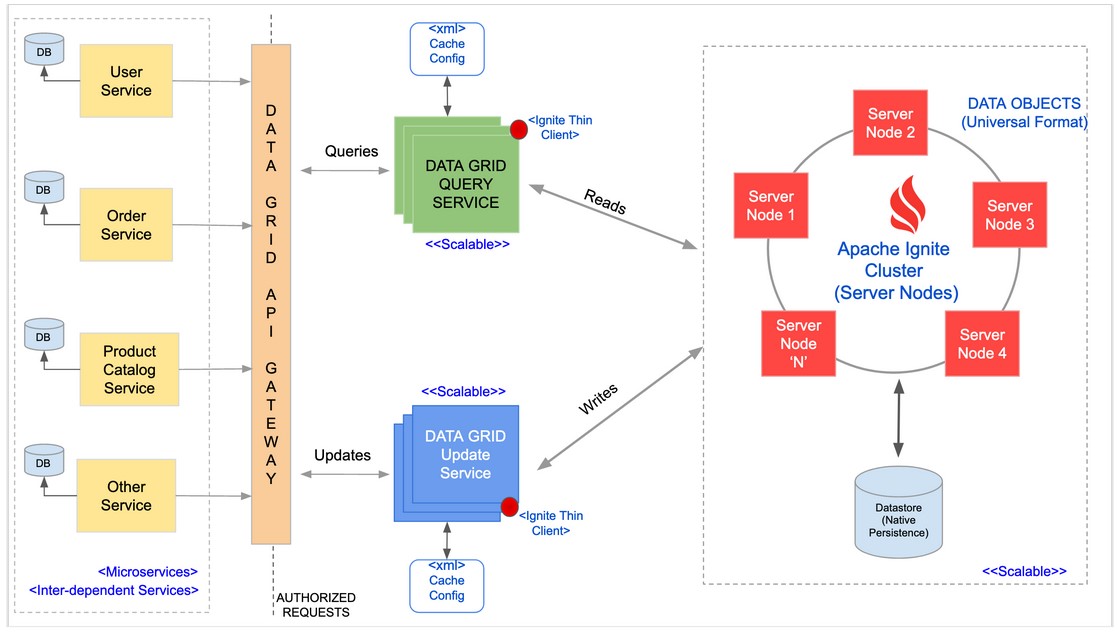
各个组件服务
数据层
这是数据网格的核心,其中部署了Apache Ignite的服务器端模式设置,并构成了“Ignite服务器群集”。在此,Ignite提供了如下可用于构建可扩展网格的功能:
- 通过内存中缓存,实现低延迟的响应。
- 分布式的持久存储。
- 弹性,即:通过添加节点,实现水平扩展。
- 容错,即:数据复制,以及在节点出现故障时的自动负载均衡。
- 针对磁盘或数据库的数据复制和持久性。
Ignite也可以在无主控的架构上工作,并通过拆分其他节点,只向群集组中添加额外的内存内(in-memory)缓存空间。另外,通过Ignite提供的各种缓存配置,您可以按需对其进行调整和增强。此类配置包括:数据持久性选项、缓存的逐出策略、以及数据复制等方面。
数据网格的API网关
该网关可以将查询请求路由到适当服务器上。同时,多个服务也可以被注册到该网关上,以便根据真实的负载,来处理和调节各种请求。
查询服务与更新服务
这是一些大规模的应用服务,可用于查询数据,或将数据更新并添加到数据层,也就是“Ignite服务器群集”上(有关数据层的可视化,请参见上图)。
查询服务设置将使用Ignite的客户端库(即:配置为客户端模式)连接到Ignite服务器群集,并成为Ignite群集拓扑中的一部分。如果这些服务并不会被作为Ignite的客户端节点加入群集拓扑,那么我们可以使用Ignite的瘦客户端(如:Java Thin Client或Node.js Thin Client)去连接到Ignite服务器集群,并执行各种缓存操作。而且,每个服务都能够更新Ignite服务器群集中的一到多个缓存。
将数据推送到数据网格虽然会产生开销,但是我们可以通过使用异步机制,或者将数据推送到某些Kafka的topic上来解决。在此类topic中,数据网格的更新服务(Data Grid Update Service)会将其推送到Ignite的服务器群集之中。
注意:应用服务会使用Ignite的客户端库,来进行各项缓存操作。在默认情况下,它们通过加入Ignite服务器群集拓扑,来充当服务器节点,以参与缓存任务。当然,这并不是必需的。我们需要在Ignite的配置文件中启用客户端模式标志(即:设置为true),或者在应用服务的初始化时,调用某个类似的Ignite API。有关Ignite客户端和服务器设置的更多信息,请参见。
使用数据网格的示例
在上图中,最左侧的组件是微服务,其中每个服务都有自己的数据库。在传统的非数据网格方法中,上例中的订购服务需要针对用户服务,去查询用户的相关信息(例如:用户的电子邮件与地址等)。而在圣诞节、感恩节等销售旺季,此类订购服务可能会遇到大量的交易请求。那么此类订购服务就必须调用相应的用户服务,以获取与交易数量成比例的用户相关信息。
当然,订购服务可以缓存用户的信息,以避免多个网络的调用。或者,为了满足不断增加的用户服务负载,我们还可以向集群添加更多的用户服务节点,以处理各种读取请求。不过,总的说来,数据网格更适合于处理此类业务场景。
当某个微服务有数据更新时,该数据将会被数据网格更新服务推送到数据网格之中。Ignite服务器进而根据缓存配置将数据插入到缓存里。此外,由于Ignite具有持久性,因此我们可以添加任意数量的节点,以支持来自各种服务的大型数据集。这些Ignite服务器群集既可以通过原生持久性来启用,也可以连接到数据库上,以便保留各种缓存数据。
当某个微服务需要访问特定的数据时,它会通过传递必要的查询参数,来使用数据网格的查询服务。由于查询服务连接着Ignite服务器,因此它可以从缓存中查询到数据。当然,如果数据不在缓存中,却已经启用了持久性,那么Ignite则可以从持久性存储中加载相应的数据。
在极端情况下,如果缓存和持久性存储中的数据都不可用,那么查询服务则可以通过内置的逻辑,将请求重新路由到相应的微服务上,以获取数据并将其插入到缓存中。同时,该响应也会将请求发送给消费者服务,以便在下一个请求到来时,直接从数据网格本身获取对应的数据。
由于插入到缓存中的数据是基于更新服务来部署缓存的,因此它确保了在任何微服务中的更新数据,都会在数据网格中可用。此外,由于Ignite具有持久性,因此我们可以添加任意数量的节点,以支持来自各种服务的大型数据集。
总结
本文提供了将消费者服务与生产者服务相解耦的思路,进而让用户能够灵活地向微服务群添加更多的服务,以构建和部署新的功能集。
原文标题:Scalable Data Grid Using Apache Ignite,作者:Sunil P V
原文链接:https://dzone.com/articles/scalable-data-grid-using-apache-ignite
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】

























