导读
2020年才刚刚开始,但我们已经在最新的研究论文中看到了图机器学习(GML)的趋势。以下是我对2020年GML的重要内容的看法以及对这些论文的讨论。
介绍
本文的目标不是介绍GML的基本概念,如图神经网络(GNNs),而是介绍我们在顶级科学会议上看到的前沿研究。
在GML领域有150篇论文提交,有三分之一的论文被接受。这大约相当于所有被接受论文的10%。
我读了大部分GML的论文,以下是我列出的2020年的趋势:
- 对GNN有更扎实的理论认识;
- 最新最酷的GNN应用;
- 知识图谱在变得越来越流行;
- 图嵌入的新框架
我们一个一个来看。
1. 对GNN有更扎实的理论理解
我特别兴奋地看到这一趋势,因为它表明,GML领域的成熟和以前的启发式方法正在被新的理论解决方案所取代。关于图神经网络还有很多需要理解的地方,但是关于GNNs如何工作有相当多的重要结果。
我将从我最喜欢的一篇文章开始:What graph neural networks cannot learn: depth vs width。这篇论文在技术的简单性、很高的实际影响和深远的理论见解之间取得了惊人的平衡。
它表明节点嵌入的维度(网络的宽度,w)乘以层数(网络的深度,d)应该与图的大小n成比例,即dw = O(n),如果我们希望GNN能够计算出流行的图问题的解决方案(如周期检测、直径估计、顶点覆盖等)。
因此,由于层的数量(在许多实现中约为2-5层)和嵌入的维度(约为100-1000层)与图的大小相比不够大,许多当前的GNN实现无法实现这一条件。另一方面,在目前的环境下,太大的网络计算存储代价过高,这就提出了一个问题:我们应该如何设计“高效”的GNN,这是我们将来需要解决的问题。这篇论文还从80年代的分布式计算模型中得到了启发,证明了GNNs本质上也做了同样的事情。里面有更多的结果,所以我建议你去看看。
类似地,另外两篇论文Oono & Suzuki和Barcelo等人也研究了GNNs的威力。第一个是Graph Neural Networks loss expression Power for Node Classification,表明:
在一定的权值条件下,当层数增加时,GCNs除了节点度和连通分量(由拉普拉斯频谱确定)外,什么也学不到。
这个结果是一个众所周知的性质的推广,即马尔科夫过程收敛于唯一的均衡,其中收敛率是由转移矩阵的特征值决定的。
在第二篇论文The Logical Expressiveness of Graph Neural Networks中,作者展示了GNNs与它们所能捕获的节点分类器类型之间的联系。我们已经知道,一些GNN具有与WL同构检验同样强大的能力,即当且仅当两个节点被GNNs分类相同时,它们被WL着色相同。但是GNN可以捕获其他分类函数吗?例如,假设一个布尔函数,当且仅当一个图有一个孤立的顶点时,才将true赋值给所有节点。GNNs能够捕获这种逻辑吗?从直觉上说不是,因为GNN是一种消息传递机制,如果图的一个部分与另一个部分(两个连接的组件)之间没有链接,那么这两个部分之间就不会传递消息。因此,一个推荐的简单修复方法是在邻居聚合之后添加一个读出操作,以便在更新所有特征时每个节点都拥有图中所有其他节点的信息。
其他理论方面的工作包括Hou等人对GNN图形信息的使用进行度量,以及Srinivasan & Ribeiro对基于角色和基于距离的节点嵌入的等价性进行度量。
2. GNN的新酷应用
还很高兴看到如何将GNN应用于实际任务。今年的应用程序包括修复Javascript中的bug、玩游戏、回答类似IQ的测试、TensorFlow计算图的优化、分子生成和对话系统中的问题生成。
在HOPPITY: Learning Graph transform to Detect and Fix Bugs In Programs中。将代码转换为一个抽象语法树,然后GNN对其进行预处理以获得代码嵌入。该思想给出一个处于初始状态的图形,通过多轮图形编辑操作符(添加或删除节点,替换节点值或类型)对其进行修改。为了了解应该修改图的哪些节点,他们使用了一个指针网络,该网络接受图的嵌入和到目前为止的编辑历史,并选择节点。然后,使用LSTM网络执行修复,该网络也获取图嵌入和编辑的上下文。作者在GitHub的提交上验证了这个方法,显示了对其他不太通用的基线的显著提升。类似地,Wei等人的工作LambdaNet: Probabilistic Type Inference using Graph Neural Networks。作者提出了一个类型依赖超图,其中包含作为节点的程序变量和它们之间的关系,如逻辑(如布尔类型)或上下文(如类似的变量名)约束。然后,首先训练一个GNN模型来生成图变量和可能的类型的嵌入,然后使用这些嵌入来预测最有可能的类型。在实验中,LambdaNet在标准变量类型(例如布尔型)和用户定义类型中都表现得更好。
Wang等人的一篇论文Abstract Diagrammatic Reasoning with Multiplex Graph Networks展示了如何使用GNNs在类IQ测试中进行推理(Raven Progressive Matrices (RPM)和Diagram Syllogism (DS))。在RPM任务中,为矩阵的每一行组成一个图,其中的边嵌入由一个前馈模型获得,然后是一个图形摘要。因为最后一行有8个可能的答案,所以创建了8个不同的图,每个图与前两行连接起来,通过ResNet模型预测IQ分数。

DeepMind的一篇论文Reinforced Genetic Algorithm Learning for Optimizing Computation Graphs提出了一种RL算法用来优化TensorFlow计算图的计算代价。图通过标准的消息传递GNN进行处理,该GNN产生的离散嵌入对应于图中每个节点的调度优先级。这些嵌入被输入到一个遗传算法BRKGA中,BRKGA决定每个节点的设备放置和调度。通过对模型的训练,优化得到的TensorFlow图的实际计算代价。

GNN的其他有趣应用包括Shi等人的分子生成、Jiang等人的游戏和Chen等人 的对话系统。
3. 知识图谱变得越来越流行
今年有不少关于知识图谱推理的论文。本质上,知识图谱是表示事实的结构化的方法。与一般的图不同的是,在知识图谱中节点和边实际上具有一些含义,例如演员的名字或电影中的演员(见下图)。知识图谱上一个常见的问题是回答一些复杂的问题,比如“史蒂芬·斯皮尔伯格的哪些电影在2000年之前获得了奥斯卡奖?”,这可以翻译成一个逻辑查询{Win(Oscar, V)∧Directed(Spielberg, V)∧ProducedBefore(2000, V)}}。

Ren等人的论文Query2box: Reasoning over Knowledge Graphs in Vector Space Using Box Embeddings。这种方法允许执行自然的相交操作,即∧连词,因为它有一个新的矩形框结构。然而,建立一个联合,即分离,并不是那么简单,因为它可能导致不重叠的区域。而且,为了准确地使用嵌入建模任何查询,用VC维度量的嵌入之间距离函数的复杂性应该与图中实体的数量成比例。相反,有一个很好的技巧可以将析取查询替换为DNF形式,其中union只发生在计算图的末尾,这可以有效地简化为每个子查询的简单距离计算。

在相同的主题上,王等人提出一种使用数值实体和规则的论文 “Differentiable Learning of Numerical Rules in Knowledge Graphs” *。*例如,知识图谱的引用,你可以有一个规则,influences(Y,X) ← colleagueOf(Z,Y) ∧ supervisorOf(Z,X)∧ hasCitation>(Y,Z) ,即学生X是通过同一个导师Z的同学 Y 影响到的,这个Z具有更多的引用。该规则右手边的每个关系都可以表示为一个矩阵,而寻找缺失链接的过程可以表示为关系与实体向量的连续矩阵乘法,这个过程称为规则学习。由于矩阵的构造方式,神经方法只能在诸如colleagueOf(Z,Y)这样的分类规则下工作。作者的贡献是一种新颖的方式来有效地工作与数字规则,如hasCitation>(Y,Z)和否定运算符,表明在现实中没有必要显式物化这样的矩阵,这大大减少了运行时间。
另一个在机器学习中经常出现的主题是,在今年的GML中,重新评估现有的模型,以及它们在公平的环境中如何表现。就像这篇论文:Ruffinelli等人的You CAN Teach an Old Dog New Tricks! On Training Knowledge Graph Embeddings表明,新模型的性能往往取决于实验训练的“次要”细节,如损失函数的形式、正则化器和采样方案。在一项大型的消融研究中,作者观察到旧的方法,如RESCAL模型,仅通过适当调整超参数就可以获得SOTA性能。
在这个领域还有许多其他有趣的文章。Allen等人展示了模型如何在回答给定查询的Wikipedia图上检索推理路径。Tabacof & Costabello涉及了图嵌入模型的概率校准这一重要课题。他们指出,目前流行的利用s形函数转换对数来获得概率的嵌入模型TransE和ComplEx均校准不足,即对事实的存在预测不足或预测过度。他们的方法依赖于生成不好的三元组作为负样本,而已知的方法如Platt缩放法和isotonic回归法则使用这些负样本来校准概率。
4. 图嵌入的新框架
图嵌入是图机器学习的一个长期主题,今年有一些关于我们应该如何学习图表示的新观点。
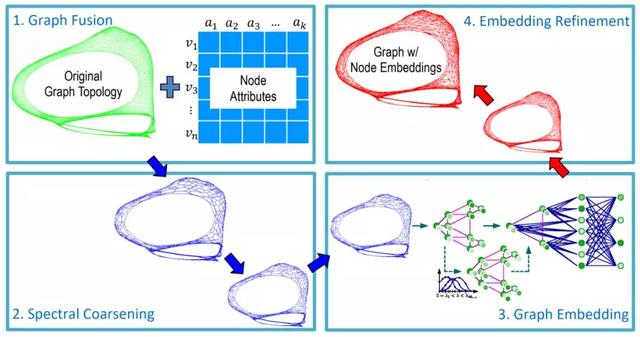
Deng等人在GraphZoom: A Multi-level Spectral Approach for Accurate and Scalable Graph Embedding的总体思路是首先将原始图简化为更小的图,这样可以快速计算节点嵌入,然后恢复原始图的嵌入。首先,根据属性相似度,对原始图进行额外的边扩充,这些边对应于节点的k近邻之间的链接。然后,对图进行粗化:通过局部谱方法将每个节点投影到低维空间中,并聚合成簇。任何无监督的图嵌入方法,如深度步或深度图信息挖掘,都可以在小图上获得节点嵌入。在最后一步中,得到的节点嵌入(本质上表示集群的嵌入)用平滑操作符迭代地广播回来,以防止不同节点具有相同的嵌入。在实验中,GraphZoom框架在node2vec和DeepWalk方法的基础上实现了惊人的40倍加速,准确率提高了10%。
已有多篇论文对图分类问题的研究成果进行了详细的分析。Errica等人的A Fair Comparison of Graph Neural Networks for Graph Classification 的贡献在于GNN模型在这个问题上的公正的重新评估,文章给出了一个简单的基线,不利用图的拓扑结构(它用户节点特征聚合)的表现可以与SOTA的GNNs相当。这一令人惊讶的现象很显然由Orlova等人在在2015年之前发表,但并没有获得大量的读者。这项工作的一个很好的结果是在流行数据集上和在PyTorch-Geometric上的代码基准上的得到了公平的SOTA。在我们的工作 Understanding Isomorphism Bias in Graph Data Sets中,我们发现在常用的数据集如MUTAG和IMDB上,很多图具有同构的副本,即便考虑到节点的属性。此外,在这些同构图中,有许多不同的目标标签,这自然为分类器引入了标签噪声。这表明为了更好的模型性能,使用所有可用的网络元信息(如节点或边缘属性)的重要性。另一个工作, Are Powerful Graph Neural Nets Necessary? A Dissection on Graph Classification,Chen等人表明,如果用线性部分来取代非线性邻域聚合函数,其中包括邻居的度和图属性的传播,那么模型的性能不会降低,— 这与前面的说法一致,即许多图数据集对于分类来说都是不重要的,并且为这个任务提出了适当的验证框架的问题。
总结
随着在优秀会议上的提交率的增长,我们可以预期在2020年GML领域会有很多有趣的结果。我们已经看到了这个领域的转变,从图上深度学习的启发式应用到更合理的方法和关于图模型范围的基本问题。GNNs在解决许多可以通过图表示的实际问题上有它自己的地位,但我希望在一般来说,GML刚刚到达图论和机器学习的交集的表面,我们应该请继续关注即将到来的结果。