这两天,又一个关于新冠肺炎的 GitHub 登上了中文趋势榜的首位,截至目前,已经收获近 5K Star,600+ Fork。
项目介绍
nCovMemory 项目的中文名称是「2020新冠肺炎记忆:报道、非虚构与个人叙述」,创立该项目的目的是为研究人士提供方便自然语言处理、疫情防治取用相关资料的资料库。
资料库中收录了 2020 年新型冠状病毒感染的肺炎相关媒体报道、非虚构作品和亲历者个人叙述。所有的内容均来源于网络,一个完整的条目从可信的信源收录内容,包括日期、标题、原始 URL、截图、archive 等要素,并且暂时不收录评论、分析、科普等类别的作品。
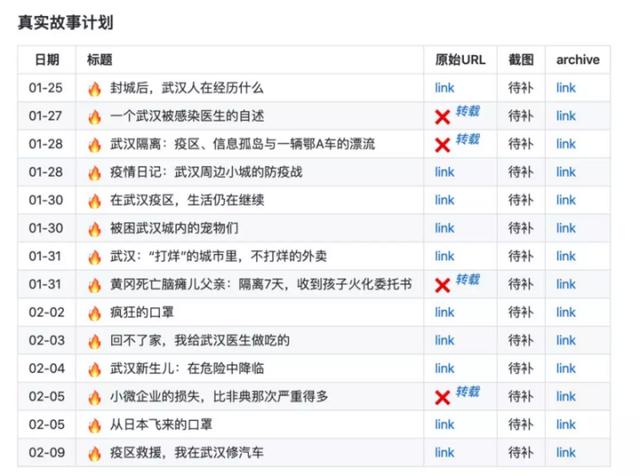
项目的具体结构如下:
├─archive 文章的存档,目前提供jpg格式│
└─jpg│ ├─1.jpg│ └─...├─data
csv格式的文章数据│ └─data.csv├─docs
一个用于展示README的github page├─gh-
page├─template README模板│
└─README.handlebars├─utils 构建README
的工具│ ├─generateReadmeFromCsv.js│ └─...└─README.md
主文档
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
项目意义何在?
毫无疑问,这次的疫情已经成为了一场全民战争。从最开始的武汉加油到现在的中国加油,我们不停的讨论着疫情的发展。
我们会为在疫情中失去生命的人员痛惜,为医护人员、抗疫一线人员的奉献精神所感动;我们会自我隔离、随时佩戴戴口罩,这些都是我们力所能及的小事儿,但我们每一个人都在为抗疫胜利而努力。
但不管最终结果如何、疫情何时结束,这都是一段在我们心中无法忘却的历史,而我们能做的,就是通过记录完整的事件历程,通过大数据分析来得出一些相关结论,避免悲剧的再次发生。这也是大数据给我们带来的价值之一。
我们前几日推送的文章《数据模型分析告诉你,现在还不是出门的时候》中,作者用数据分析告诉来我们,控制人口流动对疫情防治的重要性。
而 GitHub 上的这个项目,凭我个人的理解,可以利用 AI 来分析网站、新闻报道和社交媒体中关于新型冠状肺炎的报道,通过自然语言处理来解析社交媒体上发布的文本,根据新闻发生的先后顺序,来分析真新闻、假新闻,分析事件之间直接或间接的联系,从而得出一些结论和归因。
我相信这些信息对于专业的认识和团队一定有更多、更大的用途。
对于这次疫情控制工作,相关的信息已经变得越来越透明,我们期待看到更多的好消息和正面消息,但对于事件中那些可能做的不好的地方,我们记录下来的初心也是为了让这个国家更好、让人民更幸福。
「2020新冠肺炎记忆:报道、非虚构与个人叙述」GitHub 项目地址: https://github.com/2019ncovmemory/nCovMemory
更多人在行动
除了「nCovMemory」之外,其实还有很多项目值得我们关注和 Star。我司技术大大 @joyqi 就用公开数据记录了疫情的发展趋势,来便于自己和大家从中分析更多有价值的信息:
项目地址:https://github.com/joyqi/ncov2019
许多网友也在做报道、个体叙述、网上舆论的整理和记录,如:
1.2020 Wuhan Individual Stories
- https://github.com/jiayiliujiayi/2020nCov_individual_archives
备份普通人在疫情期间的记录,主要来自豆瓣,未来可能有所扩增。
2.疫情之下的劳动者——中文媒体报道收集(持续更新)
- https://note.youdao.com/ynoteshare1/index.html?id=eee7c8c3d7b8b054dc94d8abd1a211d8&type=note
整理了劳动者们在疫情中的所作所为。按行业编排。
3.疫情与舆情:武汉新冠肺炎时间线TIMELINE
- https://github.com/Pratitya/wuhan2020-timeline
记录自2019年12月起武汉新冠肺炎疫情进展的时间线。以社会学年鉴模式编撰。
4.Academic2019-nCoV
- https://github.com/Academic-nCoV/2019-nCoV
每日发布疫情相关的海外学术、非学术信息。
此次武汉疫情通报所带来的恐惧,远比通报本身的内容蔓延得更快。多个城市陆续通报新型冠状病毒的病例数据,使大家对各种预防方法越来越关注。
但是,很多不正确的预防方法,也在这种时候混淆视听,甚至使人忽视了正确的应对方法。