Python 的垃圾回收机制通过引用计数来决定一个对象要不要被回收。当一个对象被引用次数为0时,它就会被作为垃圾回收从而释放 Python 内存。
但有些情况下,我们的代码可能在不经意间导致某些实际上我们不再使用的对象的引用计数始终大于0,从而无法被垃圾回收。
我们举个例子:
很多人喜欢使用字典来存放一些数据,假设我现在有一个字典是这样的:
- animal = {'Monkey': monkey_obj, 'Tiger': tiger_obj, 'Panda': panda_obj}
其中monkey_obj, tiger_obj, panda_obj都是对象。在我们的程序中,可能会传入不同的字符串来读取不同的对象。当我们把这些对象放进字典中的时候,它的引用计数已经被+1了。
但是,panda_obj这个对象比较特殊,它只会在程序运行的早期被查出来使用1次。之后就再也不会使用了。
但由于这个对象被放在字典里面,所以这个对象的引用计数始终大于0,Python 的垃圾回收机制就会认为这个对象还会被使用,于是它就会始终占用内存。
在数据处理领域或者图像处理领域,经常会出现字典的值占用大量内存的情况,这种情况就会导致内存的浪费。
为了解决这种情况,我们可以使用 Python 自带的weakref模块,它里面有一个WeakValueDictionary,就是用来处理这种情况的。
我们来看看如何使用它:
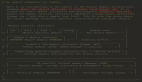
- import weakref
- class Panda:
- def __init__(self, name):
- self.name = name
- def walk(self):
- print('我是一只熊猫,正在走路')
- class Tiger:
- pass
- class Monkey:
- pass
- panda = Panda('xyz')
- tiger = Tiger()
- Monkey = Monkey()
- weak_dict = weakref.WeakValueDictionary()
- weak_dict['Panda'] = panda
- weak_dict['Tiger'] = tiger
- weak_dict['Monkey'] = moneky
使用 weak_dict 就像使用普通的字典一样。但赋值时,值的引用计数不会改变。
这样当我们在其他地方删除panda这个字典时,就不会由于字典占用了一个引用计数而导致无法被垃圾回收问题。