PyTorch 进军三维计算机视觉了,专用库已出炉。

3D 计算机视觉是一个重要的课题,如何选择合适的框架进行计算,使得处理效果更好、更高效?近日,FaceBook 博客更新了一篇新的文章,介绍了团队开发的针对 3D 计算机视觉的框架——PyTorch3D。这是一个基于 PyTorch 的库,在 3D 建模,渲染等多方面处理操作上有更好的表现。
项目地址:https://github.com/facebookresearch/pytorch3d
基于 PyTorch 的 3D 计算机视觉处理库
据项目介绍,PyTorch3d 是一个高效、可复用的 3D 计算机视觉库。在这一项目中,开发者实现了以下新特性:
1. 他们提出了新的 3D 数据结构——Meshes,这种数据结构可以更好地存储和修改三角网格的数据;
2. 高效处理三角网格的算子,如投影变换、图卷积、采样、损失函数等;
3. 一个可微分的网格生成器;
由于是基于 PyTorch 的,这个框架主要面向的是深度学习方面的模型。项目目标是将 3D 计算机视觉和深度学习结合,用于对三维数据的预测和计算。在 PyTorch3D 中,所有的算子都:
1. 使用 PyTorch 的算子;
2. 可以使用异构的批数据;
3. 可微分;
4. 能够使用 GPU 加速;
这样一来,PyTorch3D 吸收了深度学习框架的优势,同时能够专门针对 3D 建模渲染等进行计算,有着很好的性能和应用优势。
主要特性
PyTorch3D 主要有三个值得注意的新特性,这些特性在 FaceBook 的博客中进行了介绍。
3D 网格数据的新格式:Meshes
由于三维网格包含顶点坐标以及面的索引这两者的集合,因此在批量处理不同尺寸的三维网格时会需要进行一些调整。为了解决这个问题,研究者们提出了 Meshes,一种在深度学习应用中可以批量处理异构网络的数据结构。

Mesh 的数据结构。
这种数据结构使得研究人员很容易将底层的网格数据转换为合适的格式,从而让相应的算子能够匹配到最高效的数据表示。Pytorch3D 为用户提供了在不同的表示视图间高效切换的方法,同时还可以获得不同数据表示的属性,具有很好的灵活性。
对 3D 数据的高效处理
团队已经完成了部分工作,如优化一些常用运算符、优化三维数据的损失函数,以及支持异构批数据输入等。
这说明,用户可以在 Pytorch3D 中直接导入这些算子,以便于更快的进行实验。这些算子包括倒角损失(chamfer loss),它是一种用于比较两组点云的方法,可以用作三维网格的损失函数。开发团队还使用 CUDA 内核为这个损失函数创建了一个算力资源密集型的最近邻计算优化方法。
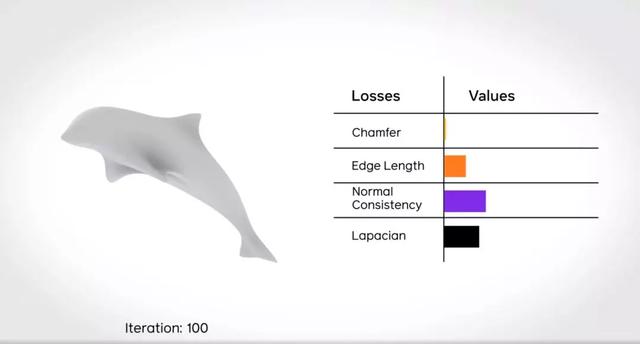
通过对倒角损失等进行收敛,从而建模。
可微的图像渲染方法
将 3D 模型渲染为 2D 图像是这一领域的核心部分。这种渲染采用的思路是将 3D 的场景属性转换为 2D 图像的像素点信息。传统的渲染方法一般是不可微的,因此无法和深度学习结合。可微的渲染方法是一个新的研究领域,而研究者希望通过 PyTorch3D 来实现。
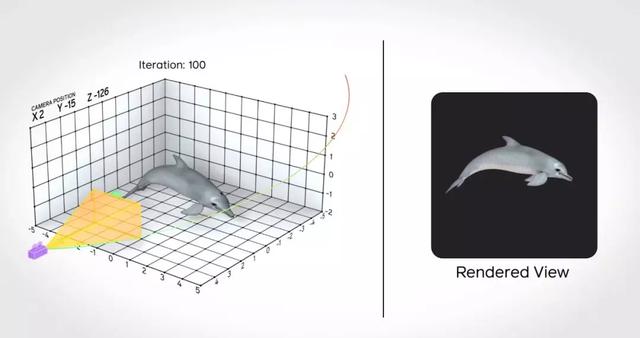
将 3D 模型转换为 2D 图像的过程。
在项目中,研究者采用了高效、模块化且可微的渲染器(renderer)。而且,这些都是可以扩展的,用户可以很容易地进行定制,比如在渲染的时候改变光影效果。而在计算密集的模型转像素点阶段,计算可以在 PyTorch、C++和 CUDA 上并行化,还能够全面地进行测试,验证其准确性。和其他 PyTorch3D 的算子一样,渲染器也是支持异构批量数据的。
使用教程
除了在博客中介绍了项目之外,项目研究者还提供了四个相关教程。

将球形点云分解为海豚: https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/deform_source_mesh_to_target_mesh.ipynb

渲染带有材质的点云:https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/render_textured_meshes.ipynb
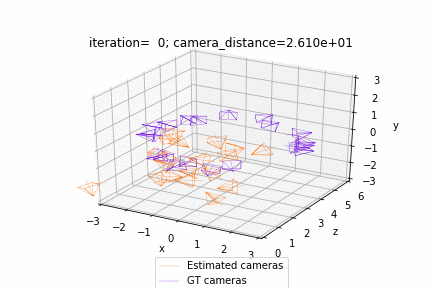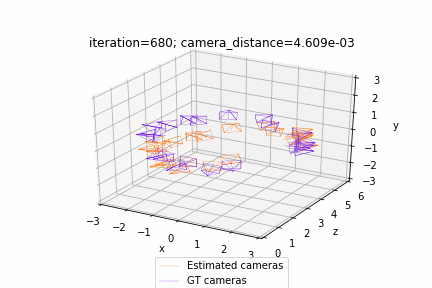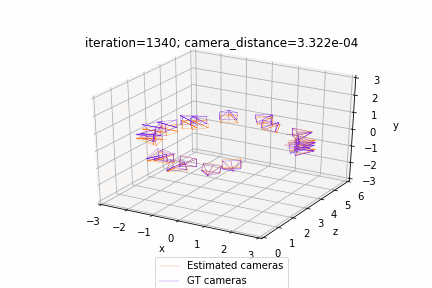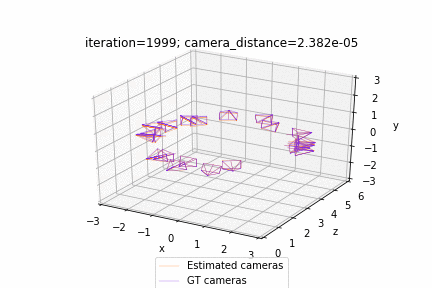
网格调整:https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/bundle_adjustment.ipynb

相机视角优化:https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/camera_position_optimization_with_differentiable_rendering.ipynb