应用场景:工作中经常遇到大量的数据需要整合、去重、按照特定格式导出等情况。如果用 Excel 操作,不仅费时费力,还不准确,有么有更高效的解决方案呢?
本文以17个 txt 文本,3万多条数据为例,使用 Python 连接 MySQL 数据库,实现快速操作。
别人加班干的活,我的 Python 小助手几秒钟就搞定了!
本文主要包括以下三方面内容:
- 数据写入
- 数据去重
- 数据导出
将数据写入 MySQL 数据库
下图所示文件是本文的数据源:
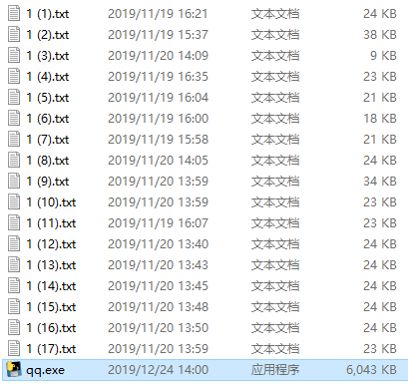
我们的设想是:编写一个小程序,扔在这个文件夹里,双击后就可以自动读取每个 txt 文档中的数据,并写入数据库。
代码如下:
- import pymysql
- import os
- conn = pymysql.connect(host='localhost', user='root', password='123456', db='qq', charset='utf8')
- cur = conn.cursor()
- cur.execute("CREATE TABLE qq ( id int(5) NOT NULL auto_increment, qq varchar(20)NOT NULL, PRIMARY KEY (id));")
- conn.commit()
- path = os.getcwd()
- files = os.listdir(path)
- i = 0
- for file in files:
- f = open(file,'r',encoding = 'UTF-8')
- next(f)
- for line in f:
- i += 1
- #print(line)
- sql = "insert into qq(qq) values(%s);"
- cur.execute(sql,line)
- print("插入第", i, "条数据!")
- conn.commit()
- f.close()
- cur.close()
- conn.close()
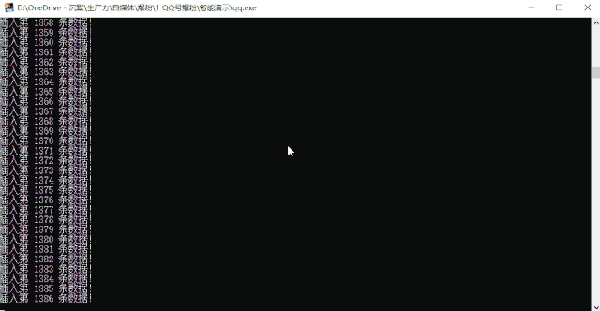
运行效果:
重点代码解释:
这段代码用到了 pymysql 和 os 两个库。
- pymysql:用来操作 MySQL 数据库;
- os:用来遍历所在文件夹下的所有文件。
现将主要代码解释如下:
1、遍历任意文件夹下所有文件名称
程序写好后,使用 pyinstaller 打包成 exe 程序,并放在要操作的文件夹下面。
通过 path = os.getcwd()命令,获取该 exe 文件所在目录。
通过 files = os.listdir(path)命令,获取 exe 文件所在目录下的所有文件名称,并存入 files 列表中。
这样我们就获得了所有的 txt 文件名称,你可以任意命名你的 txt 文件名,程序都能读出来。
2、将数据写入数据库
(1)连接数据库,并在数据库中创建新表
A. 连接到我的 qq 数据库
conn = pymysql.connect(host='localhost', user='root', password='123456', db='qq', charset='utf8')
B. 创建新表 qq
在 qq 数据库中创建新表,表名称为 qq ,包含 2 个字段:id 字段为主键、自动递增;qq 字段为字符型,用于存储数据。
cur.execute("CREATE TABLE qq ( id int(5) NOT NULL auto_increment, qq varchar(20)NOT NULL, PRIMARY KEY (id))")
(2)将数据写入数据库
这里使用了两层循环:
- for file in files:
- f = open(file,'r',encoding = 'UTF-8')
- next(f)
- for line in f:
- i += 1
- #print(line)
- sql = "insert into qq(qq) values(%s);"
- cur.execute(sql,line)
- print("插入第", i, "条数据!")
- conn.commit()
- f.close()
第一层循环是用来依次打开上述 17 个 txt 文件。
第二层循环是依次读取每个 txt 文件的每一行,并将改行数据插入数据库表 qq 的 qq字段。
至此就完成了数据的导入,总共32073条数据。

数据清洗
这里以去除重复值为例,简单介绍一下数据清洗。
1、创建一个新表,用来存储清洗后的数据
可以在 cmd 窗口下登陆 MySQL,打开 qq 数据库,执行下列操作:
CREATE TABLE qq_dist ( id int(5) NOT NULL auto_increment, qq varchar(20)NOT NULL, PRIMARY KEY (id));
这样就创建了新表 qq_dist ,用来存储清洗后的数据,便于后期调用。
2、清洗数据
登陆 MySQL 后,执行下列操作:
insert into qq_dis(qq) select distinct qq from qq;
将从 qq 表中查找出的不重复的 qq 字段内容,插入到 qq_dist 表中的 qq 字段。
将数据按照特定格式导出
案例:将清洗后的数据的第101-200行导出到新的 txt 文本中。
代码如下:
- import pymysql
- conn = pymysql.connect(host='localhost', user='root', password='123456', db='wxid', charset='utf8')
- print("写入中,请等待……")
- cur = conn.cursor()
- sql = "select wxid from wd_dis limit 100,100;"
- cur.execute(sql)
- conn.commit()
- alldata = cur.fetchall()
- f = open('data101-200.txt','a')
- i = 0
- for data in alldata:
- i += 1
- f.write(data[0])
- f.flush()
- f.close
- cur.close()
- conn.close()
- print("写入完成,共写入{}条数据!".format(i))
重点代码解释:
1、 limit
MySQL 中 limit m,n 函数的含义是:从第 m+1 行开始读取 n 行。
所以,本案例中读取第101-200行,就是 limit 100,100
2、flush()
flush()函数一定要加上,它可以将缓冲区的数据写入文件中。否则就会出现生成的 txt 文档为空白的错误。