【51CTO.com快译】众所周知,虽然同属于人工智能的范畴,但是深度学习是一种特殊的机器学习形式。从流程上说,机器学习和深度学习都是从运用测试数据来训练某个模型开始,通过一系列的优化过程,进而找到最适合模型的数据权重。显然,这两种方法都可以处理数值(回归)和非数值(分类)的问题,只是在对象识别和语言翻译等应用领域,深度学习模型往往比机器学习模型更加适用。
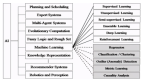
细说机器学习
机器学习算法通常分为:监督(用各种答案来标注训练数据)和非监督(任何可能存在的标签都不会被显示在训练算法中)两种。
监督式机器学习又可以进一步被分为:分类(预测诸如:抵押贷款支付逾期的概率等非数字性的答案)和回归(预测诸如:某种网红商品的销售量等数字性的答案)。
无监督学习则可以进一步分为:聚类(查找相似对象组,如:跑步鞋、步行鞋和礼服鞋)、关联(查找对象的共同逻辑,如:咖啡和奶油)、以及降维(进行投射、特征选择与提取)。
分类算法
分类问题属于监督式学习范畴。它需要在两个或多个类之间进行选择,并最终为每一个类分配概率。最常见的算法包括:朴素贝叶斯、决策树、逻辑回归、k近邻和支持向量机(SVM)。您还可以使用诸如:随机森林等其他集成方法(模型的组合),以及AdaBoost和XGBoost之类的增强方法。
回归算法
回归问题也属于监督式学习范畴。它要求模型能够预测出一个数字。其中最简单且最快的算法是线性(最小二乘)回归。不过它通常只能给出一个不够准确的结果。其他常见的机器学习回归算法(除了神经网络)还包括:朴素贝叶斯、决策树、k近邻、LVQ(学习矢量量化)、LARS(最小角回归)、Lasso、弹性网络、随机森林、AdaBoost和XGBoost等。显然,在回归和分类的机器学习算法之间有一定的重叠度。
聚类算法
聚类问题属于无监督式学习范畴。它要求模型找出相似的数据点组。其中最流行的算法是K-Means聚类。其他常见的算法还包括:均值漂移聚类、DBSCAN(基于密度的带噪声应用空间聚类)、GMM(高斯混合模型)和HAC(凝聚层级聚类)。
降维算法
降维问题也属于无监督式学习范畴。它要求模型删除或合并那些对结果影响很小或没有影响的变量。它通常与分类或回归结合起来使用。常见降维算法包括:删除缺失值较多的变量、删除低方差的变量、决策树、随机森林、删除或合并高相关性的变量、后向特征消除、前向特征选择、因子分析、PCA(主成分分析)等。
各种优化方法
我们需要通过训练和评估,优化参数的权重,来找到一组最接近真实情况的数值,进而将监督式学习算法最终转化为恰当的模型。在实际应用中,这些算法的优化常常依赖于那些陡降的变体,例如:随机梯度下降,它本质上是在随机起点上执行多次陡降(steepest descent)。
而对于随机梯度下降法的常见改进包括:根据动量修正梯度的方向因素,或调整从一个数据(或称为epoch或batch)到下一个数据学习率的进展。
数据清理
为了让杂乱无章的数据能够为机器学习所用,我们必须对数据进行全面的过滤,其中包括:
1.初次查看数据,排除那些有大量丢失数据的列。
2.再次查看数据,选择需要进行预测的列(即,特征选择)。这也是您在迭代时可能希望更改的内容。
3.在其余列中排除那些缺少数据的行。
4.纠正明显的拼写错误,合并相应的答案。例如:U.S.、US、USA和America都应该被合并为一个类别。
5.排除具有超出范围数据的行。例如:如果您正在分析纽约市内出租车的出行情况,那么您需要过滤掉那些开到该城市区域边界之外的地理坐标行。
当然,您也可以酌情增加其他步骤,这主要取决于您收集到的数据类型。您甚至可以在机器学习管道(请参见-https://www.infoworld.com/article/3198252/data-in-intelligence-out-machine-learning-pipelines-demystified.html)中设置一些数据清理的步骤,以便按需进行修改与复用。
数据编码和标准化
为了对数据进行分类,您需要将文本标签编码为另一种形式。常见的有如下两种:
一种是label编码,它将每一个文本标签值都替换为一个数字。另一种是one-hot编码,它将每一个文本标签值都替换为带有二进制值(1或0)的列。一般来说,由于label编码有时会使机器学习算法误认为:被编码的列已经是一个有序列了,因此我们首选采用one-hot编码。
为了让数值数据适用于机器回归,我们通常需要对数据进行规范化。否则,更大范围的数字可能会主导特征向量之间的欧氏距离(Euclidian distance,它是在m维空间中两个点之间的真实距离),而该影响可能会以其他字段为代价被放大,进而导致陡降的优化难以收敛。目前,针对机器学习的数据规范化与标准化有着多种方法,其中包括:最小值标准化、均值标准化、以及按单位长度扩展等。有时该过程也被称为特性扩展(https://en.wikipedia.org/wiki/Feature_scaling)。
特征工程
特征是指被观察到的现象的可测量特性。“特征”的概念通常与解释变量相关。此处的解释变量,经常被用于诸如线性回归之类的统计技术。而特征向量则会将单行的所有特征,组合成一个数值型的向量。
选择特征的巧妙之处在于是否能选出解释问题的最小独立变量集。如果两个变量高度相关,则要么将它们合并成为一个单独的特征,要么去掉其中的一个。有时候,我们在进行主成分分析时,可以把相关的变量转换成一组线性无关的变量。
在实际应用中,我们能够通过简单的方式,来构造新的特征或减少特征向量的维数。例如,用死亡年份减去出生年份,就得到了死亡年龄,这是针对寿命和死亡率分析的主要自变量。当然,在其他情况下,特性的构建并非如此浅显。
分割数据
监督式机器学习的通常做法是:将数据集分成各个子集进行训练、验证和测试。其中的一种工作方式是:将80%的数据分配给训练数据集,而将其他的10%分配给验证和测试数据集。目前,大部分训练都是针对数据集进行的。在每一个epoch结束时,我们将针对验证数据集进行预测。
那些验证数据集中的错误,不但可以被用于识别停止的条件,并驱动超级参数的调优,而且可以帮助您确定目标模型是否对训练数据进行了过度的拟合。
对于测试数据集的预测通常是在最终模型上完成的。如果某个测试数据集从未被用于训练,我们有时则称之为holdout数据集。
作为其他常见的分割数据方案,交叉验证能够重复地将整个数据集分割成一套训练数据集,以及一套验证数据集。
机器学习库
在Python中,Spark MLlib(https://www.infoworld.com/article/3141605/review-spark-lights-up-machine-learning.html)和Scikit-learn(https://www.infoworld.com/article/3158509/review-scikit-learn-shines-for-simpler-machine-learning.html)都是机器学习库的最佳选择。在R语言中,常见的机器学习包有CARAT、randomForest、e1071和KernLab。而在Java中,您可以用到Java-ML、RapidMiner和Weka。
细说深度学习
作为机器学习的一种应用形式,深度学习在被训练模型的输入和输出之间存在着不止一个隐藏层。在大多数讨论场合中,深度学习意味着使用深度技术的神经网络。当然,除了神经网络,深度学习还会使用一些算法来实现其他类型的隐藏层。
“人工”神经网络的概念由来已久,它是由相互连接的阈值开关,构成了人工神经元网络,可以像动物大脑和神经系统(如:视网膜)那样学习识别模式。
Backprop
当两个神经元在训练中同时活跃(active)时,学习基本上是通过加强两个神经元之间的连接来实现的。在当前的神经网络软件中,最常见的方法是:使用一种称为误差反向传播(或称backprop、BP)的规则,来增加神经元之间连接的权值。
人工神经网络中的神经元
每一个神经元都拥有一个传播函数。该函数可通过加权来转换连接神经元的输出。传播函数将输出传递给激活函数,激活函数在输入超过阈值时就会被触发。
神经网络中的激活函数
在上个世纪40、50年代,人工神经元普遍使用的是被称为感知器(perceptrons)的一步式激活函数。如今的神经网络引入了诸如:逻辑函数、s形函数(sigmoid function)、双曲正切函数、修正线性单元(ReLU)等平滑激活函数。其中,ReLU虽然存在着“在学习率设置过高时,神经元会在训练中‘死亡’”的问题,但是它仍然是快速收敛的最佳选择。
激活函数的输出可以传递给某个输出函数,进行附加整形。不过,输出函数通常是恒等函数,因此激活函数的输出会直接被传递给连接在下游的神经元中。
神经网络拓扑结构
常见的神经网络拓扑结构是:
1. 在前馈网络中,神经元可分为:一个输入层、n个隐藏处理层和一个输出层。每一层的输出都只会输入到下一层。
2. 在具有快捷连接的前馈网络中,一些连接可以跳过一到多个中间层。
3. 在递归神经网络中,神经元可以直接或间接地通过下一层来影响自己。
训练神经网络
神经网络的监督学习和其他机器学习类似:我们用一组训练数据来表示网络,将网络输出与期望的输出进行比较,以生成错误向量,接着根据错误向量再对网络进行修正。在应用纠正之前,那些共同运行的批量训练数据被称为epoch。
在实现细节上,相对于模型的权值和偏差方面的梯度,反向传播使用误差(或成本)函数,来发现正确的方向,从而最小化误差。因此,应用的正确性取决于优化算法和学习速率的变量。正如前面提到的,该变量通常需要足够的小,以保证收敛性,并避免造成ReLU神经元“死亡”。
神经网络的优化器
通常,神经网络的优化器会使用某种形式的梯度下降算法,来驱动反向传播。同时,它会用到一种避免陷入局部极小值的机制,例如:只优化那些随机选择的小批量(随机梯度下降),以及对梯度使用动量修正的方式。另外,一些优化算法(如:AdaGrad、RMSProp和Adam)还会通过查看梯度的历史,来调整模型参数的学习率。
与所有的机器学习类似,您需要根据一个单独的验证数据集,来检查神经网络的预测。如果不这样做的话,您所创建的神经网络可能只能记住输入的信息,而无法学习并成为广义的预测器。
深入学习的各种算法
一个针对真实问题的深度神经网络,可能由十多个隐藏层所组成,其拓扑结构也可能繁简不同。一般而言,网络中的层级越多,其优势是能够识别的特征就越多,而劣势则为计算所需的时间就越长,训练也就越困难。
卷积神经网络(CNN)常被用于机器视觉等应用之中。该网络通常使用卷积、池化、ReLU、全连接、以及丢失层来模拟视觉的皮层。其中,卷积层主要是对于许多小的重叠区域进行积分。池化层执行的是一种非线性的下采样(down-sampling)形式。ReLU层用到了非饱和激活函数f(x) = max(0,x)。在一个完全连接的层级中,神经元与前一层的所有激活都有联系。丢失层主要负责计算网络训练如何“惩罚”那些预测标签和真实标签之间的偏差,使用Softmax或交叉熵(cross-entropy)损失函数来进行分类,或使用欧式(Euclidean)损失函数进行回归。
递归神经网络常被用于自然语言处理(NLP)、序列处理、长短时记忆(LSTM)网络、基于注意力的神经网络。在前馈神经网络中,信息通过隐藏层从输入流向输出。这有效地限制了该网络一次性只能处理一个状态。
在递归神经网络(RNN)中,信息通过反复循环,让网络只记住最近的一次输出,以便对序列和时序进行分析。当然,RNN存在着两个常见的问题:爆炸性的渐变(我们很容易通过夹持来修复)和消失的渐变(不太容易修复)。
在LSTMs中,该网络能够用forgetting和gating来修改以前信息的权重,并记住它们。通过此类长、短期记忆,该网络解决了梯度消失的问题。同时,LSTMs也可以处理数百个过去输入的序列。
注意力模块是一些将权重应用到输入向量上的通用门。它的分层神经注意编码器(hierarchical neural attention encoder)使用多层注意模块,来处理成千上万的过去的输入。
虽然不属于神经网络,但是随机决策森林(RDF)对于一系列分类和回归问题也十分有用。由多个层级构成的RDF,能够输出单个树的预测统计平均值(一般为分类模式或回归平均值)。在随机方面,RDF对单个树使用引导聚合(也称为bagging),并针对树的特性进行随机取子集。
同样不属于深度神经网络的XGBoost (eXtreme Gradient boost),是一个可扩展的端到端树状增强系统。它在许多机器学习的挑战中都取得了先进的成果。不同于RDF,它的梯度树增强是从单个决策树或回归树开始的。通过优化,其后续的树是基于前续树的残留而构建的。
目前,业界公认最好的Python深度学习框架包括:TensorFlow、Keras、PyTorch和MXNet。Deeplearning4j是最好的Java深度学习框架之一。而ONNX和TensorRT则是用于深度学习模型的运行时(runtime)。
深度学习与机器学习的比较
一般而言,经典(非深度)机器学习算法的训练和预测速度,要比深度学习算法快得多。一到多个CPU足以训练一个经典的模型。而深度学习模型通常需要硬件加速器,如GPU、TPU或FPGA来进行训练,以及大规模的部署。如果没有它们,此类模型可能需要几个月的训练时间。
自然语言处理是深度学习的一个分支,它包括语言翻译、自动化摘要、协同参考解析、语篇分析(discourse analysis)、形态分割(morphological segmentation)、命名实体识别、自然语言生成、自然语言理解、词性标注、情感分析和语音识别等。
深度学习的另一个主要应用领域是图像分类。它包括:带定位的图像分类、目标检测、目标分割、图像风格转换、图像着色、图像重建、图像超分辨率和图像合成等。
此外,深度学习已经被成功地用于预测分子之间的相互作用,以帮助制药公司设计新药,搜索亚原子粒子,并将自动解析用于构建人脑三维显微镜图像等方面。
原文标题:Deep learning vs. machine learning: Understand the differences,作者:Martin Heller
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】