













近期肆虐的新型冠状病毒,已然成为大众视野的焦点。笔者,最近趁过年之际也看了一些相关新闻和书籍,其中,有一本名为卡尔·齐默《病毒星球》让我印象深刻。当然,本文并不是谈及新型冠状病毒和《病毒星球》,而是将故障和病毒进行类比,聊一聊计算机软件的故障应对机制,而其中关于病毒相关科普性的资料和数据来自于《病毒星球》一书。
一、故障:潜伏于计算机软件的病毒
人鼻病毒作为普通感冒和哮喘的罪魁祸首,是人类广泛存在的老朋友。鼻病毒巧妙地利用鼻涕来自我扩散。人擤鼻涕的时候,病毒会借机跑到手上,通过手再蹭到门把手和其他手碰过的地方。下次其他人碰到这些地方,病毒就会借机沾上他们的手,再进入他们的身体——大多数时候也是借道鼻子。鼻病毒能巧妙地让细胞对它们打开一扇“小门”,继而入侵位于鼻腔内部、咽喉内部或肺脏内部的细胞。在接下来的几个小时里,鼻病毒利用宿主细胞,复制自己的遗传物质和包裹它们的蛋白外壳。随后这些复制产生的病毒会从宿主细胞内破壁而出。此外,我们每个人的基因组中携带了近 10 万个内源性逆转录病毒的 DNA 片段,占到人类 DNA 总量的 8%。虽然这类病毒 DNA 中的大多数都没用,但我们的祖先也的确“征用”了一些对我们自身有好处的病毒。如果没有这些病毒,我们甚至没法出生。在演化史上最近的瞬间,人类脱颖而出,病毒对我们的生存功不可没。原本就并没有什么“它们”和“我们”之分——生物在本质上只是一堆不断混合、不断闪转腾挪的 DNA 而已。因此,鼻病毒在几千年前就开始让古埃及人患上感冒,内源性逆转录病毒早在数千万年前就入侵了我们灵长类祖先的基因组。(摘自《病毒星球》)
故障也与之类似,它就好似生命体的 DNA 片段缠绕于计算机软件中,无法割舍。如今软件开发迭代频繁,我们很难全部排除故障,只能说尽可能多地发现和解决问题,避免故障发生在生产环境导致线上问题。当我们遭到病毒感染,细胞释放一种名为“细胞因子”的信号分子,把附近的免疫细胞都召唤过来。它们让我们的身体产生炎性反应,等免疫系统帮我们把体内的病毒全部干掉。而在计算机软件,我们也会有类似的场景,我们的开发人员或测试人员一旦确认是程序 BUG,就会立即记录并周知相关人员进行处理与修复,并持续跟踪,直至故障解决。
二、听过很多案例,依然无法解决故障
感冒这么难治,一个原因是它存在形态多种多样,由于其基于突变及快速复制带来来遗传多样性。而面对故障,虽然它的底层导火索可能就只有哪几种,但是由于技术的复杂性和业务的复杂性导致了计算机软件的整体复杂性。
我们知道 NPE (NullPointerExcepion)会给我们带来巨大灾难,但是我们在实际的研发中经常遗忘或忽视。这里,由于没有对受检对象进行非空判断导致 NPE 故障。
- public static void npe03(){
- Person person = null;
- System.out.println(person.blog);
- }
下面的示例将会导致 NPE,你发现了吗?
- public static void npe01(){
- Integer x = 1;
- Integer y = 2;
- Integer z = null;
- Integer val = false ? x * y : z;
- }
而这个示例,也是非常典型的由 Java 自动装箱和拆箱导致的 NPE 故障。
- public static void invoke(){
- Long x = null;
- npe02(x);
- }
- public static void npe02(long x){
- System.out.println(x);
- }
再聊一个有意思的故障问题。大家都知道由于死循环会导致 CPU 100%。但是,导致 CPU 100% 导因是多样性的,笔者团队曾经遇到一个 JDK 8 的 BUG,它是由于 ConcurrentHashMap 递归创建对象扩展导致死循环,文章链接:《ConcurrentHashMap.computeIfAbsent 死循环》。
三、故障应急机制:监控、告警、预案
通常情况下,线上故障一旦发生,其后果一般都比较严重。所以,我们需要尽快解决,降低其带来的影响和资损。例如,我们团队之前口号是:“1-5-10”,即一分钟发现,五分钟处理,十分钟解决。那么,如何做到快速的发现线上故障呢?搭建成熟的监控系统就非常重要啦,例如通过 Zabbix 或 Prometheus 监控各种基础设施(MySQL、Redis、MongoDB、ElasticSearch 等)运行情况,以及业务系统的运行情况,以及 CPU、内存、磁盘 I/O、网络 I/O 等波动情况,还有 GC 情况、binlog 同步情况等等。那么,发现问题后,就需要通过告警系统根据业务规则进行多渠道(邮件、钉钉、电话)联系故障处理人。要快速解决,怎么办?首先,需要一套完备的日志排查系统(日志聚合 + 链路追踪),此外,还需要对于 JVM 相关能快速 dump 堆栈信息,对于自助分析有 DevOps 平台支撑。但是,最主要的还是需要有一套预案体系。什么是预案系统?就是针对不同的问题,有一套完整的预先方案来快速响应。例如,某个服务不可用了,笔者排查发现是由于进程假死了,那么就可以通过预案里面的执行方案执行 shell 脚本进行快速拉活。再比如,笔者通过监控告警感知到某个商家资金异常波动,那么此时通过预案里面的执行方案将其通过动态开关将其快速熔断。
但是,如果这次线上故障没有应急预案,又比较棘手,怎么办?别无他法,只能因着头皮来处理啦。注意的是,故障的评级一般根据业务的影响范围面而定,事实上,最本质的资金损失,包括直接的资损,例如前段时间某知名电商的免额优惠劵导致非常严重的资损;间接的资损,例如挖断电缆导致整个 app 无法使用,那么,转化成正常的交易额也是大把大把的资损呀。然后呢,过了 2 个小时,故障还没修复,可能原先定级 P2 的故障就会升级到 P1。
如果发生最差的情况,就是可能短时间内无法解决,那么就很可能需要停服维修了。例如,近期肆虐的新型冠状病毒导致全国性的封城封路,事实上,也是因为我们没有特效药(计算机软件领域的预案),也还没有研制出新药(计算机软件领域的解决方案),所以只能封城封路(计算机软件领域的停服)。
四、提早发现故障 - 故障演练
通常情况下,偶尔感冒会提供我们的免疫力。而在计算机领域,偶然采取故障演练也可以尽可能确保在线上运行的系统没有缺陷和故障。这里,Netflix 为应对不确定性的领域带来了一种全新的思维模式:混沌工程。事实上,混沌工程提倡我们正面接受系统一定会存在缺陷和故障,然后我们通过一系列实验找出可能发生问题的风险点,进而不断地加固系统。
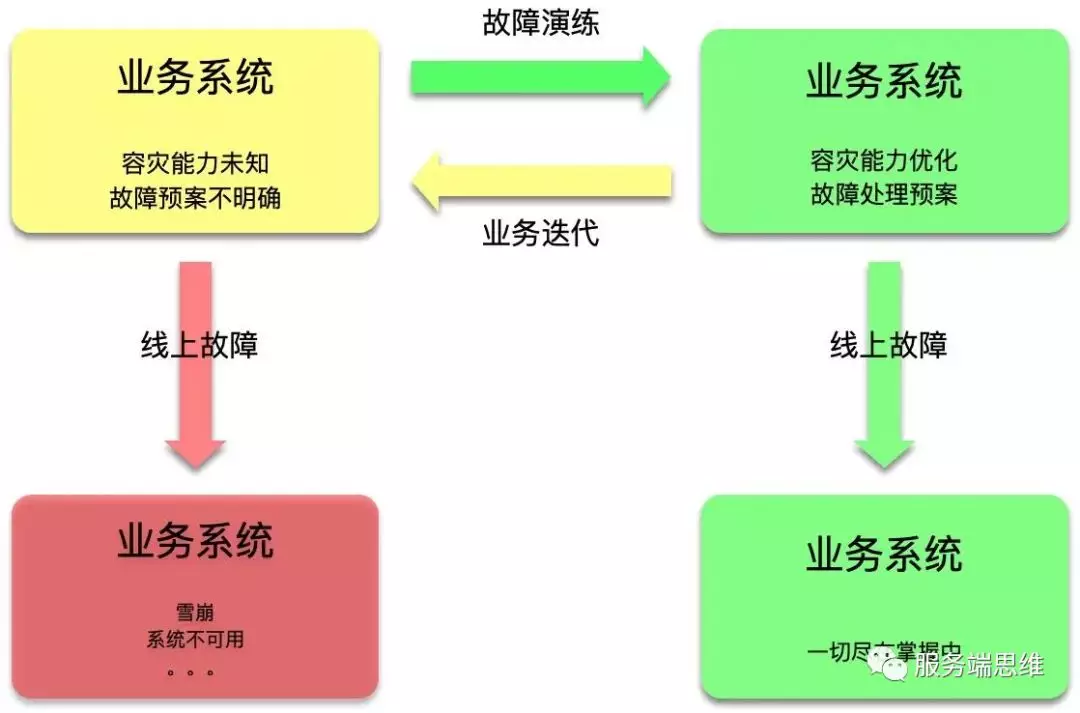
故障演练可以模拟 CPU 满载、杀掉指定进程、域名访问不通、网络延迟、网络丢包、填充磁盘、磁盘 IO 高等场景,如下所示。
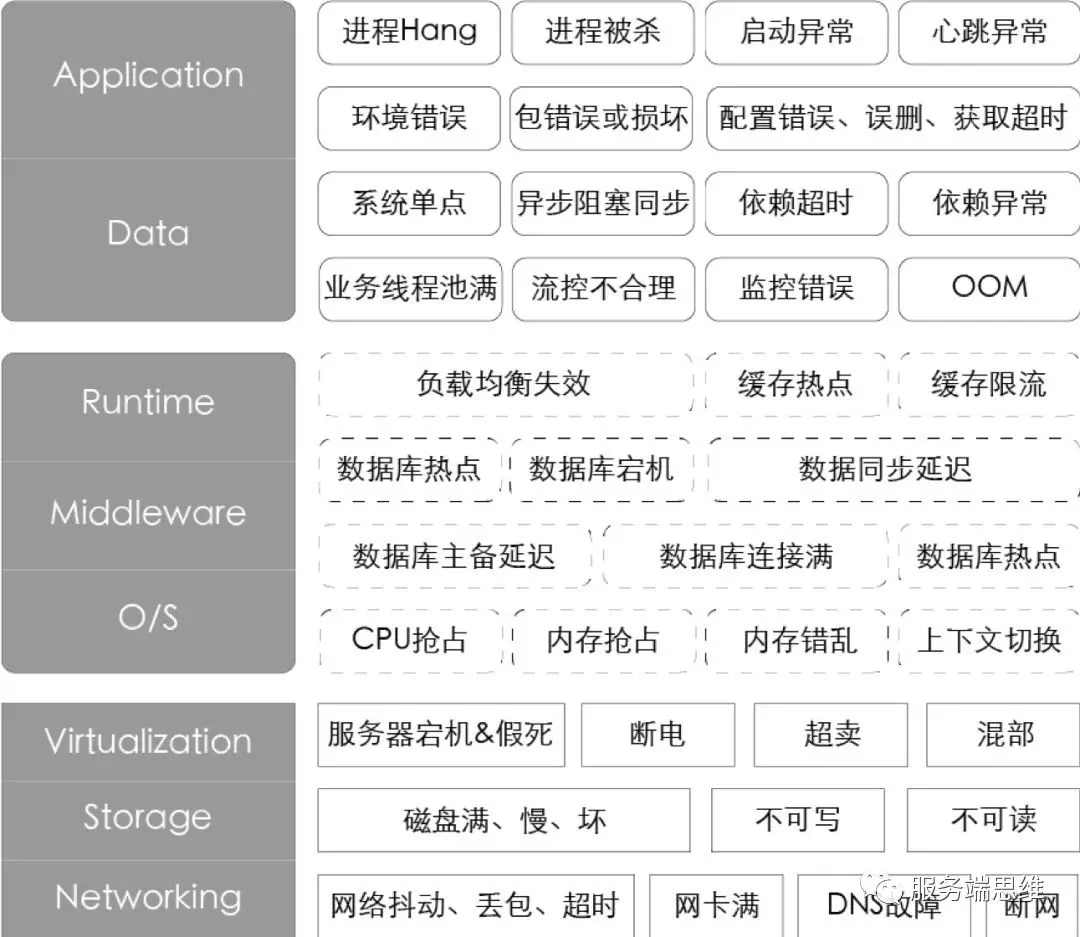
总结一下,故障就像潜伏于计算机软件的病毒,由于技术的复杂性和业务的复杂性导致了其排查和解决的困难性,我们可以采取监控、告警、预案,以及故障演练提早发现故障并解决故障。











