2019 年是机器学习和自然语言处理领域飞速发展的一年。DeepMind 科学家 Sebastian Ruder 从 10 个方面总结了我们在过去的一年中取得的重要进展,对未来的研究方向有着重要的指导意义。
本文介绍了 2019 年中 机器学习和自然语言处理领域 10 个影响巨大的有趣研究方向。
对于每个方向,本文都会先总结今年我们在该方向取得的主要进展,简要说明我认为这个方向重要的原因,最后对未来的工作进行简短的展望。
这 10 个方向分别是:
- 通用无监督预训练(Universal unsupervised pretraining)
- 彩票(Lottery tickets)假设
- 神经正切核(The Neural Tangent Kernel)
- 无监督多语言学习(Unsupervised multilingual learning)
- 更多鲁棒的对比基准(More robust benchmarks)
- 机器学习与自然语言处理对科学发展的贡献(ML and NLP for science)
- 解决自然语言生成问题中的解码误差(Fixing decoding errors in NLG)
- 增强预训练的模型(Augmenting pretrained models)
- 高效且记忆范围广的 Transformer(Efficient and long-range Transformers)
- 更加可靠的分析方式(More reliable analysis methods)
通用非监督预训练
由于 BERT(Devlin et al., 2019)及其变体横空出世,无监督预训练在今年的自然语言处理(NLP)领域大放异彩。众多 BERT 的变体已经在多模态场景下被应用,这些场景主要涉及文本及其相关的图像、视频(如下图所示)。无监督训练也开始渗透到过去监督学习统治的领域。在生物信息学领域中,Transformer 语言模型的预训练也开始被应用在蛋白质序列预测上了(Rives et al., 2019)。
在计算机视觉领域,包括 CPC(Hénaff et al., 2019), MoCo(He et al., 2019)和 PIRL(Misra & van der Maaten, 2019)在内的模型,以及为了提升在 ImageNet 数据上的采样效率与图像生成效果而提出的强大的生成器模型 BigBiGAN(Donahue & Simonyan, 2019)都利用了自监督学习方法。在语音领域,多层卷积神经网络(Schneider et al., 2019)和双向 CPC(Kawakami et al., 2019)学习到的表征都比最先进的模型表现要好,而且所需的训练数据也更少。
它为什么重要?
无监督预训练使得我们在训练模型时对已标注数据的需求量大大减少。这使得那些以前数据需求得不到满足的领域开始有了焕发活力的可能性。
接下来会怎么发展?
尽管研究人员已经着手研究无监督预训练,而且已经在一些独立领域上已经取得了巨大的成功。但如果未来它能够朝着多模态紧密融合的方向发展,应该还是很有趣的。
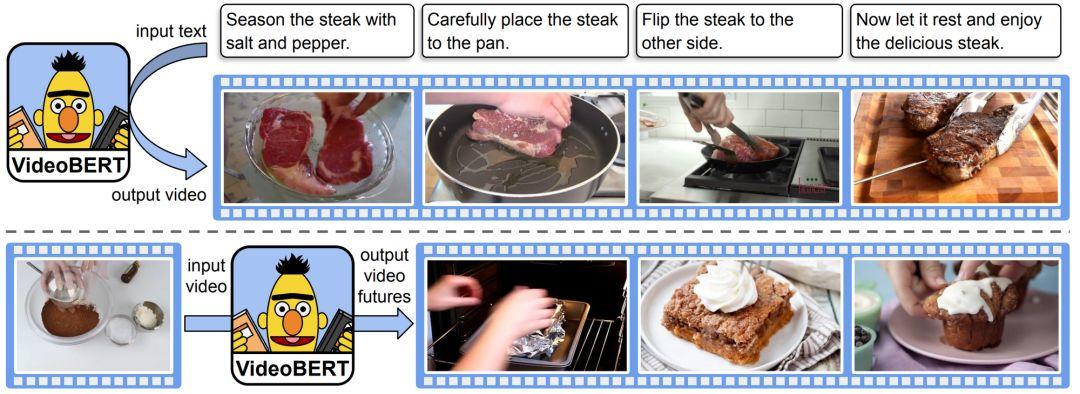
最近提出的 BERT 的多模态变体 VideoBERT(Sun et al., 2019)。它可以基于食谱生成视频的「token」(图片上半部分),还可以在给定某个视频「token」时,预测后面不同的时间尺度下的「token」(图片下半部分)。
彩票假设
如下图所示,Frankle and Carbin(2019)定义了「中奖彩票」(winning tickets)——也就是在密集的、随机初始化的前馈网络中找到的初始化良好的子网络,独立训练这个子网络应该得到与训练完整网络相近的准确率。
虽然最初的剪枝过程只适用于小的视觉任务,但后来的工作 (Frankle et al., 2019) 将剪枝应用于早期的训练,而不是初始化阶段,这使得找到更深的模型的小子网络成为可能。Yu et al.(2019) 在 NLP 与 RL 的 LSTM 和 Transoformer 模型中也发现了「中奖彩票」。尽管这种中奖的彩票还是很难找到的,但它们似乎可以在数据集和优化器之间转移 (Morcos et al., 2019)。
为什么重要?
在神经网络变得越来越先进的同时,它们的规模也与日俱增,训练它们并将其用于预测的算力需求也越来越大。能够稳定地找出达到类似性能的较小的子网络可以大大减少训练与推理的算力需求。这可以加速模型迭代,并且为终端设备计算和边缘计算开启了新可能。
接下来会怎么发展?
目前来说,在低资源的场景下,为了产生实际的效益,想要找出「中奖彩票」仍然需要巨大的计算开销。更加鲁棒的 one-shot 剪枝方法对剪枝过程中噪音的敏感度小一些,因此可以在一定程度上缓解这个问题。研究「中奖彩票」的特性也能够帮助我们更好地理解初始化,了解神经网络训练的过程。
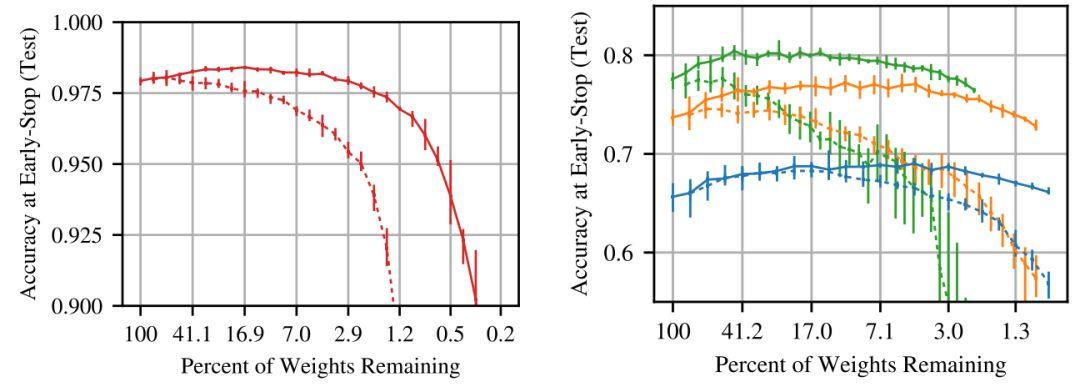
不同剪枝率下的测试准确率——实线代表中奖彩票,虚线代表随机采样得到的子网络(Frankle & Carbin, 2019)。
神经正切核
估计一般人都很难想到,当神经网络很宽(更确切地说是无限宽)时,其实是比它窄的时候更好研究的。研究结果表明,在无限宽极限下,神经网络可以近似为一个带核的线性模型,该核即为神经正切核(Neural Tangent Kernel,NTK,Jacot et al., 2018)。实际上,这些模型的性能不及深度有限的模型(Novak et al., 2019; Allen-Zhu et al., 2019 ; Bietti & Mairal, 2019 ),这也限制了研究结果在标准方法上的应用。
然而,近期的一些工作(Li et al., 2019; Arora et al., 2019)已经大大降低了神经正切核与标准方法的性能差距(参见 Chip Huyen 关于 NeurIPS 2019 其他相关论文的博文)。
为什么重要?
NTK 可能是我们所掌握的用于分析神经网络理论行为最强大的工具。虽然它也有其局限性(即实用的神经网络仍然比相应的 NTK 版本的模型性能更好),而且这个领域迄今为止的研究成果都还没有转化成实际效益,但它可能帮助我们打开深度学习的黑盒。
下一步该做什么?
目前看来,NTK 与标准方法的差距主要来源于宽度的不同,未来的工作可能会试着去描述这种差距。这也将帮我们将无限宽度限制的想法放在实践中。最终,NTK 可能帮助我们理解神经网络的训练过程和泛化行为。
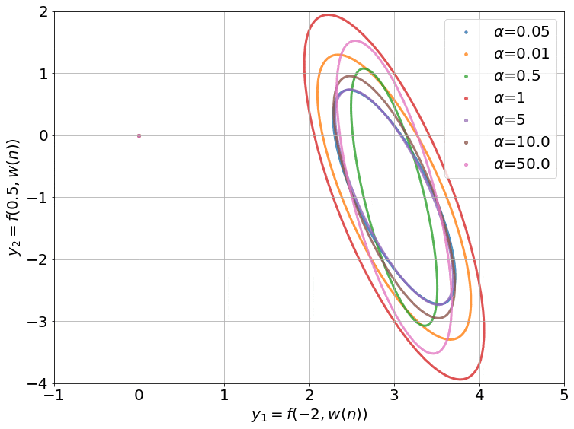
带有 NTK 的线性模型在输出放缩因子 α 取不同值时的学习过程,图中的椭圆为 NTK 的可视化结果。
无监督多语言学习
多年来,跨语言表征主要关注单次级别的研究,详见总综述文章「A Survey of Cross-lingual Word Embedding Models」。得益于无监督预训练的发展,2019 年间涌现出了诸如 multilingual BERT,XLM(Conneau & Lample, 2019)和 XLM- R(Conneau et al., 2019)。尽管这些模型没有显式地使用任何跨语言信号,但即使在没有共享单词表或进行联合训练的情况下(Artetxe et al., 2019; Karthikeyan et al., 2019 ; Wu et al., 2019),它们在不同语言之间的泛化效果也是出奇地好。
「Unsupervised Cross-lingual Representation Learning」对多语言模型进行了概述。这种深度模型也给无监督机器翻译领域带来了很多提升(Song et al., 2019; Conneau & Lample, 2019)。该领域在 2018 年也取得了重要的进展,由于统计方法与神经网络方法更合理的融合而得到了提升。另一个值得高兴的发展是我们可以根据现有的英文预训练表征构建深度多语言模型(见下图)。
为什么重要?
现有的跨语言表征技术使得除了英语外的其它语言模型可以使用更少的语料进行训练。而且,如果英文中有充足的标注数据,那这些方法就能让 zero-shot 迁移成为可能。最终,它们也有可能帮助我们理解不同语言间的关系。
接下来该怎么发展?
目前这些方法在没有任何跨语言监督信号的情况下能取得如此好的性能的原因尚不明确。进一步了解这些方法的工作机理可能会帮助我们设计出更强大的算法,也有可能揭示出不同语言结构之间的关系。此外,我们不应该只把注意力放在 zero-shot 迁移上,我们还应该考虑从那些几乎没有标注数据的目标语言中学习。
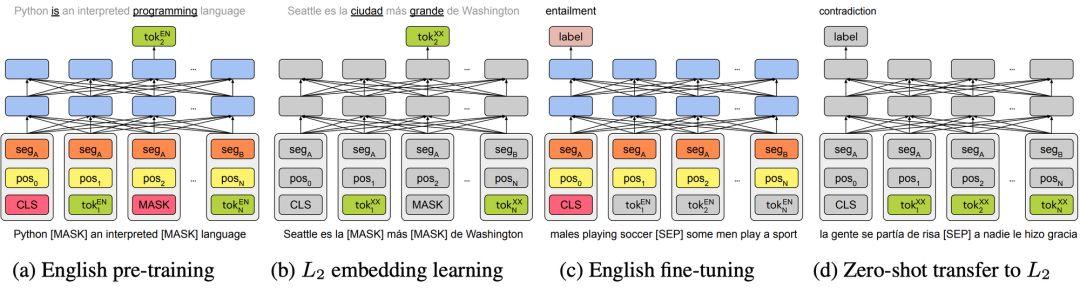
Artetxe et al. (2019) 提出的单语言迁移方法的四个步骤。
更鲁棒的对比基准
SOTA 中有东西腐朽了——Nie et al. (2019) 对莎士比亚的名言「Something is rotten in the state of Denmark」的改述。
近期,像 HellaSWAG(Zellers et al., 2019)这种新的 NLP 数据集都是为了考验当前性能最优的模型而创建的。数据集中的示例都是经过人工筛选的,以明确保证留下的数据都是那些目前性能最优的模型无法成功处理的(相关示例见下图)。这种人为参与的对抗性数据构建工作可以重复多次,例如最近的对比基准 Adversarial NLI(Nie et al., 2019)就使得数据集的创建对于目前的自然语言推断模型来说更具挑战性。
为什么重要?
许多研究者发现,当前的 NLP 模型并没有学到他们应该学到的东西,只是用一些很简单的启发式方法去发现一些数据中很浅层的线索,详见「NLP's Clever Hans Moment has Arrived」。随着数据集变得越来越鲁棒,我们希望新提出的模型可以被逼着学习到数据中真正深层次的关系。
接下来该怎么发展?
随着模型越来越强大,大多数数据集需要不断改进,否则很快就会过时。我们需要专用的基础系统和工具来促进这一进程。此外,应该运行合适的对比基线,包括使用不同数据变体的简单方法和模型(例如使用不完整的输入),以便数据集的初始版本尽可能鲁棒。

上图为 HellaSWAG 中的一个句子填空多选题,当前性能最优的模型很难回答这个问题。最难的例子在于复杂度需要「刚刚好」,回答中会包含三个背景中的句子和两个生成的句子(Zellers et al., 2019)。
科学中的机器学习与自然语言处理
将机器学习用于基础科学问题取得了一些重要的进展。本文作者主要关注的领域是深度神经网络在蛋白折叠预测以及多电子薛定谔方程(Pfau et al., 2019)上的应用。从 NLP 的角度来说,值得高兴的是,即使是标准模型在融合领域指示后也能得到巨大的进步。在材料科学领域,研究人员完成了一个使用词嵌入来分析潜在知识的工作(Tshitoyan et al., 2019),从而预测某种材料会不会拥有某种特性(见下图)。在生物领域,基因、蛋白质等数据都是序列型的,因此 NLP 方法(LSTM,Transformer 等)天生就适合解决这类问题,这些方法已经被应用于蛋白质分类任务中了(Strodthoff et al., 2019; Rives et al., 2019)。
为什么重要?
科学可以说是机器学习影响最大的应用领域之一。解决方案可能对许多其它的领域产生很大的影响,并且可以帮助解决实际问题。
下一步怎么做?
从在物理问题中对能量建模(Greydanus et al., 2019 )到求解微分方程(Lample & Charton, 2020),机器学习技术不断地被应用在新的科学问题中。2020 年,让我们看看这其中最具影响力的工作是什么,这将非常有趣!
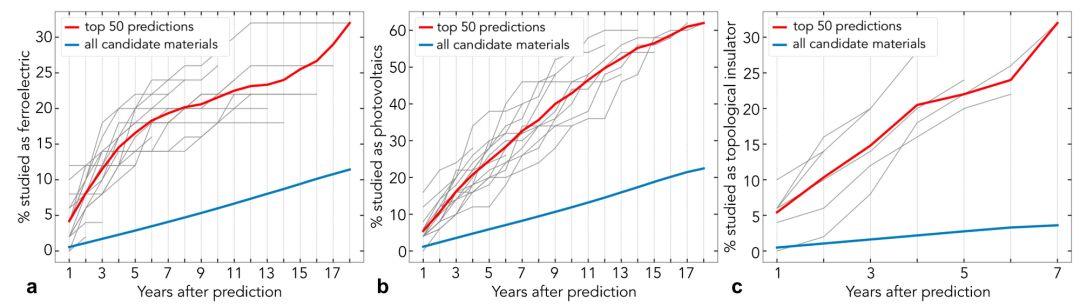
基于不同时间段文献的摘要进行训练获得词嵌入,从而预测这些材料在未来会被作为什么(铁电体、太阳能光伏、拓扑绝缘体)。
图片展示了预测中最可能被研究的 50 个材料与所有候选材料的对比 (Tshitoyan et al., 2019 )。
解决自然语言生成(NLG)中的解码误差
尽管自然语言生成(natural language generation, NLG)领域的模型越来越强大,但是它们仍然经常生成重复或者毫无意义的话(如下图所示)。这主要是最大似然训练造成的。值得庆幸的是,这一点正在被改进,并且其进展是与建模工作是正交的。这类改进大部分都是以新的采样方式(如原子核采样,Holtzman et al., 2019)或新的损失函数(Welleck et al., 2019)的形式出现。
另外一个令人惊讶的发现是,好的搜索结果并没有帮助模型获得更好的生成结果:当前的模型在一定程度上依赖于不精确的搜索与集束搜索的误差。相反,在机器翻译的场景下,精确搜索通常会返回无意义的翻译结果(Stahlberg & Byrne, 2019)。这个发现表明,搜索和建模方面的进步必须携手并进。
为什么重要?
NLG 是 NLP 中的最基本任务之一。在 NLP 和机器学习的研究中,大多数论文都重点关注对模型的改进,而其它部分的发展往往被忽略。对于 NLG 研究者来说,重要的是要提醒我们自己,我们的模型仍然有缺陷,也许可以通过修正搜索或训练过程来改进输出。
下一步怎么做?
尽管 NLG 模型越来越强大,而且有了迁移学习的助力,但是模型的预测结果依然包含了很大程度的认为因素。找出并理解这些人为因素产生的原因是一个很重要的研究方向。

GPT-2 使用集束搜索以及单纯的(贪婪)采样方法产生的结果,蓝色部分是重复的,红色部分则是毫无意义的话。
增强预训练的模型
2019 年,值得高兴的是,我们使预训练模型的方法拥有了新的能力。有些方法使用知识库来加强预训练模型,用以提升模型在实体识别(Liu et al., 2019 )任务上的表现和对事实的回忆(Logan et al., 2019)。还有一些方法通过访问一些预定义的可执行程序完成简单的算法推理(Andor et al., 2019)。由于大多数模型都有较弱的归纳偏置,且大部分知识是从数据中学习而来,因此增强预训练模型的另一个选择就是增强训练数据本身(比如获取常识,Bosselut et al., 2019),如下图所示。
为什么重要?
模型正变得越来越强大,但有许多知识是模型无法仅从文本中学习的。特别是在处理更复杂的任务时,可用的数据可能太有限,无法使用事实或常识进行显式的推理,因此可能需要更强的归纳偏置。
下一步怎么做?
随着这些模型被应用于更有挑战性的问题,越来越有必要对模型进行组合性的修改。在未来,我们可能会结合强大的预训练模型和可学习的组合程序(Pierrot et al., 2019)。
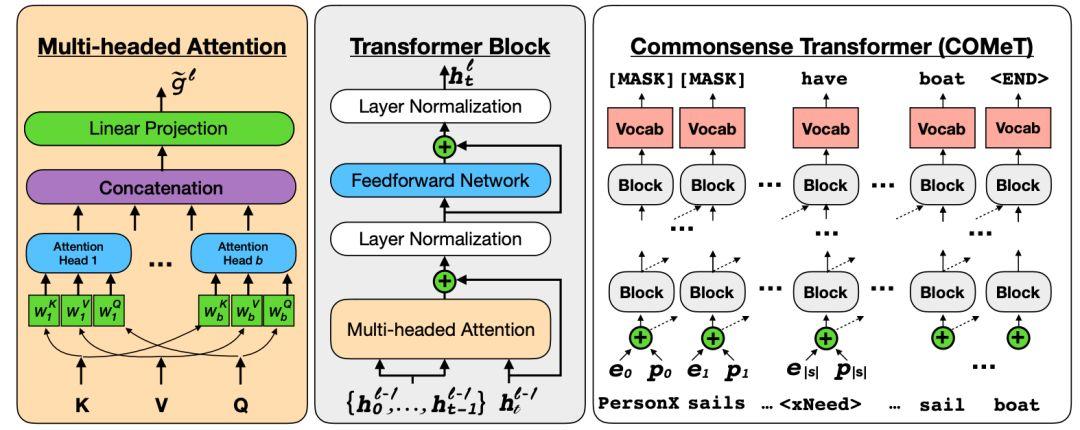
一个标准的带有多头注意力机制的 Transformer。在给定头实体和关系的情况下,训练后的模型可以预测知识库三元组中的尾实体(Bosselut et al., 2019)。
高效且记忆范围广的 Transformer
今年 Transformer 架构得到了一些改进(Vaswani et al., 2017 )。这些新的架构(如 Transformer-XL,Dai et al., 2019 与 the Compressive Transformer,Rae et al., 2020 )使其可以获取长距离依赖。
还有一些方法希望通过使用不同的(通常也很稀疏的)注意力机制(如 adaptively sparse attention, Correia et al., 2019; adaptive attention spans, Sukhbaatar et al., 2019 ; product-key attention, Lample et al., 2019; locality-sensitive hashing, Kitaev et al., 2020 等)来使 Transformer 更高效。
在基于 Transformer 的预训练领域中,也出现了很多更高效的变体,比如使用了参数共享的 ALBERT(Lan et al., 2020)以及使用更高效预训练任务的 ELECTRA(Clark et al., 2020)等。当然,也有一些没有使用 Transformer 而且同样更高效的预训练模型,比如一元文档模型 VAMPIRE (Gururangan et al., 2019) 和 QRNN-based MultiFiT (Eisenschlos et al., 2019)。另一个值得注意的趋势是:对大型 BERT 进行蒸馏,以获得更小的模型(Tang et al., 2019 ; Tsai et al., 2019 ; Sanh et al., 2019)。
为什么重要?
Transformer 架构从诞生之初就很有影响力。它是一种最先进的 NLP 模型,并已被成功地应用于许多其它的领域(参见第 1 和第 6 节)。因此,对 Transformer 架构的任何改进都可能产生强烈的连锁反应。
下一步怎么做?
这些改进需要一段时间才能落实到实践中,但是考虑到预训练模型的普及和易用性,这种更有效的替代方案可能很快就会被采用。总的来说,我们希望研究者可以持续关注强调效率的模型架构,而稀疏性就是其中的主要趋势之一。
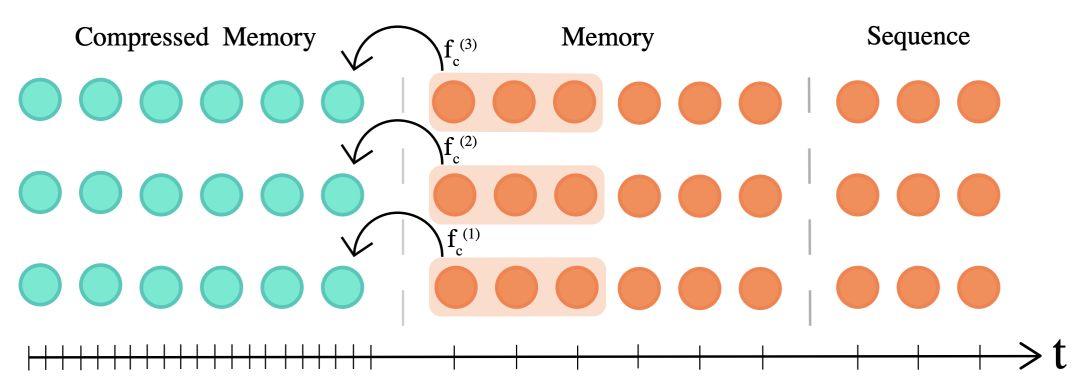
Compressive Transformer(Rae et al., 2020)可以将过去的激活函数的细粒度记忆压缩成粒度较粗的压缩记忆。
更可靠的分析方法
2019 年的一个关键趋势是分析模型的论文越来越多。事实上,本文作者最喜欢的几篇论文就是这样的分析论文。比较早的一个亮点工作是 Belinkov & Glass 于 2019 年对分析方法的综述。同时,在我的记忆中,今年也是第一次开始出现有工作致力于分析 BERT 这一种模型(这类论文被称为 BERTology)的论文。在这种情况下,探针(probe)已经成为一种常用的工具,它的目的是通过预测某些属性来了解模型是否「理解」了词法、句法等。
本文作者特别喜欢那些探究如何让探针技术更可靠的论文(Liu et al., 2019 ; Hewitt & Liang, 2019)。可靠性也是一直在被讨论的一个主题,即注意力是否能提供有意义的解释(Jain & Wallace, 2019; Wiegreffe & Pinter, 2019; Wallace, 2019)。研究人员对分析方法的兴趣方兴未艾,最好例证可能是 ACL 2020 的新赛道——NLP 模型的分析与可解释性。
为什么重要?
目前最先进的方法一般都被当做黑盒来使用。为了开发更好的模型并在现实世界中使用它们,我们需要理解为什么模型会做出这些决策。然而,我们目前解释模型预测结果的方法仍然有限。
下一步怎么做?
我们需要做更多的工作来解释那些超出我们预期的预测,它们通常是不可靠的。在这个方向上,的一个重要趋势是更多数据集提供了人工书写的解释(Camburu et al., 2018 ; Rajani et al., 2019; Nie et al., 2019)。
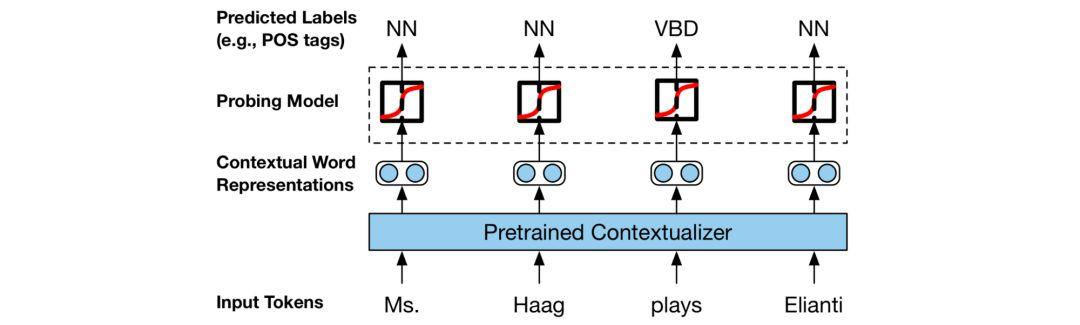
用来学习表征中的语言知识的 probing 设置。
以上便是作者对 2019 年 NLP 领域的盘点了。可以看出,NLP 依然是一个蓬勃发展的领域,很多理论都在快速发展,未来研究成果可期。