本来以为过年了要好好写文章,因为疫情的关系,新增的不少的需求。希望这场疫情早日过去吧,武汉加油。今天我们来聊一聊数据库迁移,这个其实非常的常见,例如我们要从自己的机房将数据迁移到腾讯云或者阿里云这些线上服务,或者我们有时候需要把一个业务拆分成多个子业务,为了减少系统的耦合,我们通常也会选择拆库,这就需要进行数据迁移。很多公司,在进行数据迁移的时候,都会选择停服来处理,这是一种偷懒的方法,数据迁移能不能做到不停服呢?今天我们来介绍下这个高速换轮胎的技术,数据库迁移。
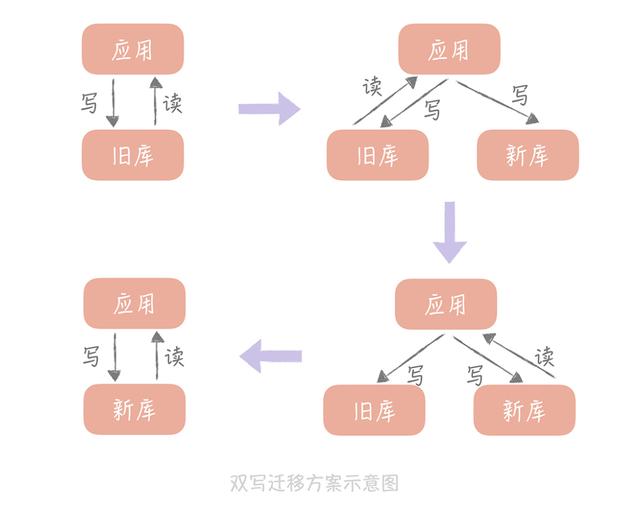
这个是最常见的数据迁移的一个流程。一开始,我们的应用都是读写旧的数据库,这个时候我们还没有开启数据迁移。紧接着,我们会有一个新的数据库,一般来说,这个时候,我们会开启双写,什么是双写呢?就是对数据库的写操作,我们既写到旧库,又写到新库。如果担心因为双写而造成的耗时增加,我们可以选择异步同步的模式,但是异步势必增加了系统的复杂性,我们需要把失败的日志记录下来,以便后期进行处理。
在第二步的时候,我们仍然是读取旧数据库的数据,这个时候对线上的业务几乎是没有影响的,接下来,我们可以准备读取新库的数据,为了减小影响,我们可以采用一定的灰度策略,先让部分流量读取新库,然后再慢慢扩大灰度范围,这个时候所有的写请求还是双写的,一旦发现有问题,可以回退到第二步甚至是第一步,减少对业务的影响。当服务稳定下来之后,我们可以去掉对旧库的写入,这样子就能完成一次数据迁移。
相信很多人会问,说的容易。那么对于历史数据,怎么迁移到新库呢?这里我们介绍两种常见的方法,一是懒惰迁移,二是主动迁移。什么是懒惰迁移呢?这个是从英文单词Lazy翻译过来的,就是如果这行数据没有被使用到,我们就不管他,如果它被使用到,那么我们就把它迁移过来。一般我们会使用一个key-value来记录下哪些key被懒惰迁移过,当我们更新旧表的时候,如果发现这个key没有被迁移,那么就顺路把他写到新表里面,并且更新下键值数据,表示这个key已经被迁移过了,后面双写的时候,直接双写即可,无需进行数据迁移。
另外一个是主动迁移,有些数据,可能在进行数据迁移的时候就没被访问过,例如用户可能几个月不登录,你不能因为数据迁移就把他抛弃了。所以我们需要对这些冷数据进行数据迁移,简单来说,就是扫取数据库中的存量数据,然后将他们写入新的数据库即可。
总结
这里要注意的是,我们在数据迁移的时候,如果用户频繁地修改数据,是有可能造成数据不一致的,所以,一般我们都会选择在晚上,用户活跃度低的时候进行数据迁移。甚至在业务方便会去限制用户的并发请求数,从而减少因为并发而出现数据不一致的情况。上述方案,对于大多数公司与业务,其实已经够用了,当然,如果你的业务场景更加复杂,数据量更加大,还要进一步分析,进一步制定迁移方案。欢迎大家关注我,共同学习,共同进步。大家的支持是我继续唠嗑的动力。同名公众号(沙茶敏碎碎念)