












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
2019年,整个AI行业的发展如何?
- NLP模型不断刷新成绩,谷歌和Facebook你方唱罢我登场;
- GAN在不断进化,甚至能生成高分辨率难辨真假的人脸;
- 强化学习攻破了《星际2》等战略游戏。
让人对到来的2020年充满期待。

最近,Analytics Vidhya发布了2019年AI技术回顾报告,总结了过去一年中,AI在不同技术领域取得的进展,并展望了2020年的新趋势。
Analytics Vidhya是一个著名数据科学社区。其技术回顾报告由多位机器学习业内专家撰写。
报告认为,在过去的一年中,发展最为迅猛的是NLP,CV已较为成熟,RL才刚刚起步,明年可能迎来大爆发。
量子位在报告基础上,进行了编译整理及补充。话不多说,一起来逐一盘点2019的那些AI技术吧:
自然语言处理(NLP):语言模型井喷,部署工具涌现
NLP在2019年实现了巨大的飞跃,该领域这一年取得的突破是无与伦比的。
报告认为,2018年是NLP的分水岭,2019年本质上是在此基础上进一步发展,让该领域突飞猛进。
Transformer统治了NLP
自从2017年的论文Attention is All You Need发表以来,出现了BERT为代表的NLP模型。之后,Transformer一次又一次地在NLP领域中统治了SOTA结果。
谷歌的Transformer-XL是另一种基于Transformer的模型,在语言建模方面胜过BERT。随后是OpenAI的GPT-2模型,它以其生成非常像人类的语言文字而闻名。
2019年下半年,BERT本身出现了许多创新,例如CMU的XLNet,Facebook AI的RoBERTa和mBERT(多语言BERT)。这些模型在RACE、SQuAD等测试榜上不断刷新成绩。
GPT-2则终于释出完整版,开源15亿参数模型。

GPT-2模型地址:https://openai.com/blog/gpt-2-1-5b-release/
延伸阅读
BERT重夺多项测试第一名,改进之后性能追上XLNet,现已开源预训练模型
模仿川普语气真假难分,康奈尔盲测15亿参数模型:从未如此逼真,最强编故事AI完全体来了
大型预训练语言模型成常态
迁移学习是2019年NLP领域出现的另一趋势。我们开始看到多语言模型,这些模型在大型的未标记文本语料库上进行了预训练,从而使它们能够学习语言本身的潜在细微差别。
GPT-2、Transformer-XL等模型几乎可以对所有NLP任务进行微调,并且可以在相对较少的数据下很好地运行。
像百度的ERNIE 2.0这样的模型引入了持续预训练的概念,预训练方法有了很大的进步。在此框架中,可以随时逐步引入不同的自定义任务。
新的测试标准推出
随着一系列NLP新模型带来了巨大性能提升,它们的测试分数也已经达到了上限,分差很小,甚至在GLUE测试中超过了人类的平均水平。
因此这些测试基准已经不足以反映NLP模型的发展水平,也不利于未来的进一步提高。
DeepMind、纽约大学、华盛顿大学联合Facebook提出了新的测试标准SuperGLUE,加入了更难的因果推理任务,对NLP模型提出了新的挑战。

开始考虑NLP的工程和部署
2019年出现了一大批实用的NLP资源:
斯坦福大学开源的StanfordNLP库,HuggingFace的Transformer预训练模型库。spaCy利用该库创建了spacy-transformers,这是一种用于文本处理的工业级库。
斯坦福NLP小组表示:“与我们在2019年训练的大型语言模型一样,我们还将重点放在优化这些模型上。”
像BERT,Transformer-XL,GPT-2这些大型模型的问题在于,它们的计算量很大,因此在现实中使用它们几乎是不切实际的。
HuggingFace的DistilBERT显示,可以将BERT模型的大小减少40%,同时保留其97%的语言理解能力,并且速度提高60%。
谷歌和丰田研究出了另一种减小BERT模型尺寸的方法ALBERT,它在3个NLP基准测试(GLUE,SQuAD,RACE)上获得了SOTA的成绩。
延伸阅读
GitHub万星NLP资源大升级:实现Pytorch和TF深度互操作,集成32个最新预训练模型
对语音识别的兴趣增加
NLP领域在2019年重新燃起了对英伟达NeMo等框架开发音频数据的兴趣,该框架使端到端自动语音识别系统的模型训练变得异常轻松。
除了NeMo之外,英伟达还开源了QuartzNet,QuartzNet 另一个基于Jasper的新的端到端语音识别模型架构,Jasper是一种小型,高效的语音识别模型。
更关注多语言模型
在能够使用多语言数据之前,NLP如何真正发挥作用?
今年,人们对重新探索NLP库(例如StanfordNLP)的多语言途径有了新的兴趣,这些途径带有经过预先训练的模型,可以处理50多种人类语言的文本。您可以想象,这对社区产生了巨大影响。
然后,成功尝试通过Facebook AI的XLM mBERT(超过100种语言)和CamemBERT 等项目来创建像BERT这样的大型语言模型,该项目针对法语进行了微调:
2020年趋势
以上是2019年NLP领域进展的总结,2020年该领域会有哪些趋势呢?
身为NLP专家、Kaggle Grandmaster的Sudalai Rajkumar推测了2020年的主要趋势:
延续当前趋势,在更大的数据集上训练更大的深度学习模型;
构建更多的生产应用程序,较小的NLP模型将对此有所帮助;
手动注释文本数据的成本很高,因此半监督标记方法可能会变得很重要;
NLP模型的可解释性,了解模型在进行公正决策时学到的知识。
NLP领域学者、ULMFiT的作者之一Sebastian Ruder认为:
不仅会从庞大的数据集中学习,还会看到更多的模型在更少样本上高效地学习;
模型越来越强调稀疏性和效率;
重点关注多语言的更多数据集。
计算机视觉(CV):图像分割愈发精细,AI造假愈演愈真
计算机视觉方面,今年CVPR、ICCV等国际顶会接收论文数量均有大幅增长。下面,就来回顾2019最受瞩目的几种重要算法和实现。
何恺明Mask R-CNN正在被超越
Mask Scoring R-CNN
在COCO图像实例分割任务上,Mask Scoring R-CNN超越了何恺明的Mask R-CNN,并因此中选计算机视觉顶会CVPR 2019的口头报告。
在Mask R-CNN这样的模型中,实例分类的置信度被当作mask的质量衡量指标,但实际上mask的质量和分类的质量并没有很强的相关性。
华中科技大学的这篇文章针对这个问题进行了研究,他们提出了一种新的打分方法:mask score。

不仅仅直接依靠检测得到分类得分,Mask Scoring R-CNN模型还单独学习了一个针对mask的得分规则:MaskloU head。
同时考虑分类得分和蒙版得分,Mask Scoring R-CNN就能更加公正地评估算法质量,提高实例分割模型的性能。
研究团队在COCO数据集上进行了实验,结果表明Mask Scoring R-CNN在不同的基干网路上,AP提升始终在1.5%左右。
这篇论文被Open Data Science评为2019年第一季度十佳论文之一。
论文一作是地平线实习生黄钊金,来自华中科技大学电信学院副教授王兴刚的团队,王兴刚也是这篇论文的作者之一。
SOLO
字节跳动实习生王鑫龙提出的实例分割新方法SOLO,作为一种单阶段实例分割方法,框架更简单,但性能同样超过了Mask R-CNN。
SOLO方法的核心思想是,将实例分割问题重新定义为类别感知预测问题和实例感知掩码生成问题。
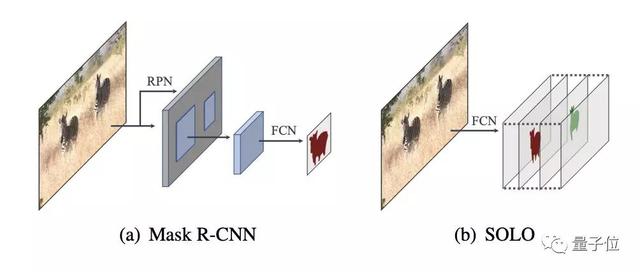
COCO数据集上的实验结果表明,SOLO的效果普遍超过此前的单阶段实例分割主流方法,在一些指标上还超过了增强版Mask R-CNN。
相关地址
https://arxiv.org/abs/1903.00241v1https://arxiv.org/abs/1912.04488
延伸阅读
性能超越何恺明Mask R-CNN!华科硕士生开源图像分割新方法 | CVPR19 Oral
字节跳动实习生提出实例分割新方法:性能超过何恺明Mask R-CNN
EfficientNet
EfficientNet是一种模型缩放方法,由谷歌基于AutoML开发,在ImageNet测试中实现了84.1%的准确率,刷新记录。
虽然准确率只比在其之前的SOTA模型Gpipe提高了0.1%,但模型更小更快,参数量和FLOPs都大幅减少,效率提升10倍之多。
其作者是来自谷歌大脑的工程师Mingxing Tan和首席科学家Quoc V. Le。
相关地址
GitHub:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
论文:https://arxiv.org/abs/1905.11946
延伸阅读
谷歌开源缩放模型EfficientNets:ImageNet准确率创纪录,效率提高10倍
Detectron2
这项超强PyTorch目标检测库来自Facebook。
比起初代Detectron,它训练比从前更快,功能比从前更全,支持的模型也比从前更丰盛。一度登上GitHub热榜第一。

实际上,Detectron2是对初代Detectron的完全重写:初代是在Caffe2里实现的,而为了更快地迭代模型设计和实验,Detectron2是在PyTorch里从零开始写成的。
并且,Detectron2实现了模块化,用户可以把自己定制的模块实现,加到一个目标检测系统的任何部分里去。
这意味着许多的新研究,都能用几百行代码写成,并且可以把新实现的部分,跟核心Detectron2库完全分开。
Detectron2在一代所有可用模型的基础上(Faster R-CNN,Mask R-CNN,RetinaNet,DensePose),还加入了了Cascade R-NN,Panoptic FPN,以及TensorMask等新模型。
相关地址
GitHub:https://github.com/facebookresearch/detectron2
延伸阅读
GitHub趋势榜第一:超强PyTorch目标检测库Detectron2,训练更快,支持更多任务
更强的GAN们
2019年,GAN们依然活跃。
比如同样来自Google DeepMind的VQ-VAE二代,生成的图像比BigGAN更加高清逼真,而且更具多样性:https://arxiv.org/abs/1906.00446
BigBiGAN,不仅能生成质量优秀的图像,还在图像分类任务上刷新了记录:https://arxiv.org/abs/1907.02544
以色列理工学院和谷歌联合出品,拿下ICCV2019最佳论文的SinGAN:https://arxiv.org/abs/1905.01164
英伟达的StyleGAN也高能进化成为StyleGAN2,弥补了第一代的各种缺陷:https://arxiv.org/abs/1912.04958
延伸阅读
史上最佳GAN被超越!生成人脸动物高清大图真假难辨,DeepMind发布二代VQ-VAE
刷新ImageNet纪录,GAN不只会造假!DeepMind用它做图像分类,秒杀职业分类AI
ICCV2019最佳论文SinGAN全面解读,看这一篇就懂了
如果没有StyleGAN2,真以为初代就是巅峰了:英伟达人脸生成器高能进化,弥补重大缺陷
2020年趋势
展望2020年,Analytics Vidhya认为,视觉领域的重点,依然会聚焦在GAN上:
styleGAN2等新方法正在生成越来越逼真的面部图像,检测DeepFake将变得越来越重要。视觉和(音频)都将朝向这个方向进行更多研究。
而元学习和半监督学习,则是2020年的另一大重点研究方向。
强化学习(RL):星际DOTA双双告破,可用性更强
2019年,现有的强化方法扩展到了更大的计算资源方面,并取得了一定的进展。
在过去的一年里,强化学习解决了一系列过去难以解决的复杂环境问题,比如在Dota2和星际2等游戏中战胜了人类顶尖职业玩家。
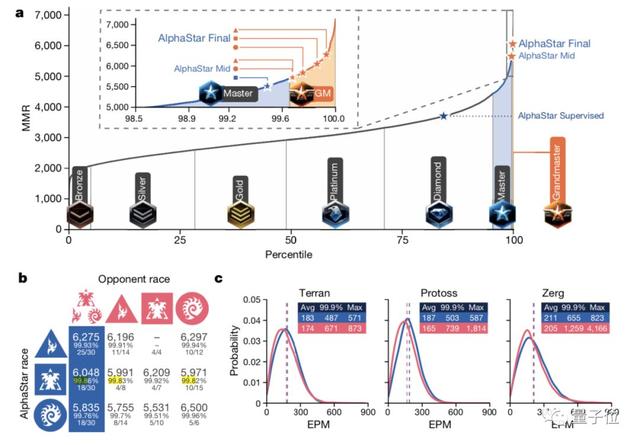
报告指出,尽管这些进展引起了媒体行业极大的关注,但是当前的方法还是存在着一些问题:
需要大量的训练数据,只有在有足够准确和快速的模拟环境的情况下,才能获得训练数据。许多电子游戏就是这种情况,但大多数现实世界中的问题却不是这样。
由于采用了这种训练模式,因此,大规模的强化学习算法,感觉就像只是在问题空间的过度密集采过度产生的策略 ,而不是让它学习环境中的潜在因果关系并智能地进行概括。
同样,几乎所有现有的Deep RL方法在对抗性样本、领域外泛化和单样本学习方面都非常脆弱,目前还没有好的解决方案。
因此,Deep RL的主要挑战是逐渐从应对确定性的环境,转向专注于更基本的进步,例如泛化、转移学习和从有限数据中学习等等。从一些机构的研究趋势中,我们可以看出这一点。
首先OpenAI发布了一套类似于健身房的新环境,该环境使用过程级别生成来测试Deep RL算法的泛化能力。
许多研究人员开始质疑并重新评估我们对“智能”的实际定义。我们开始更好地了解神经网络的未被发现的弱点,并利用这些知识来建立更好的模型。
延伸阅读
1-10落败,5分钟崩盘!星际2职业高手史上首次被AI击溃,AlphaStar一战成名
碾压99.8%人类对手,三种族都达宗师级!星际AI登上Nature,技术首次完整披露
2:0!Dota2世界冠军OG被OpenAI碾压,全程人类只推掉两座外塔
Dota2冠军OG如何被AI碾压?OpenAI累积三年的完整论文终于放出
2020年趋势
总而言之,2020年的预测趋势如下:
从有限的数据中学习和推广将成为强化学习研究的中心主题;
强化学习领域的突破与深度学习领域的进步紧密相关;
将有越来越多的研究利用生成模型的力量来增强各种训练过程。
交叉型研究:AI深入多学科研究
随着人工智能技术的发展,跨学科研究也成为了今年的热门。AI的身影,频现于医学、脑机接口乃至数学研究当中。
脑机接口
在马斯克、Facebook纷纷押注的脑机接口领域,深度学习正在帮助研究人员解码大脑所想。
比如加州大学旧金山分校这项登上Nature的研究:利用深度学习直接读懂大脑,将大脑信号转换成语音。
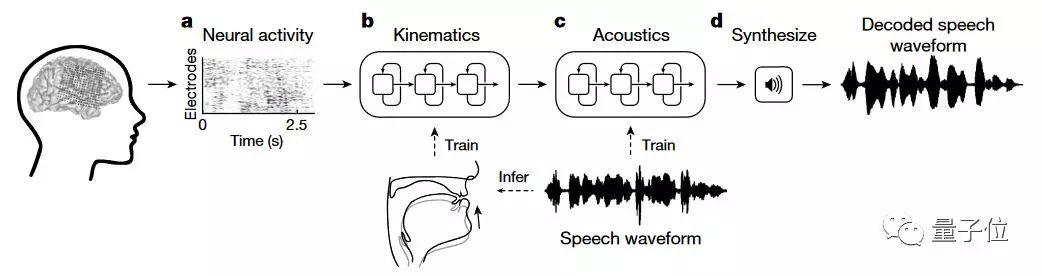
此前的语音合成脑机接口每分钟只能生成8个单词,而这项研究中的新装置,每分钟能生成150个单词,接近人类自然语速。
医学
在医学领域,机器学习技术也不仅仅在医疗影像识别上发挥作用。
比如,德国组织工程和再生医学研究所的一项研究,就利用深度学习算法DeepMACT,自动检测和分析了整个小鼠身体中的癌症转移灶。

基于这项技术,科学家首次观察到了单个癌细胞形成的微小转移位点,并且把工作效率提高了300倍以上。
“目前,肿瘤临床试验的成功率约为5% 。我们相信DeepMACT技术可以大大改善临床前研究的药物开发过程。因此,这可能有助于为临床试验找到更强大的候选药物,并有望帮助挽救许多生命。”研究的通讯作者Ali Ertürk表示。
数学
虽说数学是自然科学的基础,但在AI不断的发展下,也起到了一定“反哺”作用。
Facebook发表的一项新模型,可以在1秒时间内,精确求解微分方程、不定积分。
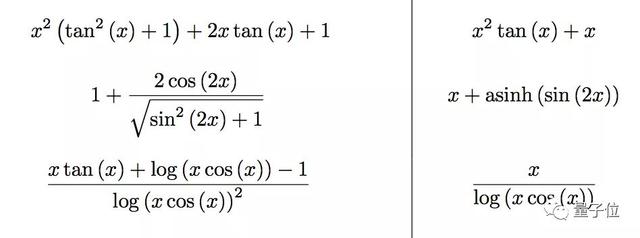
不仅如此,性能还超越了常用的Mathematica和Matlab。
积分方程和微分方程,都可以视作将一个表达式转换为另一个表达式,研究人员认为,这是机器翻译的一个特殊实例,可以用NLP的方法来解决。
方法主要分为四步:
- 将数学表达式以树的形式表示;
- 引入了seq2seq模型;
- 生成随机表达式;
- 计算表达式的数量。
研究人员在一个拥有5000个方程的数据集中,对模型求解微积分方程的准确率进行了评估。
结果表明,对于微分方程,波束搜索解码能大大提高模型的准确率。
在包含500个方程的测试集上,商业软件中表现最好的是Mathematica。
而当新方法进行大小为50的波束搜索时,模型准确率就从81.2%提升到了97%,远胜于Mathematica(77.2%)
并且,在某一些Mathematica和Matlab无力解决的问题上,新模型都给出了有效解。
展望2020年机器学习
从NLP到计算机视觉,再到强化学习,2020年有很多值得期待的东西。以下是Analytics Vidhya预测的2020年的一些关键趋势:
到2020年,机器学习的职位数量将继续呈指数级增长。很大程度上是由于NLP的发展,许多公司将寻求扩大团队,这是进入该领域的好时机。
数据工程师的作用将更加重要。
AutoML在2018年起飞,但并没有在2019年达到预期高度。明年,随着AWS和Google Cloud的现成解决方案变得更加突出,我们应该更多地关注这一点。
2020年将是我们终于看到强化学习突破的一年吗?几年来一直处于低迷状态,因为将研究解决方案转移到现实世界已证明是一个主要障碍。
























