近来,有越来越多的深度学习框架开始面向移动端进行发展。近日,阿里也基于其 MNN推理引擎开源了最新的 MNNKit深度学习SDK,安卓和 iOS 开发者都可以方便地进行调用。
近年来,很多企业都在研发面向移动端的深度学习框架。在国内有小米的 Mace、腾讯的 FeatherCNN(腾讯AI)和 ncnn(腾讯优图)、百度的 Paddle-moblie 等。而阿里也开发了自己的移动端深度学习框架 MNN。
近日,阿里开源了基于 MNN 引擎的项目 MNNKit,面向安卓和 iOS,以 SDK 的方式提供 AI 端侧推理能力。开发者不需要了解算法细节就可以直接使用。
项目地址:https://github.com/alibaba/MNNKit
目前,MNNKit 已经有人脸检测、手势识别、人像分割等,后续可能有更多 API 接入。
MNNKit: 基于 MNN 的深度学习工具
MNN 是基于阿里的 MNN 端上推理引擎所开发的应用解决方案,主要面向安卓和 iOS 系统,帮助将 AI 能力应用在实际的移动端场景中。
MNNKit 架构
MNNKit 提供了一个 SDK 供开发者使用,以下为 SDK 的架构。
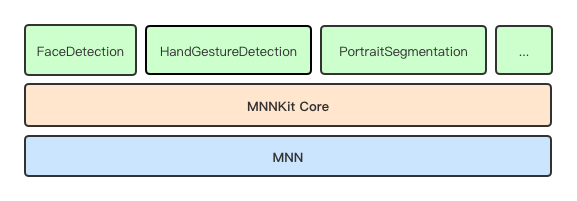
从图中可以看出,MNNKit 可以分为三层结构,从底向上分别为:
-
MNN 引擎层,是 MNN (https://github.com/alibaba/MNN) 库在 Android/iOS 上编译好的包的二进制 Release 版本,提供端侧运行环境。
-
Core 基础层,这主要抽象和封装与 MNN c++接口调用粒度基本一致的上层 API,iOS 通过 OC 接口提供,Android 通过 Java 接口提供(TODO)。这一层同时也为上层 SDK 提供一些公共服务类或结构定义。
-
业务 Kit 层,包括了人脸检测、手势识别封装的 API。据项目介绍,之后的业务 Kit 层会不断扩展。
内部原理
因为 MNNKit 主要提供阿里的端侧 AI 能力,因此封装了很多相关应用的 API。调用如下:
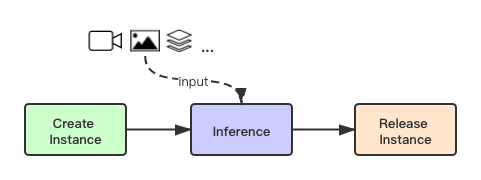
例如,当用户需要调用 API 的时候,需要首先创建实例,然后将图像、视频或其他结构化数据输入,进行 AI 模型的推理工作。工作完成后释放实例即可。
目前 MNNKit 已支持的 API 有:
-
人脸检测API
-
手势识别 API
-
人像分割 API
以人脸检测为例,检测内容主要分为三大板块:
-
人脸基本信息
-
人脸位置的矩形坐标
-
106 个关键点坐标(区分被遮挡的和未被遮挡的)
-
置信度
106 个关键点的分布(来自官方开源 github)
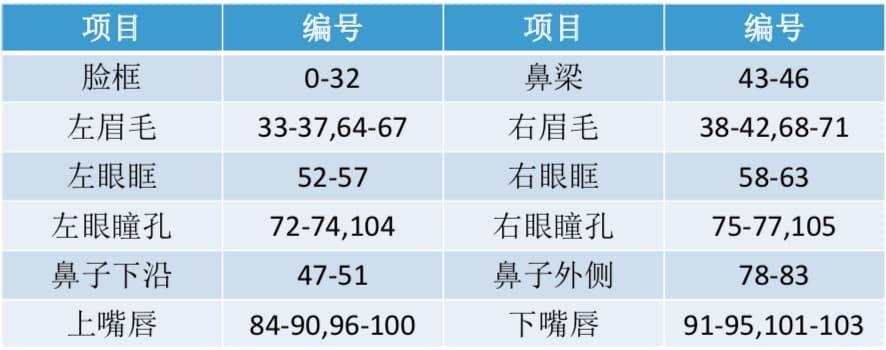
人脸各区域关键点分布对应表
-
欧拉角度
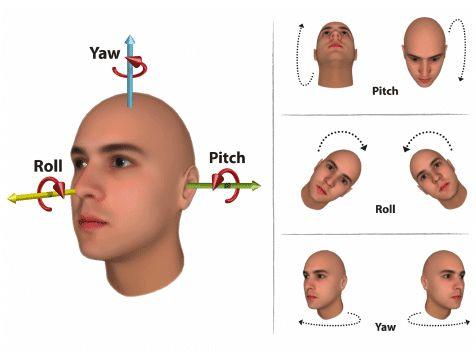
摇头(Yaw)、点头(Pitch)、歪头(Roll)三个角度值
-
人脸动作(包含 5 个人脸的动作)
-
眨眼
-
张嘴
-
摇头
-
点头
-
扬眉
处理过程
我们知道了人脸检测需要检测的数据后,接下来看看处理过程:
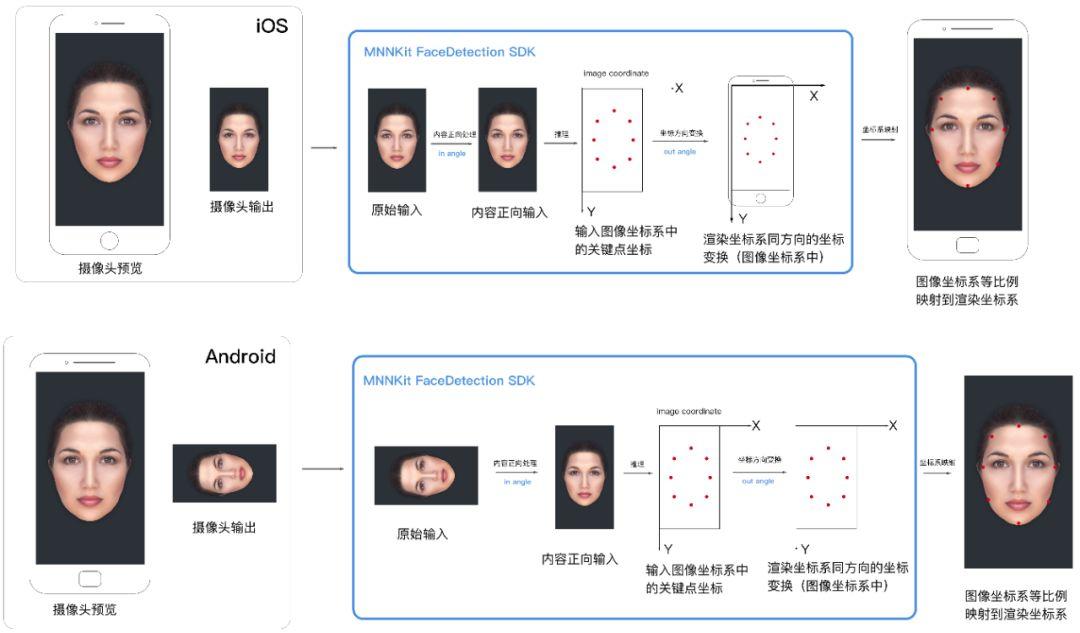
如图所示,该流程是 iOS 和安卓设备后置摄像头正向拍摄后,在移动端上的整体处理过程。
首先,系统从摄像头获取数据,作为 SDK 的输入。接着,SDK 会进行如下操作:
-
在 MNN 引擎执行推理之前,对原始的输入进行预处理,保证输入数据中的人脸为正向
-
使用 AI 模型进行推理;
-
推理后,产生基于输入图像(预处理之后的)坐标系的关键点结果;。
-
把关键点坐标变换到和屏幕渲染坐标系相同的方向,方便渲染。
程应用中,最后的结果关键点要显示在用户屏幕上,前端会使用一个用来渲染的"画布"。画布的坐标系被称为渲染坐标系,
在 SDK 检测的最后一步,我们将关键点变换到和渲染坐标系相同的方向,然后等比例映射关键点坐标到渲染坐标系的坐标即可。映射后可以直接渲染到画布上
代码示例
MNNKit 提供了包括人脸检测、手势识别等方面的示例代码。接下来我们以人脸检测为例,看看怎样可以在安卓或 iOS 中调用 API 进行推理工作。
安卓代码
前文提到,调用 API 需要首先创建一个实例,以下为异步创建 FaceDetector 实例,主线程中回调的代码。
public static void createInstanceAsync (Context context, FaceDetectorCreateConfig createConfig, InstanceCreatedListener<FaceDetector> listener)
在这里,人脸检测API 会进行检测和跟踪两个动作。检测会遭到人脸位置和关键点,而跟踪是在人脸移动时重新定位关键点的位置。
在视频模式下,系统默认每 20 帧检测一次,其余帧只跟踪。图片模式下则每一次调用都检测。
创建实例后,可以将数据输入模型进行推理。MNNKit 现在已支持多种数据格式输入。在视频流检测场景中,我们可以使用摄像头的回调数据作为接口的输入。输入数据的代码如下:
public synchronized FaceDetectionReport[] inference(byte[] data, int width, int height, MNNCVImageFormat format, long detectConfig, int inAngle, int outAngle, MNNFlipType outputFlip)
使用输入数据为 bitmap 的推理代码如下:
public synchronized FaceDetectionReport[] inference(Bitmap bitmap, long detectConfig, int inAngle, int outAngle, MNNFlipType outputFlip)
当 FaceDetector 实例用完之后,我们需要手动释放实例,否则会产生 native 的内存泄露。
public synchronized void release()
iOS 代码
和安卓代码类似,首先需要创建人脸检测实例:
+ (void)createInstanceAsync:(MNNFaceDetectorCreateConfig*)config Callback:(void(^)(NSError *error, MNNFaceDetector *faceDetector))block CallbackQueue:(dispatch_queue_t)callbackQueue;
默认主线程回调:
+ (void)createInstanceAsync:(MNNFaceDetectorCreateConfig*)config Callback:(void(^)(NSError *error, MNNFaceDetector *faceDetector))block;
PixelBuffer 输入进行推理的代码如下:
- (NSArray<MNNFaceDetectionReport *> *)inference:(CVPixelBufferRef)pixelBuffer Config:(MNNFaceDetectConfig)detectConfig Angle:(float)inAngle OutAngle:(float)outAngle FlipType:(MNNFlipType)flipType error:(NSError *__autoreleasing *)error;
UIImage 输入进行推理的代码如下:
- (NSArray<MNNFaceDetectionReport *> *)inferenceImage:(UIImage*)image Config:(MNNFaceDetectConfig)detectConfig Angle:(float)inAngle OutAngle:(float)outAngle FlipType:(MNNFlipType)flipType error:(NSError *__autoreleasing *)error;
使用通用 buffer 数组输入的代码如下:
- (NSArray<MNNFaceDetectionReport *> *)inference:(unsigned char*)data Width:(float)w Height:(float)h Format:(MNNCVImageFormat)format Config:(MNNFaceDetectConfig)detectConfig Angle:(float)inAngle OutAngle:(float)outAngle FlipType:(MNNFlipType)flipType error:(NSError *__autoreleasing *)error;
实例生命周期结束后,会自动触发相关内存的释放,无需调用方手动释放。
据悉,MNNKit 是 MNN 团队在阿里系应用大规模业务实践后的成熟解决方案,历经双十一等项目考验,在不依赖于后端的情况下进行高性能推理,使用起来稳定方便。