作者张建飞是阿里巴巴高级技术专家,入司6年,他创建了COLA。希望可以探索一套切实可行的应用架构规范,这个规范不是高高在上的纸上谈兵,而是可以复制、可以理解、可以落地、可以控制复杂性的指导和约束。本文详述了他对COLA的升级迭代。
很多同学不止一次和我反馈,我们的系统很混乱,主要表现在:
- 应用的层次结构混乱:不知道应用应该如何分层、应该包含哪些组件、组件之间的关系是什么;
- 缺少规范的指导和约束:新加一段业务逻辑不知道放在什么地方(哪个类,哪个包)、应该起什么名字比较合适?
解决这些问题,正是我创建COLA(https://github.com/alibaba/COLA)的初心之一——试图探索一套切实可行的应用架构规范,这个规范不是高高在上的纸上谈兵,而是可以复制、可以理解、可以落地、可以控制复杂性的指导和约束。
自从COLA诞生以来,我收到了很多的意见和建议。同时,我自己在实践过程中,也发现COLA 1.0的诸多不足,有些设计是冗余的并不是很有必要,而有些关键要素并没有囊括。譬如,我最近在思考的应用架构核心和复杂业务代码治理就是对COLA 1.0的反思。
结合实践中的探索和对复杂度治理持续的思考,我决定对COLA进行一次全面的升级,于是有了现在的COLA 2.0。
从1.0到2.0,不仅仅是数字的简单变化,更是架构理念和设计理念的升级,其主要变动点包括:
- 新架构分层:Domain层不再直接依赖Infrastructure层。
- 新组件划分:对组件进行了重新定义和划分,加了新组件,去除了一些老组件(Validator,Convertor等)。
- 新扩展点设计:引入了新概念,让扩展更加灵活。
- 新二方库定位:二方库不仅仅是DTO,也是Domain Model的轻量级表达和实现。
新架构分层
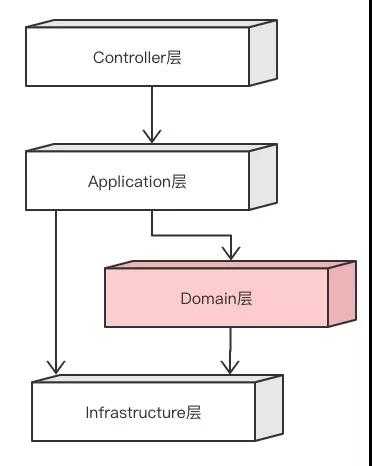
在COLA 1.0中,我们的分层是如下图所示的经典分层结构:
在COLA 2.0中,还是这些层次,但是依赖关系发生了变化,Domain层不再直接依赖Infrastructure层,而是引入了一个Gateway的概念,使用DIP(Dependency Inversion Principle,依赖倒置)反转了Domain层和Infrastructure层的依赖关系,其关系如下图所示:
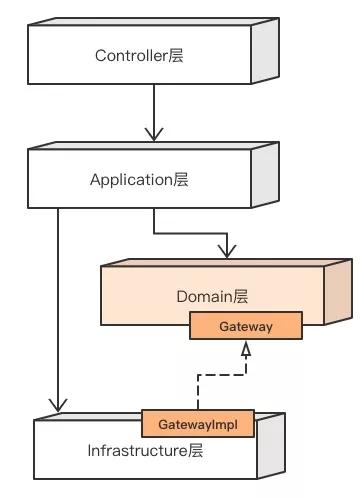
这样做的好处是Domain层会变得更加纯粹,完全摆脱了对技术细节(以及技术细节带来的复杂度)的依赖,只需要安心处理业务逻辑就好了。
除此之外,还有两个好处:
1. 并行开发:只要在Domain和Infrastructure之间约定好接口,可以有两个同学并行编写Domain和Infrastructure的代码。2. 可测试性:没有任何依赖的Domain里面都是POJO的类,单元测试将会变得非常方便,也非常适合TDD的开发。
新组件划分
模块和组件的定义
首先,先明确一下组件(Component)这个概念的定义,组件在Java中(或者说在本文中),其范围就是Java的包(Package)。
还有一个词叫模块(Module),组件和模块这两个概念是比较容易发生混淆的。比如在《实现领域驱动设计》中,作者就说:
If you are using Java or C#, you are already familiar with Modules, though you know them by another name. Java calls them packages. C# calls them namespaces.
他认为Module是Package,我认为这个定义容易造成混淆。特别是在使用Maven的时候,在Maven中,Module是一个Artifact,通常是一个Jar而不是Package。比如COLA Framework就包括如下四个Module:
- <modules>
- <module>cola-common</module>
- <module>cola-core</module>
- <module>cola-extension</module>
- <module>cola-test</module>
- </modules>
的确,Module和Component这两个概念很相近,很容易造成混淆。比如,在StackOverflow上有一个提问【1】,就是问Module和Component之间区别的。获得最高赞的答案是通过Scope来区分的。
The terms are similar. I generally think of a "module" as being larger than a "component". A component is a single part, usually relatively small in scope.
这个回答和我的直觉反应是一致的,即Module比Component要大。根据以上信息,我在此对Module和Component进行一下定义说明,在本文中,都会遵照如下的定义和Notation(表示法)。
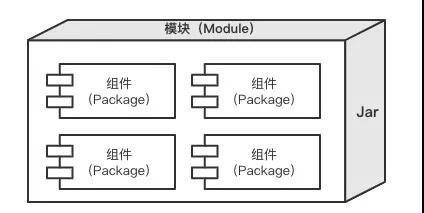
- 模块(Module):和Maven中Module定义保持一致,简单理解就是Jar。用正方体表示。
- 组件(Component):和UML中的定义类似,简单理解就是Package。用UML的组件图表示。
一个Moudle通常是由多个Component组成的,其关系和表示法如下图所示:
COLA 2.0的组件
在COLA 2.0中,我们重新设计了组件,引入了一些新的组件,也去除了一些旧组件。这些变动的宗旨是为了让应用结构更加清晰,组件的职责更加明确,从而更好的提供开发指导和约束。
新的组件结构如下图所示:
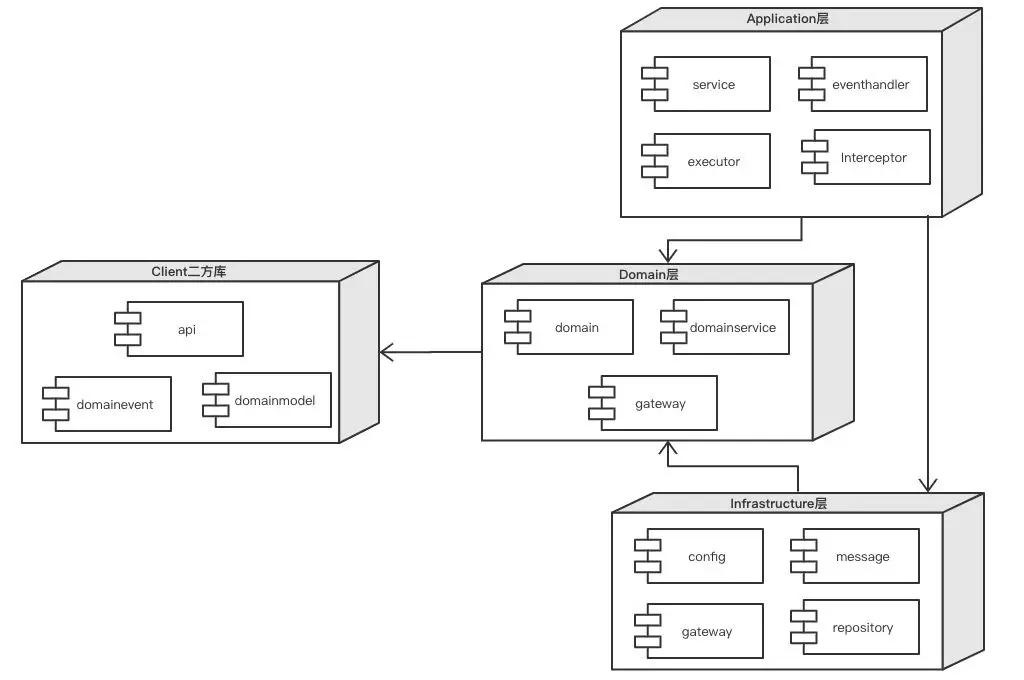
这些组件各自都有自己的职责范围,组件的职责是COLA的重要组成部分,也就是我们上面说的“指导和约束”。这些组件的详细职责描述如下:
二方库里的组件:
- api:存放的是应用对外的接口。
- dto.domainmodel:用来做数据传输的轻量级领域对象。
- dto.domainevent: 用来做数据传输的领域事件。
Application里的组件:
- service:接口实现的facade,没有业务逻辑,可以包含对不同终端的adapter。
- eventhandler:处理领域事件,包括本域的和外域的。
- executor:用来处理命令(Command)和查询(Query),对复杂业务,可以包含Phase和Step。
- interceptor: COLA提供的对所有请求的AOP处理机制。
Domain里的组件:
- domain:领域实体,允许继承domainmodel。
- domainservice: 领域服务,用来提供更粗粒度的领域能力。
- gateway:对外依赖的网关接口,包括存储、RPC、Search等。
Infrastructure里的组件:
- config:配置信息相关。
- message:消息处理相关。
- repository:存储相关,是gateway的特化,主要用来做本域的数据CRUD操作。
- gateway:对外依赖的网关接口(Domain里的gateway)的实现。
在使用COLA的时候,请尽量按照组件规范约束去构建我们的应用。这样可以让我们的应用结构清晰、有章可循。如此这般,代码的可维护性和可理解性会得到极大的提升。
新扩展点设计
引入新概念
在讨论之前,我们先来明确一下在COLA2.0扩展设计中引入的新概念:业务、用例、场景。
- 业务(Business):就是一个自负盈亏的财务主体,比如tmall、淘宝和零售通就是三个不同的业务。
- 用例(Use Case):描述了用户和系统之间的互动,每个用例提供了一个或多个场景。比如,支付订单就是一个典型的用例。
- 场景(Scenario):场景也被称为用例的实例(Instance),包括用例所有的可能情况(正常的和异常的)。比如对于“订单支付”这个用例,就有“可以使用花呗”,“支付宝余额不足”,“银行账户余额不足”等多个场景。
简单来说,就是一个业务是有多个用例组成的,一个用例是有多个场景组成的。用淘宝做一个简单示例,业务、用例和场景的关系如下:
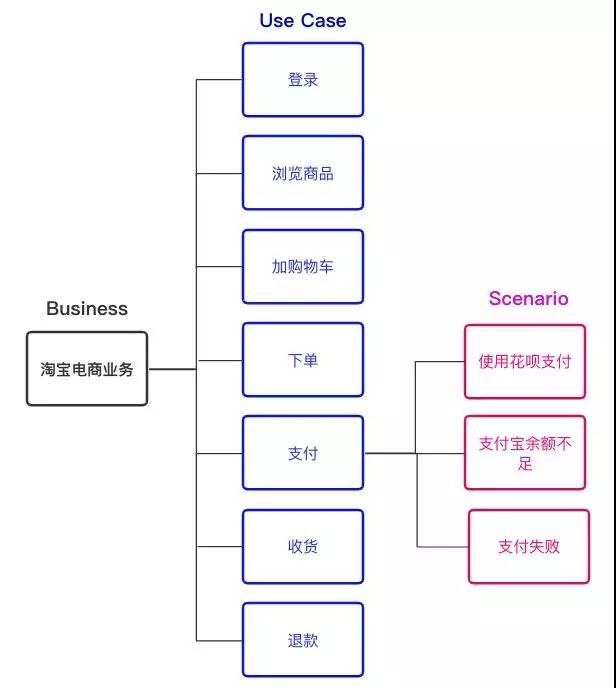
新扩展点的实现
在COLA 2.0中,扩展的实现机制没有变化,主要变化就在于上文中引入的新概念。因为COLA 1.0的扩展设计思想来自于星环,所以当初的扩展粒度也是copy了星环的“业务身份”。COLA 1.0的扩展定位的方法如下图所示:
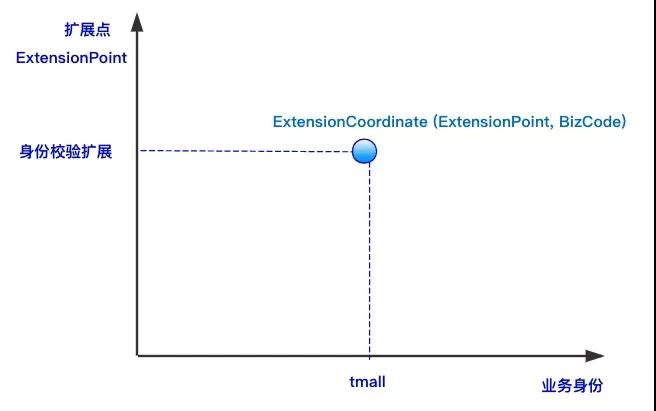
然而,在实际工作中,能像星环那样支撑多个业务的场景并不常见。更多是对不用用例,或是对同一个用例不同场景的差异化支持。比如“创建商品”和“更新商品”是两个用例,但是大部分的业务代码是可以复用的,只有一小部分需要差异化处理。
为了支持这种更细粒度的扩展支持,除了之前的“业务身份(BizId)”之外,我还引入了Use Case和Scenario这两个概念。新的扩展定位如下图所示:
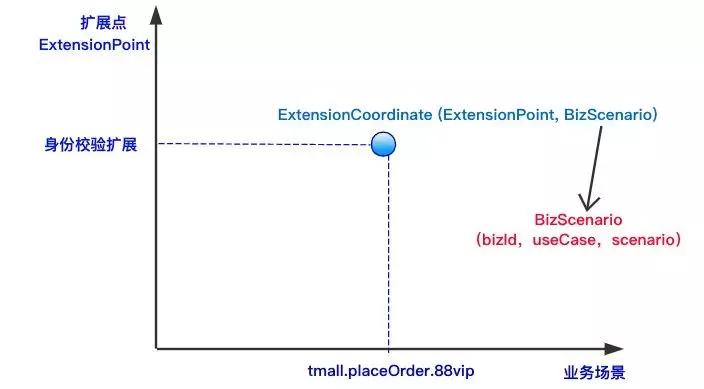
可以看到,在新的扩展框架下,原来只能支持到“业务身份”的扩展,现在可以支持到“业务身份”,“用例”,“场景”的三级扩展,无疑比以前要灵活的多,并且在表达和可理解性上也比以前好。
在新的扩展框架下,例如我们实现上图中所展示的扩展:在tmall这个业务下——的下单用例——的88VIP场景——的用户身份校验进行扩展,我们只需要声明一个如下的扩展实现(Extension)就可以了。

新二方库定位
关于二方库的定位表面上来看,是一个简单问题,因为服务的二方库无外乎就是用来暴露接口和传递数据的(DTO)。不过,往深层次思考,它并不是一个简单的问题,因为它涉及到不同界限上下文(Bounded Context)之间的协作问题。 它是分布式环境下,不同服务(SOA,RPC,微服务,叫法不同,本质一样)之间如何协作的重要架构设计问题。
Bounded Context之间的协作
如何实现不同域之间的协作,同时又要保证各自领域的概念的完整性是有一套方法论的。总体来说,大概有两种方式:共享内核(Shared Kernel)和防腐层(ACL,Anti-Corruption Layer)。
1. 共享内核(Shared Kernel)
It’s possible that only one of the teams will maintain the code, build, and test for what is shared. A Shared Kernel is often very difficult to conceive in the first place, and difficult to maintain, because you must have open communication between teams and constant agreement on what constitutes the model to be shared.
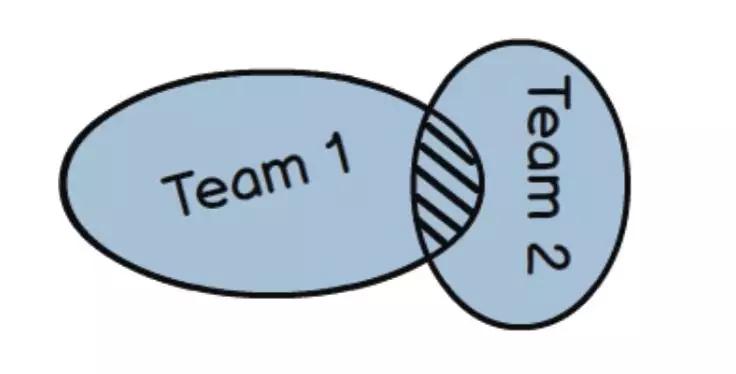
上面是引用《DDD Distilled》(作者是Vaughn Vernon)关于Shared Kernel描述的原话,其优点是Share(减少重复建设),其缺点也是Share(团队之间紧耦合)。
2. 防腐层(ACL,Anti-Corruption Layer)
An Anticorruption Layer is the most defensive Context Mapping relationship, where the downstream team creates a translation layer between its Ubiquitous Language (model) and the Ubiquitous Language (model) that is upstream to it.
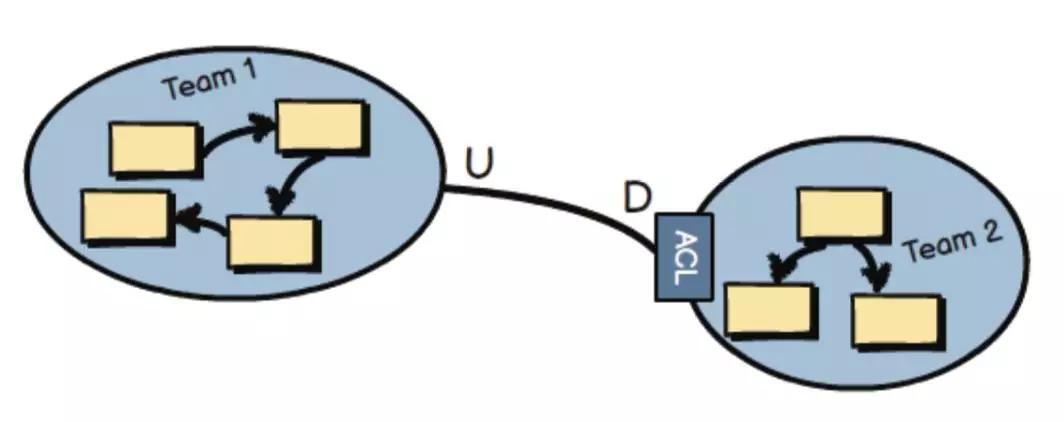
同样是来自于《DDD Distilled》, 防腐层是隔离最彻底的做法,其优点是没有Share(完全解耦,各自独立),其缺点也是没有Share(有一定的转换成本)。
不过我和Vernon的观点差不多,都比较赞成防腐层的做法。因为增加的语义转换陈本,相较于系统的可维护性和可理解性而言,是完全值得的。
Whenever possible, you should try to create an Anticorruption Layer between your downstream model and an upstream integration model, so that you can produce model concepts on your side of the integration that specifically fit your business needs and that keep you completely isolated from foreign concepts.
二方库的重新定位
在大部分情况下,二方库的确是用来定义服务接口和数据协议的。但是二方库区别于JSON的地方是它不仅仅是协议,它还是一个Java对象,一个Jar包。
既然是Java对象,就意味着我们就有可能让DTO承载除了getter,setter之外的更多职能。这个问题以前没有引起我的重视,但是最近在思考domain model的时候,我发现,我们是可以在让二方库承担更多职责的,发挥更大的作用。
实际上,在阿里,我发现有些团队已经在这么实践了,而且我觉得效果还不错。比如,中台的类目二方库,在这个事情上就做了比较好的示范。类目是商品中比较复杂的逻辑,里面涉及很多计算,我们先看一下类目二方库的代码是怎么写的:
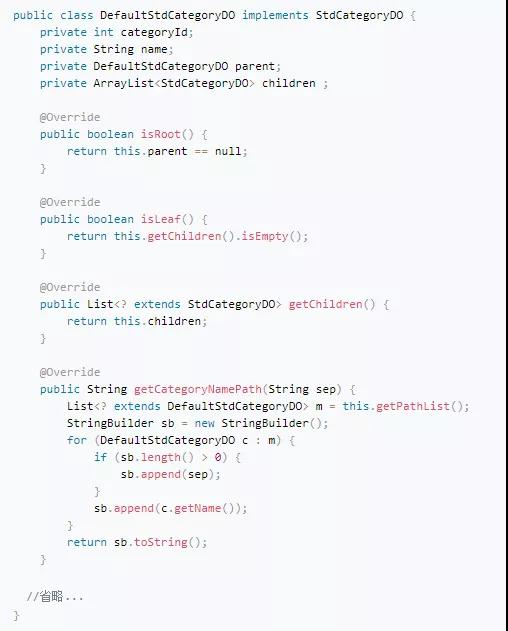
从上面的代码,我们可以发现这已经远远超出DTO的范畴了,这就是一个Domain Model(有数据,有行为,有继承)。这样做合适吗?我认为是合适的:
- 首先,DefaultStdCategoryDO用到的所有数据都是自恰的,即这些计算是不需要借助外面的辅助,自己就能完成。比如判断是否是根类目,是否是叶子类目,获取类目的名称路径等,都是依靠自己就能完成。
- 其次,这就是一种共享内核,我把自己领域的知识(语言、数据和行为)通过二方库暴露出去了,假如有100个应用需要使用isRoot( )做判断,你们都不需要自己实现了。
什么?不是说不推荐共享内核的做法吗?(好吧,小孩子才分对错,好吗)。此处的共享内核我认为是有积极意义的,特别是类目这种轻数据、重计算的场景。不过,共享带来的紧耦合也的确是一个问题。所以如果我是类目服务的Consumer的话,我会选择用一个Wrapper去对Category进行包装复用,这样既可以复用它的领域能力,又可以起到隔离防腐的作用。
COLA中的二方库
说到这里,我想你应该已经理解我对二方库的态度了。是的,二方库不应该仅仅是接口和DTO,而是领域的重要组成部分,是实现Shared Kernel的重要手段。
因此,我打算在COLA 2.0中扩大二方库的职责范围。主要包括两点:
二方库中的domain model也是领域的重要组成部分,是“轻量级”的领域能力表达,所谓“轻量级”是说表达是自恰和足够内聚的,类似于上面说的StdCategoryDO的案例。当然,能力的表达也需要遵循通用语言(Ubiquitous Language)。
不同Bounded Context之间的协作,要充分利用好二方库的桥梁作用。其协作方式如下图所示。
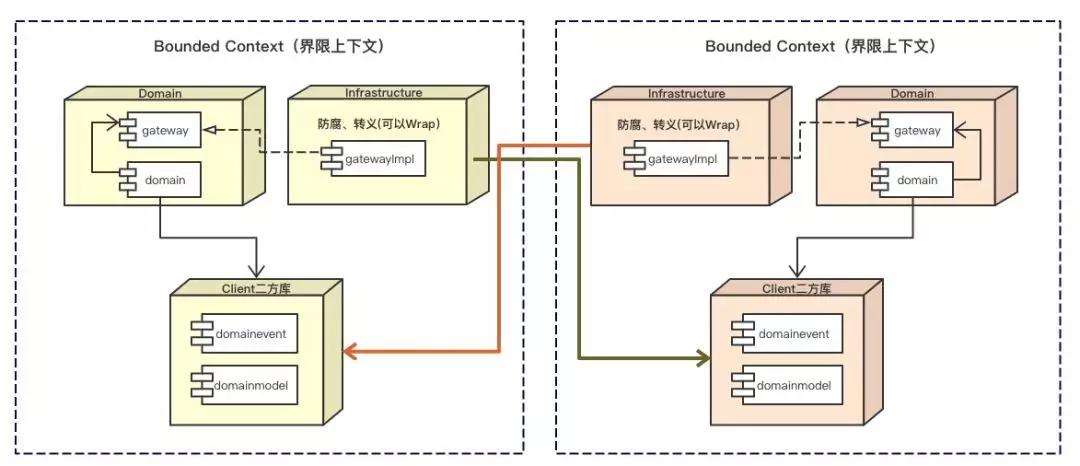
注意,这只是建议,不是标准。实际上,我们永远要在共享和耦合之间做一个权衡,世界上没有完美的架构,也没有完美的设计。 合不合适,还需要你自己根据实际场景自己去定夺。
COLA框架的扩展机制
至此,关于COLA 2.0的改动点我已经交代的差不多了。再追加一个彩蛋吧。泄密一下COLA作为一个框架(Framework)是如何支持扩展的。
框架作为一个组件是被集成在系统中完成某一特定任务的,比如logback作为一个日志框架是帮助我们解决打印日志、日志格式、日志存储等问题的。但面对各种应用场景,框架本身没办法预测你想要的日志格式、日志归档的方式。这些地方需要一个扩展机制,赋能用户自己去配置、去扩展。
就扩展的实现方式而言,一般有两种方式,一种是基于接口的扩展,一种是基于数据配置的扩展。
基于接口的扩展
基于接口的扩展,主要是利用面向对象的多态机制,先在框架中定义一个接口(或者抽象方法)和处理该接口的模板,然后用户实现自己的定制。 其原理如下图所示:
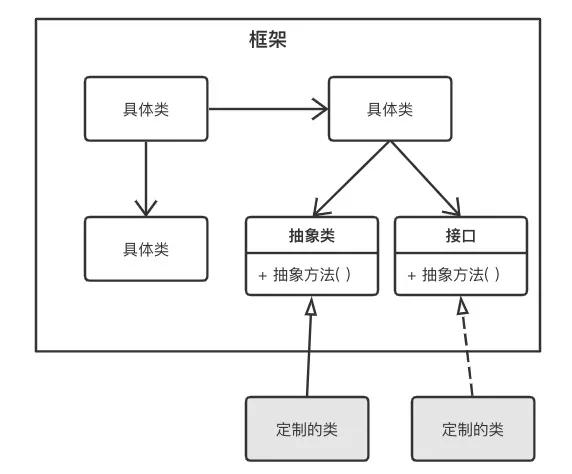
这种扩展方式在框架中使用很广泛,例如Spring中的ApplicationListener,用户可以实现这个Listener来做容器初始化之后的特殊处理。再比如logback中的AppenderBase,用户可以通过继承AppenderBase实现定制的Appender诉求(往消息队列发送日志)。
COLA作为一个框架,这样的扩展能力在所难免,比如,我们有一个ExceptionHandlerI,在框架中我们提供了一个默认实现,代码如下:
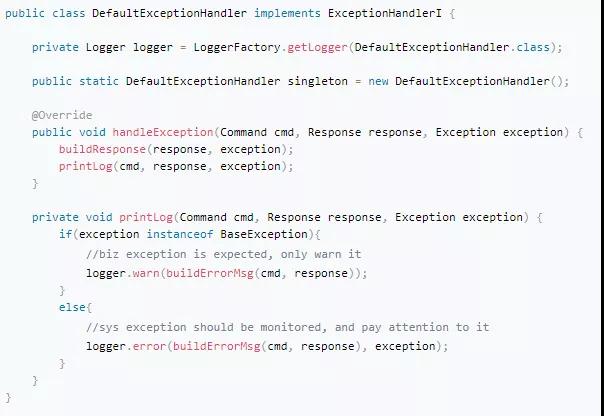
但是,并不是每个应用都愿意这样的安排,因此我们提供了扩展,当用户提供了自己ExceptionHandlerI实现的时候,优先使用用户的实现,如果用户没有提供,使用默认实现:
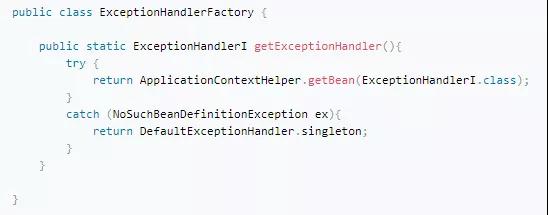
基于数据配置的扩展
基于配置数据的扩展,首先要约定一个数据格式,然后通过利用用户提供的数据,组装成实例对象,用户提供的数据是对象中的属性(有时候也可能是类,比如slfj中的StaticLoggerBinder),其原理如下图所示:
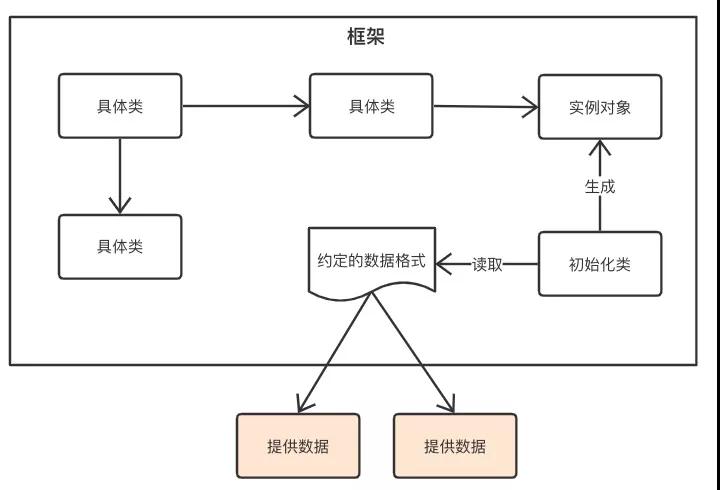
我们一般在应用中使用的KV配置都属于这种形式,框架中的使用场景也很多,比如上面提到的logback中对日志格式、日志大小的logback.xml配置。
在COLA中,我们通过Annotation对扩展点的配置@Extension(bizId = "tmall", useCase = "placeOrder", scenario = "88vip"),也是一种典型的基于数据的配置扩展。
如何使用COLA 2.0
源代码
COLA 2.0的源代码在 https://github.com/alibaba/COLA
生成COLA应用
COLA 2.0 提供了两套Archetype,一套是纯后端应用,另一套是Web后端应用,他们的区别是Web后端应用比纯后端应用多了一个Controller模块,其它都一样。Archetype的二方库我已经上传到Maven Repo了,可以通过如下命令生成COLA应用:
生成纯后端应用(没有Controller)
mvnarchetype:generate -DgroupId=com.alibaba.demo -DartifactId=demo -Dversion=1.0.0-SNAPSHOT-Dpackage=com.alibaba.demo-DarchetypeArtifactId=cola-framework-archetype-service-DarchetypeGroupId=com.alibaba.cola -DarchetypeVersion=2.1.0-SNAPSHOT
生成Web后端应用(有Controller)
mvn archetype:generate -DgroupId=com.alibaba.demo -DartifactId=demo-Dversion=1.0.0-SNAPSHOT -Dpackage=com.alibaba.demo-DarchetypeArtifactId=cola-framework-archetype-web-DarchetypeGroupId=com.alibaba.cola -DarchetypeVersion=2.1.0-SNAPSHOT
我们假设新建的应用叫demo,那么执行命令后,会看到如下的模块结构,上部分是应用骨架,下部分是COLA框架。
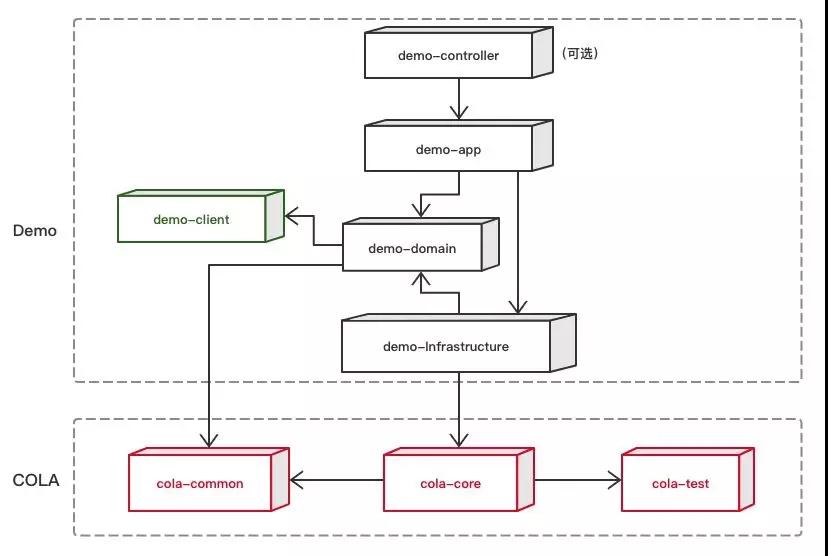
在生成的应用里面有一些demo的代码,可以直接用"mvn test"进行测试。如果是Web后端应用,可以运行TestApplication启动Spring Boot容器,然后直接通过REST URL http://localhost:8080/customer?name=Alibaba 访问服务。
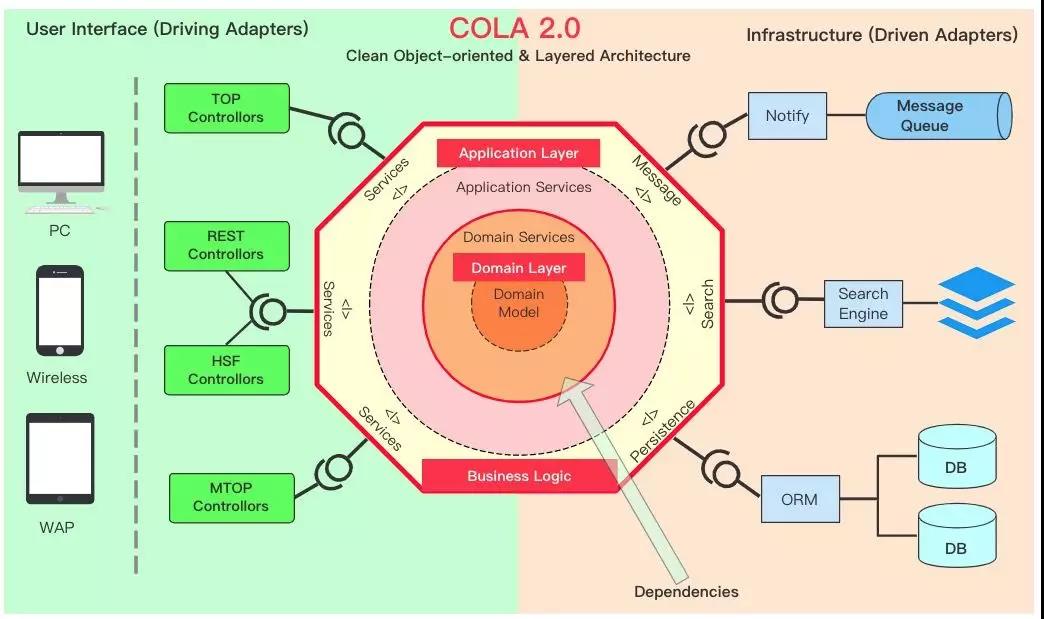
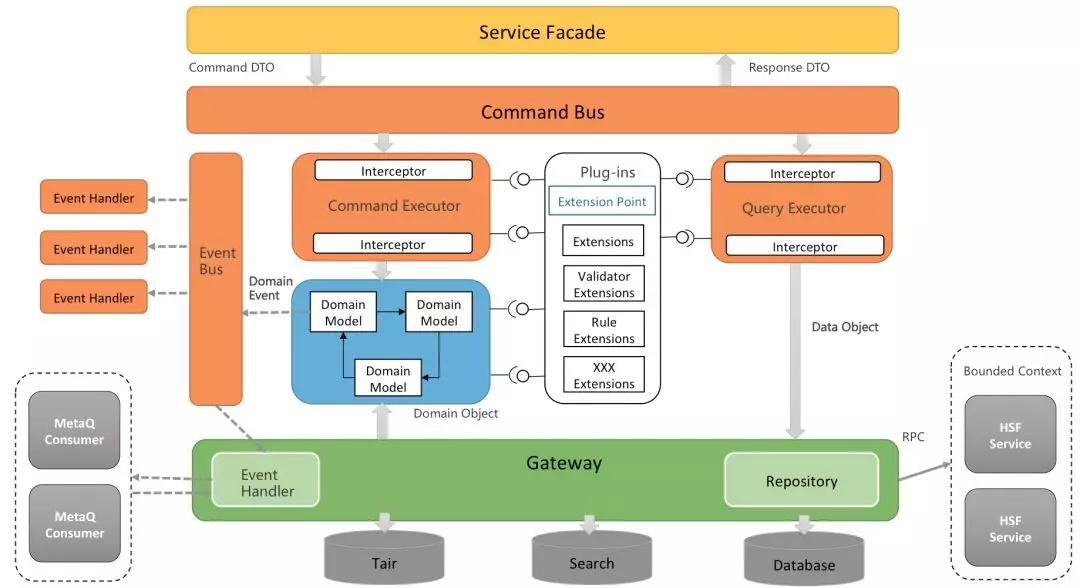
COLA 2.0整体架构
最后,按照老规矩,还是给两张全局的架构视图。以便你可以从全局上把握COLA。
注意:COLA有两层含义,一层含义是作为框架的COLA,主要提供一些应用中所需共用组件的支持。另一层含义是指COLA架构,是指通过COLA Archetype生成的应用骨架的架构。这里所说的架构视图是应用架构视图。
依赖视图
调用视图
参考资料:
【1】https://softwareengineering.stackexchange.com/questions/178927/is-there-a-difference-between-a-component-and-a-module?spm=ata.13261165.0.0.12296659zlPIXl