本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
数据少,又没有预训练模型,怎么破?
给你个秘密武器——自监督学习。

数据科学家 Jeremy Howard 发布一条Twitter:
在医学图像领域,我们经常需要靠一点点的数据来做很多工作。
在这个问题上,有一种被低估的方法,正是自监督学习,简直太神奇!
还附上了与之相关的最新fast.ai教程。

△地址:https://www.fast.ai/2020/01/13/self_supervised/
这一推文立即引起了大量网友的关注,可谓是好评如潮。
这是篇了不起的文章,太酷了!
这是一种简单且强大的技术。
接下来,让我们一起看下,自监督学习到底有多厉害。
自监督学习简介
在多数情况下,训练神经网络都应该从一个预训练(pre-trained)模型开始,然后再对它进行微调。
通过预训练模型,可以比从头开始训练,节省1000倍的数据。
那么试想一下,你所在的领域中,要是没有预训练模型,该怎么办?
例如在医学图像领域,就很少有预先训练过的模型。
而最近有一篇比较有意思的论文,就对这方面问题做了研究。

△论文地址:https://arxiv.org/pdf/1902.07208.pdf
研究发现,即便使用ImageNet模型(预训练过的)中的前几层(early layers),也可以提高医学成像模型的训练速度和最终准确性。
所以说,即便某个通用预训练模型,不在你的研究领域范围内,也可以尝试使用它。
然而,这项研究也指出了一个问题:
其改进程度并不大。
那有没有不需要大量数据,还能取得较好效果的技术呢?
自监督学习就是一个秘密武器。
它可以被看作是机器学习的一种“理想状态”,模型直接从无标签数据中自行学习,无需标注数据。
举个例子,ULMFiT(一种NLP训练方法)的关键就是自监督学习,极大的提高了NLP领域的技术水平。

△论文地址:https://arxiv.org/abs/1801.06146
在基于自监督学习的方法,首先训练了一个语言模型,可以预测某句话的下一个单词。
而当把这个预训练好的模型,用在另一个任务中时(例如情绪分析),就可以用少量的数据,得到最新的结果。
计算机视觉中的自监督学习
在自监督学习中,用于预训练的任务被称为pretext task(前置/代理任务)。
然后用于微调的任务被称为downstream task(下游任务)。
尽管目前在NLP领域中,自监督学习的应用还算普遍,但是在计算机视觉领域中,它却很少使用。
也许是因为诸如ImageNet这样的预训练模型比较成功,所以像医学成像领域中的研究人员,可能不太熟悉自监督学习的必要性。
接下来的内容便展示了CV领域中应用自监督学习的论文例子。
希望越来越多的人可以重视这一关键技术。
图像着色(Colorization)
Colorful Image Colorization

△论文地址:https://arxiv.org/abs/1603.08511
Learning Representations for Automatic Colorization

△论文地址:https://arxiv.org/pdf/1603.06668
Tracking Emerges by Colorizing Videos

△https://arxiv.org/pdf/1806.09594
效果展示

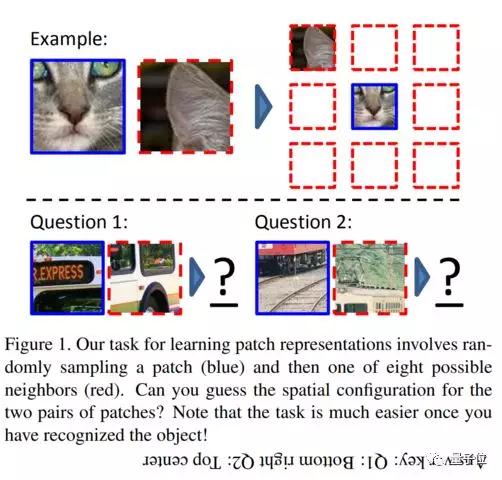
将图像patch放在正确位置
Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles

△论文地址:https://arxiv.org/pdf/1603.09246
Unsupervised Visual Representation Learning by Context Prediction

△论文地址:https://arxiv.org/pdf/1505.05192
效果展示
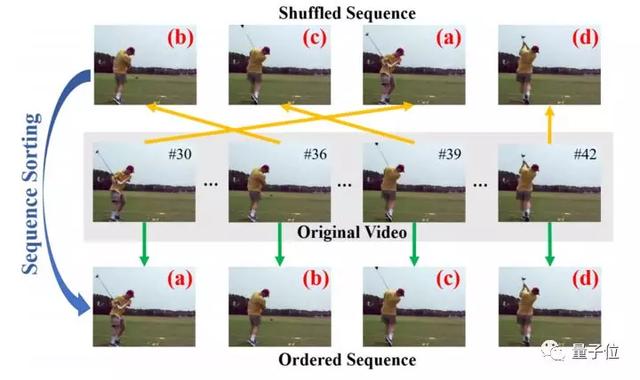
按照正确的顺序放置帧
Unsupervised Representation Learning by Sorting Sequences

△论文地址:https://arxiv.org/pdf/1708.01246
Shuffle and Learn: Unsupervised Learning using Temporal Order Verification

△论文地址:https://arxiv.org/pdf/1603.08561
效果展示
图像修复(Inpainting)
Context Encoders: Feature Learning by Inpainting

△论文地址:https://arxiv.org/pdf/1604.07379
效果展示
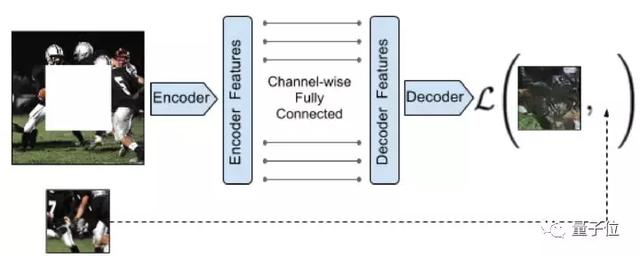
分类损坏的图像
Self-Supervised Feature Learning by Learning to Spot Artifacts

△论文地址:https://zpascal.net/cvpr2018/Jenni_Self-Supervised_Feature_Learning_CVPR_2018_paper.pdf
效果展示
选择一个pretext task
为了在计算机视觉中使用自监督学习,需要回答一个非常重要的问题:
应该使用哪种pretext task?
很多人选择将“自动编码器”作为pretext task。
自动编码器将输入图像转换为一种简化的形式,然后将其再转换回尽可能接近原始图像的内容。
然而,我们不仅需要再生原始图像内容,还需要再生原始图像中的所有噪声。
因此,如果要在下游任务中生成更高质量的图像,那么这将是一个不好的选择。
此外,还需要确保pretext task是人类可以做的事情。
例如,预测视频的下一帧,如果预测时间点过于遥远,那也是不太可行的。
为下游任务进行微调
一旦用pretext task预训练了模型,就可以继续进行微调。
在这一点上,应该把这个问题视为一种迁移学习,不要太多的改变预训练模型的权重。
总体而言,Jeremy Howard不建议浪费太多时间来创建“完美”的pretext模型,而要构建尽可能快速且容易的模型。
然后,需要确保这个pretext模型是否可以满足下游任务。
并且,事实证明,通常不需要非常复杂的pretext 任务,就可以在下游任务中取得较好的结果。
Yann LeCun更好的方法建议
Jeremy Howard在发出这条Twitter之后,深度学习三巨头之一的Yann LeCun对其回复。
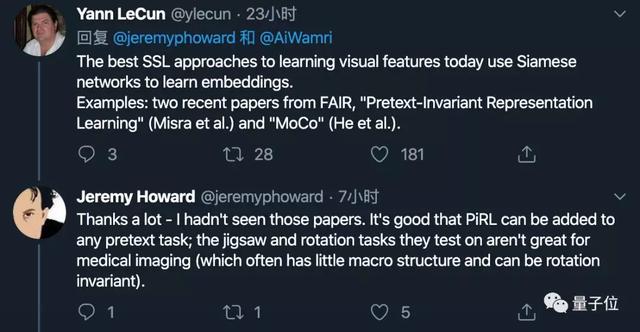
Yann LeCun提出了更好的建议:
现在,学习视觉特征最佳SSL方法是使用孪生神经网络(Siamese network)来学习嵌入。
相关研究包括:
Self-Supervised Learning of Pretext-Invariant Representations

△论文地址:https://arxiv.org/pdf/1912.01991
Jeremy Howard对LeCun回复道:
将PiRL添加到任意pretext task中是非常好的一件事情。
Jeremy Howard
△Jeremy Howard
Jeremy Howard,澳大利亚数据科学家和企业家。fast.ai创始研究人员之一,fast.ai是一家致力于使深度学习更易用的研究所。
在此之前,他曾是Enlitic(位于旧金山的高级机器学习公司)的首席执行官兼创始人。