Transformer 可谓是近年 NLP 领域关注度颇高的模型之一。
- 2017 年,Google 发表题为“Attention Is All You Need”的论文,提出了完全基于注意力机制(attention mechanism)的网络框架 Transformer。
- 2018 年,Google 开源了基于 Transformer 的 BERT 模型,在 NLP 领域大火。
- 2019 年,机器学习领域最大的趋势之一便是基于 Transformer 的自然语言模型的持续增长和扩散。
- 2020 年,根据自然语言处理领域数据集 GLUE 的排行榜,一些表现最佳的模型——包括 Nvidia 的 Megatron、Google 的 XLNet、微软的 MT-DNN 和 Facebook 的 Roberta——都基于 Transformer。
近日,Google 又推出了 Transformer 的“升级版”——Reformer。
【 图片来源:VentureBeat 所有者:VentureBeat 】
比 Transformer 更高效
对人工智能和机器学习模型来说,不管是语言、音乐、语音还是视频,序列数据都不好理解——尤其是在广泛的环境中。例如,如果一个人或一个物体从视频中消失很久后才重新出现,许多算法就会忘记它的样子。
因此,Google 开发了机器翻译模型 Transformer,希望解决这一问题。Transformer 是一个扩展到数千个单词的架构,极大地提升了在完成作曲、图像合成、逐句文本翻译和文档摘要等任务时的性能。
与所有深度神经网络一样,Transformer 包含连接层中的神经元(数学函数),可传输来自输入数据的信号,并缓慢调整每个连接的突触强度(权重),这是所有人工智能模型提取特征和学习预测的方式,但是 Transformer 能独特地注意到每个输出元素都与每个输入元素相关联,它们之间的权重实际上是动态计算的。
不过,Transformer 并不是完美的——将其扩展到更大的环境中就能明显看出局限性。大窗口应用程序的内存从千兆字节到兆兆字节不等,也就是说模型只能吸收几段文本或生成一小段音乐。
基于此,Google 推出 Reformer 作为 Transformer 的演进,Reformer 能够处理多达 100 万字的环境,仅用 16GB 的存储器就能在单个 AI 加速器芯片上运行。

雷锋网(公众号:雷锋网)了解到,相关论文“Reformer:The Efficient Transformer”已被将于 2020 年 4 月在埃塞俄比亚举行的自然语言处理顶会 ICLR-2020(International Conference on Learning Representations)接收,当前模型也已开源。
根据论文,Reformer 主要包含以下技术:
- 第一,可逆层在整个模型中只存储激活函数的单个副本,因此 N 因子消失;
- 第二,在前馈层内拆分激活函数,并进行分段处理,消除 dff 因子,节省前馈层内存;
- 第三,利用局部敏感哈希(雷锋网注: LSH,即一种哈希算法,主要运用到高维海量数据的快速近似查找)。具体来讲,哈希函数即一种将任意大小的数据映射到固定大小的值的函数,该函数匹配相似的向量(即表示机器学习中人类可读数据的代数构造),而不是在所有可能的向量对中搜索。
例如,在翻译任务中,来自网络第一层的每个向量表示一个词,对应于不同语言中相同词的向量可以获得相同的哈希值。当分配哈希时,序列会重新排列,接着按元素的哈希值分类,实现并行处理,这样降低了长序列的复杂度,极大地减少了计算负荷。
Reformer 可处理整部小说
为验证 Reformer 确实能够在单个 GPU 上运行,并可在长序列上快速训练,研究人员在 enwik8 和 imagenet64 数据集上对 20 层的 Reformer 模型进行了训练。实验表明,Reformer 能达到与 Transformer 相同的性能,并且内存效率更高,在长序列任务上训练更快。
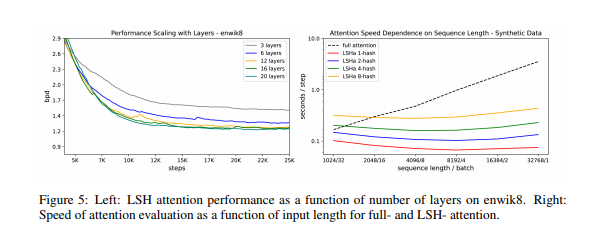
另外,研究小组还对基于 Reformer 的图像和文本模型进行了实验,用它们生成图像中缺失的细节,还处理了小说《罪与罚》(包含约 211591 个单词)全文。研究表明,Reformer 能够逐像素地生成全帧图像,并且能够在单轮训练中接收小说长度的文本。
Google 科学家 Łukasz Kaiser 和加州大学伯克利分校学生 Nikita Kitaev 都对这项研究作出了贡献,他们在一篇博客中写道:
- 由于 Reformer 效率极高,它可以直接应用于上下文窗口远大于当前几乎所有最先进文本域的数据,Reformer 处理如此庞大数据集的能力可能也会刺激社区创建数据集。
据悉,论文作者们还会进一步将该其应用于更广阔的领域(如时间序列预测及音乐、图像、视频生成),并改进对位置编码的处理。Łukasz Kaiser 和 Nikita Kitaev 补充说:
我们相信 Reformer 为将来使用 Transformer 模型对长文本和自然语言处理以外的应用也打下了基础。
2019 年年底,外媒 VentureBeat 曾采访过 Google 高级副总裁 Jeff Dean,他在采访中表示:
- Google 仍然希望能建立更多的情境模型,就像现在一样,BERT 等模型可以处理数百个单词,但不能处理 1 万个单词。所以这会是 Google 未来主要关注的方向。
而 Reformer 似乎是朝着这一方向迈出的充满希望的第一步。
本文转自雷锋网,如需转载请至雷锋网官网申请授权。