陆续分享了几套数据库平台的常用函数,就有读者反映:总是这些简单的知识点捣腾来捣腾去,有意思吗?敢不敢来点高级的?
读者有需要,怎么可能不满足呢?但是又要讲的大家都明白,所以花了不少时间做示例演示,今天就分享给大家。
测试环境
SQL Server 2017
CHARINDEX
作用
会在第二个字符表达式中搜索一个字符表达式,这将返回第一个表达式(如果发现存在)的开始位置。
语法
CHARINDEX ( expressionToFind , expressionToSearch [ , start_location ] )
注:这是一个常用的字符搜索函数,起始下标是1,不是0。
如果加了起始下标,会从忽略起始下标前面的字符,往后面搜索。
不加起始值示例
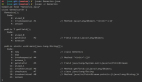
- SELECT CHARINDEX('数据','SQL数据库开发SQL数据库开发')
结果

添加起始值示例
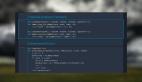
- SELECT CHARINDEX('数据','SQL数据库开发SQL数据库开发',6)
结果

CONCAT_WS
作用
以端到端的方式返回从串联或联接的两个或更多字符串值生成的字符串。 它会用第一个函数参数中指定的分隔符分隔连接的字符串值。 (CONCAT_WS 指示使用分隔符连接。)
语法
CONCAT_WS ( separator, argument1, argument2 [, argumentN]... )
注:CONCAT_WS 会忽略列中的 NULL 值。 用 ISNULL 函数包装可以为 null 的列,并提供默认值。
示例
- SELECT CONCAT_WS('-','SQL','数据库',NULL,'开发')
结果:

SOUNDEX
作用
返回一个由四个字符组成的代码 (SOUNDEX),用于评估两个字符串的相似性。
语法
SOUNDEX ( character_expression )
注:SOUNDEX 会根据字符串的发音,将字母数字字符串转换成一个由四个字符组成的代码。 该代码的第一个字符是 character_expression 的第一个字符,已转换为大写 。 代码的第二个字符到第四个字符是表示表达式中的字母的数字。 除非字母 A、E、I、O、U、H、W 和 Y 是字符串的首字母,否则将忽略这些字母。 如果需要生成一个四字符代码,将在末尾添加零
示例
- SELECT SOUNDEX ('liyue'), SOUNDEX ('liyuee')
结果:

说明两个的发音非常接近
DIFFERENCE
作用
返回一个整数值,用于度量两个不同字符表达式的 SOUNDEX() 值之间的差异
语法
DIFFERENCE ( character_expression , character_expression )
注:DIFFERENCE 比较两个不同的 SOUNDEX 值,并返回一个整数值。 该值用于度量 SOUNDEX 值匹配的程度,范围为 0 到 4。 值为 0 表示 SOUNDEX 值之间的相似性较弱或不相似;4 表示与 SOUNDEX 值非常相似,甚至完全相同。
DIFFERENCE 和 SOUNDEX 具有排序规则敏感度。
示例
- SELECT
- SOUNDEX ('liyue'), SOUNDEX ('liyuee') ,
- DIFFERENCE('liyue', 'liyuee');
结果:

返回的结果为4,进一步验证了我们上一个函数。
FORMAT
作用
返回使用指定格式和可选区域性格式化的值。 使用 FORMAT 函数将日期/时间和数字值格式化为识别区域设置的字符串。 对于一般的数据类型转换,请使用 CAST 或 CONVERT。
语法
FORMAT ( value, format [, culture ] )
注意
- FORMAT 将返回 NULL 错误,而不是非 valid 的 culture 。 例如,如果 format 中指定的值无效,则返回 NULL 。
- FORMAT 函数具有不确定性。
- FORMAT 依赖于 .NET Framework 公共语言运行时 (CLR) 的存在。
- 此函数无法进行远程处理,因为它依赖于 CLR 的存在。 远程处理需要 CLR 的函数可能导致在远程服务器上出现错误。
日期格式示例
- DECLARE @d DATETIME = '12/18/2019';
- SELECT FORMAT ( @d, 'd', 'en-US' ) AS '美国格式'
- ,FORMAT ( @d, 'd', 'en-gb' ) AS '英国格式'
- ,FORMAT ( @d, 'd', 'de-de' ) AS '德国格式'
- ,FORMAT ( @d, 'd', 'zh-cn' ) AS '中文格式';
- SELECT FORMAT ( @d, 'D', 'en-US' ) AS '美国格式'
- ,FORMAT ( @d, 'D', 'en-gb' ) AS '英国格式'
- ,FORMAT ( @d, 'D', 'de-de' ) AS '德国格式'
- ,FORMAT ( @d, 'D', 'zh-cn' ) AS '中文格式';
结果


自定义格式示例
- SELECT FORMAT( GETDATE(), 'dd/MM/yyyy', 'zh-cn' ) AS '自定义日期'
- ,FORMAT(123456789,'###-##-####') AS '自定义数字';
结果

数值格式示例
- SELECT FORMAT(1.127456, 'N', 'zh-cn') AS '四舍五入格式'
- ,FORMAT(1.123456, 'G', 'zh-cn') AS '一般格式'
- ,FORMAT(1.123456, 'C', 'zh-cn') AS '货币格式'
结果

PATINDEX
作用
返回模式在指定表达式中第一次出现的起始位置;如果在所有有效的文本和字符数据类型中都找不到该模式,则返回零。该函数与CHARINDEX比较相似
语法
PATINDEX ( '%pattern%' , expression )
注:
- 如果 pattern 或 expression 为 NULL,则 PATINDEX 返回 NULL 。
- PATINDEX 的起始位置为 1。
- PATINDEX 基于输入的排序规则执行比较。 若要以指定排序规则进行比较,则可以使用 COLLATE 将显式排序规则应用于输入。
示例
- SELECT PATINDEX('%数据库%', 'SQL数据库开发');
结果

在 PATINDEX 中使用通配符示例
使用 % 和 _ 通配符查找模式 '数'(后跟任意一个字符和 '库')在指定字符串中的开始位置(索引从 1 开始)
- SELECT PATINDEX('%数_库%', 'SQL数据库开发');
结果

QUOTENAME
作用
返回带有分隔符的 Unicode 字符串,分隔符的加入可使输入的字符串成为有效的 SQL Server 分隔标识符。
语法
QUOTENAME ( 'character_string' [ , 'quote_character' ] )
注
'character_string'
Unicode 字符数据构成的字符串。 character_string 是 sysname,且最多具有 128 个字符 。 超过 128 个字符的输入将返回 NULL。
'quote_character'
用作分隔符的单字符字符串。 可以是单引号 (')、左方括号或右方括号 ([])、双引号 (")、左圆括号或右圆括号 (())、大于或小于符号 (><)、左大括号或右大括号 ({}) 或反引号 (`) 。 如果提供了不可接受的字符,则返回 NULL。 如果未指定 quote_character,则使用方括号 。
示例
- SELECT QUOTENAME('abc[]def');
结果

REPLICATE
作用
以指定的次数重复字符串值。
语法
( string_expression ,integer_expression )
示例
- SELECT '2'+REPLICATE ('3',5)
结果

REVERSE
作用
返回字符串值的逆序。
语法
REVERSE ( string_expression )
示例
- SELECT REVERSE('SQL数据库开发')
结果

STRING_AGG
作用
串联字符串表达式的值,并在其间放置分隔符值。 不能在字符串末尾添加分隔符。
语法
STRING_AGG ( expression, separator ) [ <order_clause> ]
注意:
- STRING_AGG 是一个聚合函数,用于提取行中的所有表达式,并将这些表达式串联成一个字符串。 表达式值隐式转换为字符串类型,然后串联在一起。 隐式转换为字符串的过程遵循现有的数据类型转换规则。
- 如果输入表达式的类型为 VARCHAR,则分隔符的类型不能是 NVARCHAR。
- null 值会被忽略,且不会添加相应的分隔符。 若要为 null 值返回占位符,请使用 ISNULL 函数,如示例 B 中所示。
- STRING_AGG 适用于任何兼容级别。
示例
- WITH t AS (
- SELECT '张三' Name,'语文' Course,89 Score
- UNION ALL
- SELECT '张三' ,'数学' ,91
- UNION ALL
- SELECT '李四' ,'语文' ,78
- UNION ALL
- SELECT '李四' ,'数学' ,96
- )
- SELECT Name,
- STRING_AGG(Course,',') Course ,
- STRING_AGG(Score,',') Score
- FROM t
- GROUP BY Name
结果

STRING_SPLIT
作用
一个表值函数,它根据指定的分隔符将字符串拆分为子字符串行。
语法
STRING_SPLIT ( string , separator )
注意
STRING_SPLIT 输入包含分隔子字符串的字符串,并输入一个字符用作分隔符。 STRING_SPLIT 输出其行包含子字符串的单列表。 输出列的名称为“value”。
输出行可以按任意顺序排列。 顺序不保证与输入字符串中的子字符串顺序匹配。 可以通过在 SELECT 语句中使用 ORDER BY 子句覆盖最终排序顺序 (ORDER BY value)。
当输入字符串包含两个或多个连续出现的分隔符字符时,将出现长度为零的空子字符串。 空子字符串的处理方式与普通子字符串相同。 可以通过使用 WHERE 子句筛选出包含空的子字符串的任何行 (WHERE value <> '')。 如果输入字符串为 NULL,则 STRING_SPLIT 表值函数返回一个空表。
示例一
- SELECT Value FROM STRING_SPLIT('SQL-数据库-开发', '-');
结果

示例二
- WITH t AS (
- SELECT 1 ID,'张三' Name,'足球,篮球,羽毛球' Hobby
- UNION ALL
- SELECT 2 ,'李四','足球,游泳,爬山'
- )
- SELECT ID, Name, Value
- FROM t
- CROSS APPLY STRING_SPLIT(Hobby, ',');
结果

注意:返回的列不再是Hobby,而是Value,必须写成Value,否则得不到想要的结果。这个与STRING_AGG()函数的功能相反。
STUFF
作用
STUFF 函数将字符串插入到另一个字符串中。 它从第一个字符串的开始位置删除指定长度的字符;然后将第二个字符串插入到第一个字符串的开始位置。
语法
STUFF ( character_expression , start , length , replaceWith_expression )
注意:
- 如果开始位置或长度值是负数,或者开始位置大于第一个字符串的长度,则返回 Null 字符串。 如果开始位置为 0,则返回 Null 值。如果要删除的长度大于第一个字符串的长度,则删除到第一个字符串中的第一个字符。
- 如果结果值大于返回类型支持的最大值,则会引发错误。
示例
- SELECT STUFF('abcdef', 2, 3, 'ijklmn');
结果

以上就是今天要给大家介绍的高级字符函数,下次我们再给大家介绍高级日期函数的相关用法。