最近遇到了一个任务折腾了我一个周多,终于跑成功了,解决的过程就是一个渐渐认清大数据计算原理的过程,希望对大家有帮助。
一、任务背景
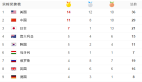
1.1 资源一:一个表
现在有一个表,名为Item 有item_group, item_id, feature 三个字段,分别代表物品所在的类别,物品ID,物品的特征 如下图:
2.2 资源二:相似度函数
还有一个函数F(feature1, feature2) 输入两个物品的feature,返回这两个物品的相似度。
2.3 目标
现在需要计算的是在同一个类别下物品之间两两的相似度。
2.4 相关信息
1.item表总共300万条记录,parquet格式来存储,总大小36G2.总共有1.5万个item_group,最大的一个item_group有8000多个item3.feature是个json字符串,每个大概有8万Byte,约80K4.函数F平均一分钟处理10000条数据
大家可以帮我想想,如果你来做这个任务要怎么进行计算呢。
二、我的尝试
2.1 方案1:item和item join
上来就啥都没想,item和item用item_group join一下就能得到同一个item_group下的两两组合(这里我们成为item_pair),就可以计算相似度了。so easy。
- select a.item_id id1, b.item_id id2, F(a.feature, b.feature) score from item a join item b on a.item_group = b.item_group and a.item_id>b.item_id
非常完美清晰,简单即有效,所有的数据基本都只用计算一次。然鹅几个小时之后:
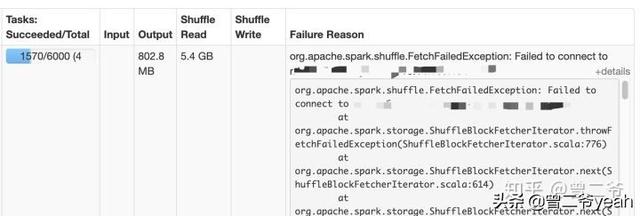
- org.apache.spark.shuffle.MetadataFetchFailedException: Missing an
- output location for shuffle 0
什么鬼读取shuffle失败,再仔细一看原来是熟悉的OOM(out of memory)。
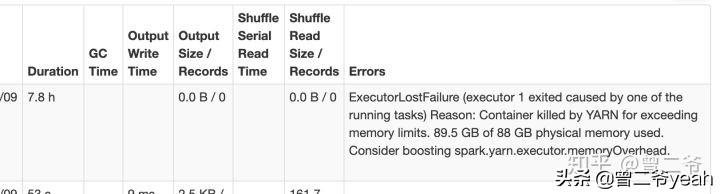
- ExecutorLostFailure (executor 20 exited caused by one of the running
- tasks) Reason: Container killed by YARN for exceeding memory
- limits. 90.4 GB of 88 GB physical memory used. Consider boosting
- spark.yarn.executor.memoryOverhead.
遇到这种状况加内存、加shuffle分区数(设置spark.sql.shuffle.partitions)这是常规操作
然鹅几个小时之后又挂了,还是一样的问题。难道是feature太大了?后来我把feature进行了压缩,从80k一下子压缩到了8K,结果又双叒挂了
方案1彻底卒。
2.2 方案2 先生成pair
冷静!我要冷静下来分析。既然是feature占了主要的内存,那我前期可以先不带上feature,先计算出需要计算的item_pair,第二步在计算的时候join上feature就可以了呀,我真是太聪明了。方案2:
- select a.item_id id1, b.item_id id2,from item ajoin item b on a.item_group = b.item_group and a.item_id>b.item_id
存为item_pair表然后再join feature 计算分数
- select id1, id2, F(a.feature, b.feature) scorefrom item_pairjoin
- item a on item_pair.id1=a.item_idjoin item b on
- item_pair.id2=b.item_id
结果又双叒叕过了好多个小时,item_pair表跑出来了正高兴着,结果第二部分,依旧挂掉,依旧memoryOverhead。怀疑人生了。
三、真正的认真分析
多次的失败终于使我冷静了下来,认真回忆起了spark相关的知识。下面是我认真的分析:
3.1 上文方案1的分析:
按照item_group自己和自己join的话,会如下图。下游会按照item_group聚集起来做join。
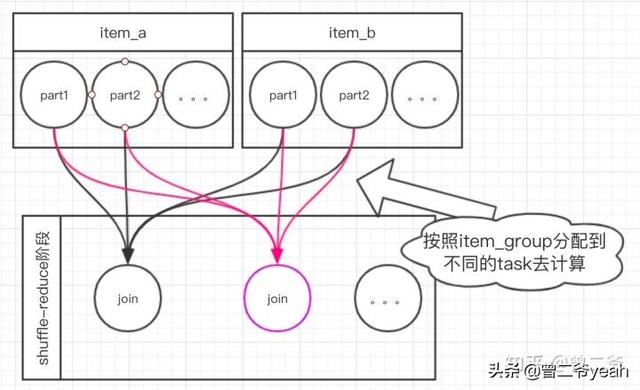
我们来计算一下:
- 表中最大一个group有8000个item。
- 生成不重复的pair也会有组合数C(n,2)=n×(n-1)/2=31996000,3千万个pair。
- 每个feature优化之后占8K,一个pair就是16K,3千万就是480G,也就是一个group就要占480G,何况shuffle时一个task里不止一个group。
经过计算内存不爆那是不可能的。
3.2 方案2的分析:
生成item_pair 基本不耗什么内存,最终生成20亿条item_pair。到了第二步的时候我们来看看,数据是怎么流动的。如下图:
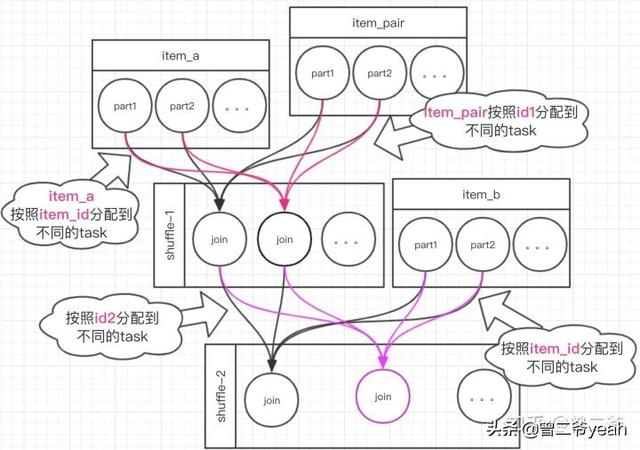
第一阶段item_pair按照id1去分组,分发到下游的节点,我们按最做多那个ID计算的话有至少有8000条数据会被分到一个分区结合上feature字段,也就是会生成64M的数据。
这还是单个item_id,总共有300万个item_id,不可能shuffle的时候用300万个分区每个分区一个item_id吧,就算每个分区放1000个题目需要占64个G,要3000个分区。
第二阶段数据加上id2的feature,数据量会扩大一倍变成128G,3000个分区。看样子能行,但是实际操作起来耗费的内存可比这个大很多,而且分区太多出现各种奇怪的问题,比如shuffle文件丢失啥的,而且之后group下面的题目增多就只能不断扩大内存了,实在不是个好办法。得考虑其他的方案了。
四、最后的解决方案
4.1 在item_group总切分成多个组合数的子任务
item_group总共就1.5万个,最多的一个有8000个feature,也就64M,麻烦的点就在于要在item_group里求组合数(两两配对)。
能不能把求组合数这一步切分成不同的子任务,再在每个子任务里去求组合数,这样不但能减少内存消耗,还能增加并行度。
我们来画个组合数的图。
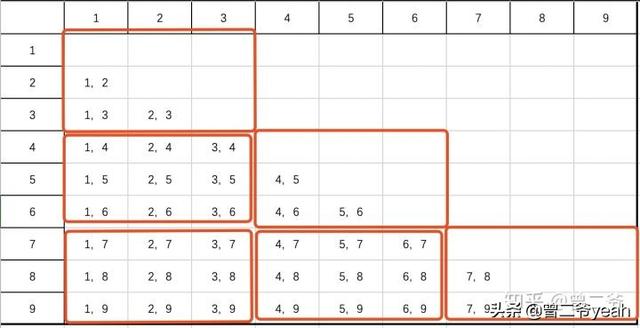
上图我们可以按照阈值为3进行分割,就可以把整个图切分成几个小子图进行计算了。
实际进行的时候如果我们按500进行分割的话,8000个item的group可以分成136个子任务,子任务中最大的一个会有500×500=250000个pair,但数据的话就只需要传最多1000个feature也就是8M的数据,子任务数就算在原有不切割的15000个group上扩增1.5倍也就是15000×1.5=22500个,设置2000个分区,每个分区11个子任务,内存耗费11×8M=88M,共计算250000×11次,每1万次一分钟,也就是一个分区得跑4个小时左右,实际上也差不多。
五、总结和问题
总结起来就是最开始太自信了。
- 没有仔细的思考
- 没有认真调查数据的规模
- 没有认真考虑在每个方案数据是怎么在spark中流动
- 没有认真做计算。