分布式强化学习是智能体在围棋、星际争霸等游戏中用到的技术,但 DeepMind 的一项研究表明,这种学习方式也为大脑中的奖励机制提供了一种新的解释,即大脑也应用了这种算法。这一发现验证了分布式强化学习的潜力,同时也使得 DeepMind 的研究人员越发坚信,「现在的 AI 研究正走在正确的道路上」。
多巴胺是人们所熟悉的大脑快乐信号。如果事情的进展好于预期,大脑释放的多巴胺也会增多。
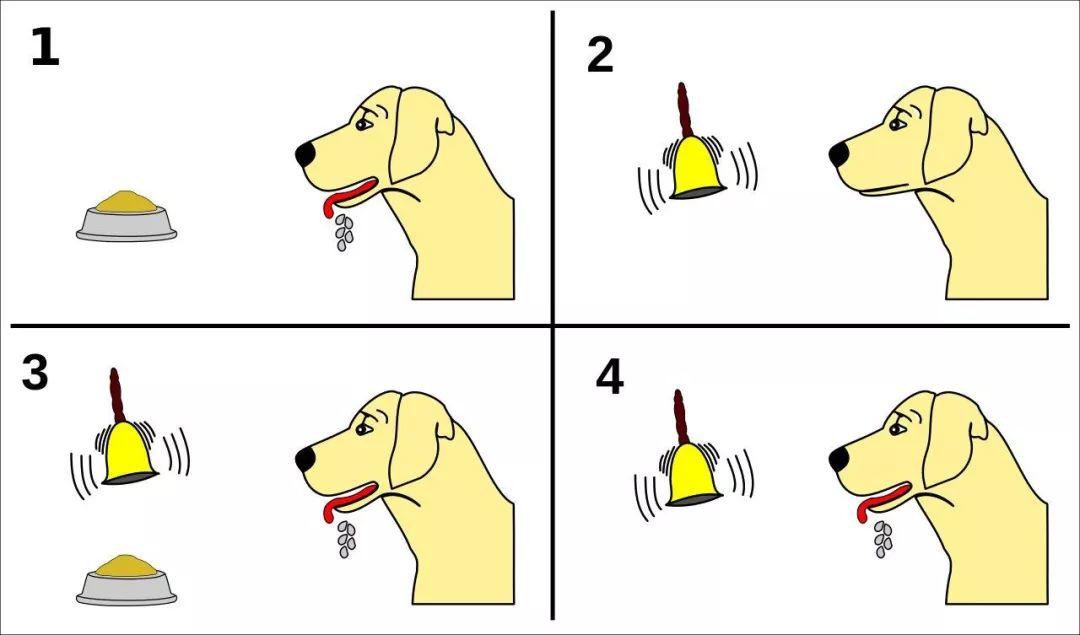
在人脑中存在奖励路径,这些路径控制我们对愉悦事件的反应,并通过释放多巴胺的神经元进行介导。例如,在著名的巴布洛夫的狗实验中,当狗听到铃声便开始分泌口水时,这一反应并非已经获得了奖励,而是大脑中的多巴胺细胞对即将到来的奖励产生的一种预测。
之前的研究认为,这些多巴胺神经元对奖励的预测应当是相同的。
但近日,DeepMind 的研究人员通过使用分布式强化学习算法发现,每个多巴胺神经元对奖励的预测很不相同,它们会被调节到不同水平的「悲观」和「乐观」状态。研究者希望通过这套算法研究并解释多巴胺细胞对大脑的行为、情绪等方面的影响。这份研究成果昨日登上了《Nature》。

Nature 论文链接:https://www.nature.com/articles/s41586-019-1924-6
强化学习算法和多巴胺奖惩机制研究
强化学习算是神经科学与 AI 相连接的最早也是最有影响力的研究之一。上世纪 80 年代末期,计算机科学研究者试图开发一种算法,这种算法仅依靠奖惩反馈作为训练信号,就可以单独学会如何执行复杂的行为。这些奖励会加强使其受益的任何行为。
解决奖励预测问题的重要突破是时序差分算法(TD),TD 不会去计算未来的总体回报,它尝试预测当前奖励和未来时刻预期奖励之和。当下一个时刻来临时,将新的预测结果与预期中的相比,如果有出入,算法会计算二者之间的差异,并用此「时序差分」将旧版本的预测调整为新的预测。
不断训练之后,「预期」和「现实」会逐渐变得更加匹配,整个预测链条也会变得越来越准确。
与此同时,很多神经科学研究者们,专注于多巴胺神经元的行为研究。当面对即将到来的奖励时,多巴胺神经元会将「预测」和「推断」的值发送给许多大脑区域。
这些神经元的「发送」行为与奖励的大小有一定关系,但这些反应常常依靠的是外部感性信息输入,并且在给定任务中的表现也会随着生物体经验的丰富而改变。例如,对于特定的刺激产生的奖励预测变少了,因为大脑已经习惯了。
一些研究者注意到,某些多巴胺神经元的反应揭示了奖励预测的漏洞:相比于被训练应该生成的那种「预期」,它们实际发送的预期总是或多或少,和训练的预期不太一样。
于是这些研究者建议大脑使用 TD 算法去计算奖励预测的误差,通过多巴胺信号发送给大脑各个部位,以此来驱动学习行为。从那时起,多巴胺的奖励预测理论逐渐在数以万计的实验中得到证实,并已经成为神经科学领域最成功的定量理论之一。
自 TD 被应用于多巴胺奖惩机制研究以来,计算机科学家在不断优化从奖惩机制中学习的算法。自从 2013 年以来,深度强化学习开始受到关注:在强化学习中使用深度神经网络来学习更强的表示,使强化学习算法解决了精巧性和实用度等问题。
分布式强化学习是一种能让神经网络更好地进行强化学习的算法之一。在许多的情况下,尤其是很多现实情况中,未来奖励的结果实际上是依据某个特定的行为而不是一个完全已知的量进行的预测,它具有一定的随机性。
图 1 是一个示例,一个由计算机控制的小人正在越过障碍物,无法得知它是会掉落还是跨越到另一端。所以在这里,预测奖励就有两种,一种代表坠落的可能性,一种代表成功抵达另一边的可能性。
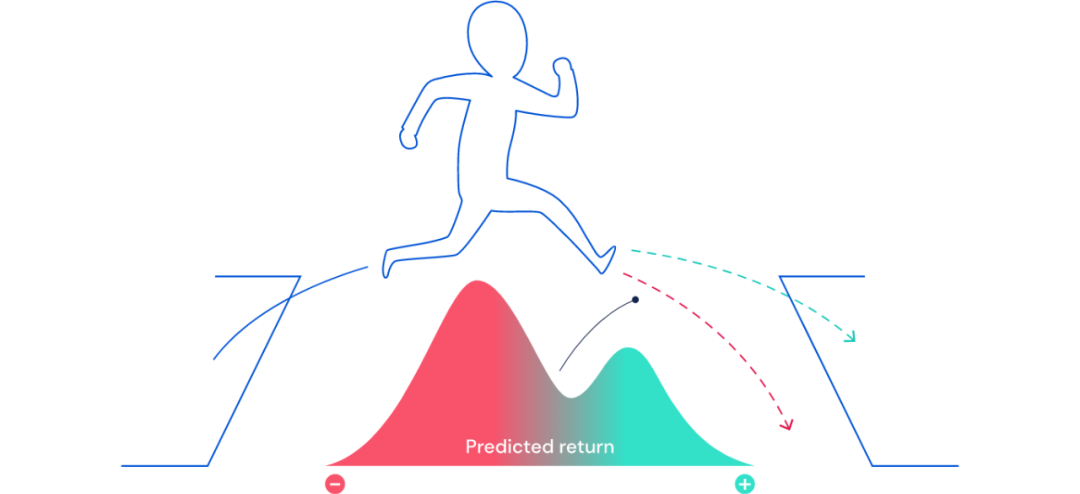
图 1:当未来不确定时,可以用概率分布的方式去描述未来奖励。未来的某一部分可能会是「好的(绿色)」,其他则代表「不好(红色)」。借助各种 TD 算法,分布式强化学习可以学习关于这个奖励预期的分布情况。
在这种情况下,标准 TD 算法学习预测将来的平均奖励,而不能获得潜在回报的双峰分布(two-peaked distribution)。但是分布式强化学习算法则能够学习预测将来的全部奖励。上图 1 描述了由分布式智能体学习到的奖励预测。
因此,分布式强化学习算法在多巴胺研究中的应用就进入了研究者们的视野。
分布式 TD:性能更好的强化学习算法
新的研究采用了一种分布式强化学习算法,与标准 TD 非常类似,被称为分布式 TD。标准 TD 学习单个预测(平均期望预测),而分布式 TD 学习一系列不同的预测。而分布式 TD 学习预测的方法与标准 TD 相同,即计算能够描述连续预测之间差异的奖励预测误差,但是每个预测器对于每个奖励预测误差都采用不同的转换。
例如,当奖励预测误差为正时(如下图 2A 所示),一些预测器会有选择性地「扩增」或「增持」奖励预测误差。这使得预测器学习更乐观的奖励预测,从而对应奖励分布中的更高部分。但同时,另一些预测器扩增它们的负奖励预测误差(如下图 2A 所示),所以学习更悲观的奖励预测。因此具有不同悲观和乐观权重的一系列预测器构成了下图 2B 和 2C 的完整奖励分布图。
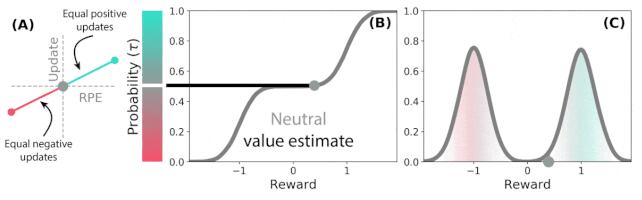
图 2:分布式 TD 学习对奖励分布不同部分的价值估计。
除了简洁性之外,分布式强化学习还有另一项优势,当它与深度神经网络结合时会非常强大。过去五年,基于原始深度强化学习 DQN 智能体的算法有了很多进展,并且这些算法经常在 Atari 2600 游戏中的 Atari-57 基准测试集上进行评估,证明了分布式强化学习算法的性能优势。
多巴胺研究中的分布式 TD
由于分布式 TD 在人工神经网络中具有很好的性能,因此本研究考虑采用分布式 TD,尝试研究大脑的奖惩机制。
在研究中,研究者联合哈佛大学,对老鼠多巴胺细胞的记录进行分析。在任务中,这些老鼠获得数量未知的奖励(如下图 4 所示)。研究者的目的是评估多巴胺神经元的活动是否与标准 TD 或分布式 TD 更为一致。
以往的研究表明,多巴胺细胞改变它们的发放率(firing rate)来表明存在的预测误差,即一个动物是否接收了比预期更多或更少的奖励。我们知道,当奖励被接收时,预测误差应为零,也就是奖励大小应与多巴胺细胞预测的一样,因此对应的发放率也不应当改变。
对于每个多巴胺细胞,如果研究者确定了其基准发放率没有改变,则其奖励大小也可以被确定。这个关系被称之为细胞的「逆转点」。研究者想要弄清楚不同细胞之间的逆转点是否也存在差异。
如下图 4C 所示,细胞之间存在着明显差异,一些细胞会预测非常大的奖励,而另一些只预测出非常小的奖励。相较于从记录中固有随机变化率所能预期的差异,细胞之间的实际差异要大得多。
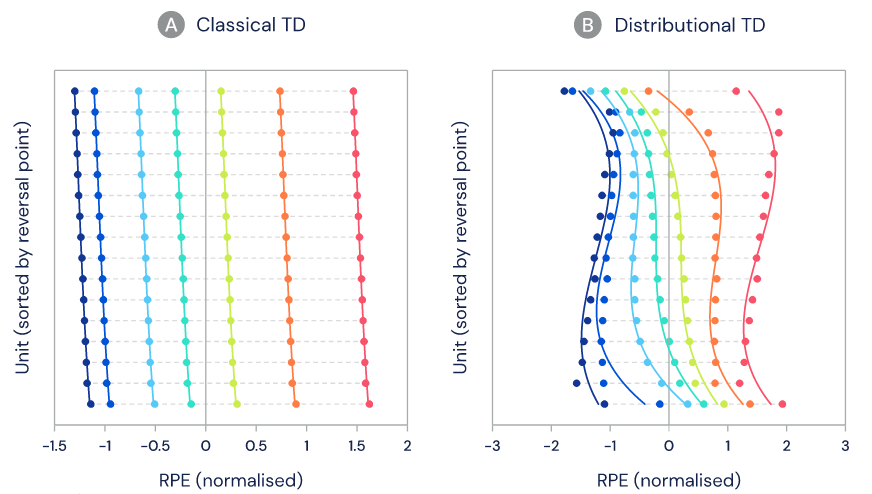
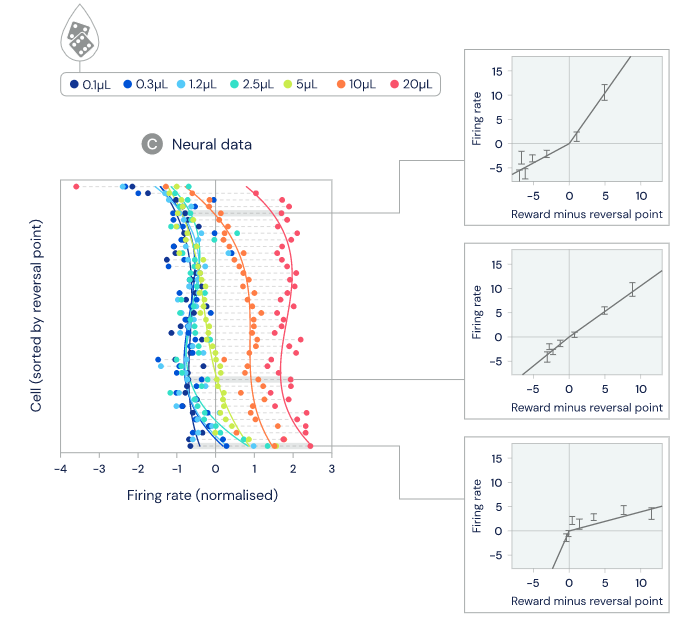
图 4:在这项任务中,老鼠获得的水奖励(water reward)通过随机方法确定,并可以调整,范围是 0.1-20 UL。
在分布式 TD 中,奖励预测中的这些差异是由正或负奖励预测误差的选择性扩增引起的。扩增正奖励预测可以获得更乐观的奖励预测,而扩增负奖励可以获得更悲观的预测。所以,研究者接下来测量了不同多巴胺细胞对正或负期望的扩增程度,并发现了细胞之间存在着噪声也不能解释的可靠多样性。并且关键的一点是,他们发现扩增正奖励预测误差的同一些细胞也表现出了更高的逆转点(上图 4C 右下图),也就是说,这些细胞期望获得更高的奖励。
最后,分布式 TD 理论预测,有着不同的逆转点(reversal point)的细胞应该共同编码学到的奖励分配。因此研究人员希望能够探究:是否可以从多巴胺细胞的发放率解码出奖励分配到不同细胞的分布。
如图 5 所示,研究人员发现,只使用多巴胺细胞的放电速率,确实有可能重建奖励的分布(蓝色线条),这与老鼠执行任务时奖励的实际分布(灰色区域)非常接近。
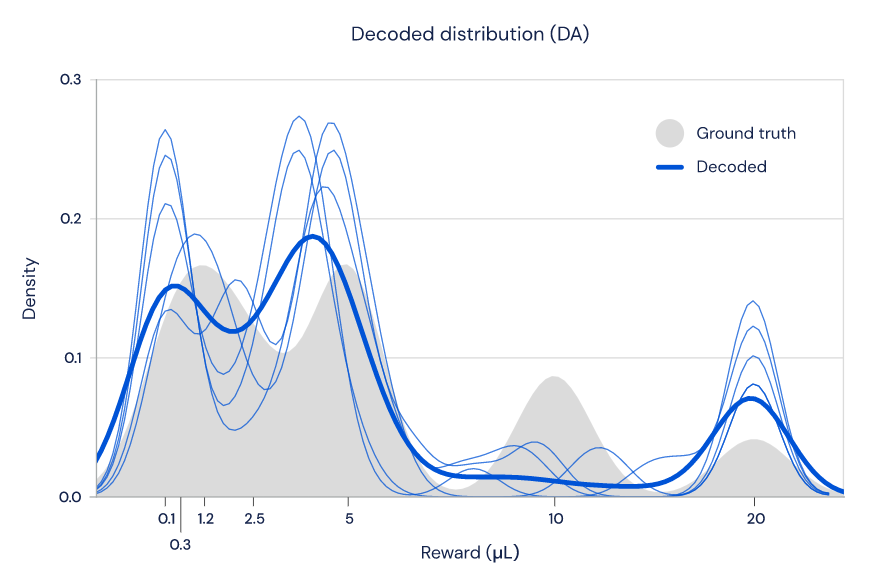
图 5:多巴胺细胞群编码了学到的奖励分布的形状。
总结
研究人员发现,大脑中的多巴胺神经元被调节到不同水平的「悲观」和「乐观」。如果它们是一个合唱团,那么所有的神经元不会唱同一个音域,而是彼此配合——每个神经元都有自己的音域,如男高音或女低音。在人工强化学习系统中,这种多样化的调整创造了更加丰富的训练信号,极大地加快了神经网络的学习。研究人员推测,大脑可能出于同样的原因使用这套机制。
大脑中分布式强化学习的存在可以为 AI 和神经科学的发展提供非常有趣的启示。首先,这一发现验证了分布式强化学习的潜力——大脑已经用到了这套算法。
其次,它为神经科学提出了新的问题。如果大脑选择性地「倾听」乐观/悲观多巴胺神经元会怎么样呢?会导致冲动或抑郁吗?大脑有强大的表征能力,这些表征是如何由分布式学习训练出的呢?例如,一旦某个动物学会了分配奖励的机制,在它的下游任务会如何使用这种表征?多巴胺细胞之间的乐观情绪可变性与大脑中其他已知的可变形式存在什么关联?这些问题都需要后续研究进一步解释。
最后,DeepMind 的研究人员希望通过这些问题的提出和解答来促进神经科学的发展,进而为人工智能研究带来益处,形成一个良性循环。