问题现象
在STGW现网运营中,出现了一起流量突然下降的Case,此时我们的健康拨测机制探测到失败,并且用户侧重试次数增多、请求延迟增大。但通过已有的各类监控进行定位,只发现整体CPU、内存、进程状态、QPS(每秒请求数)等关键指标虽然出现波动,但均未超过告警水位。
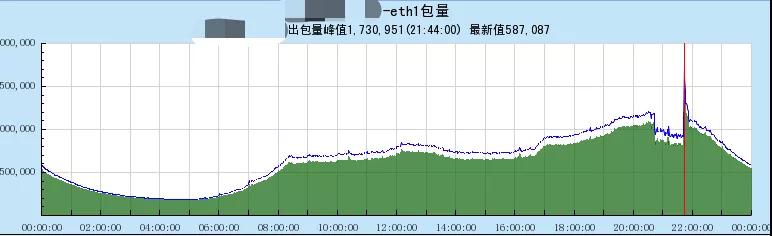
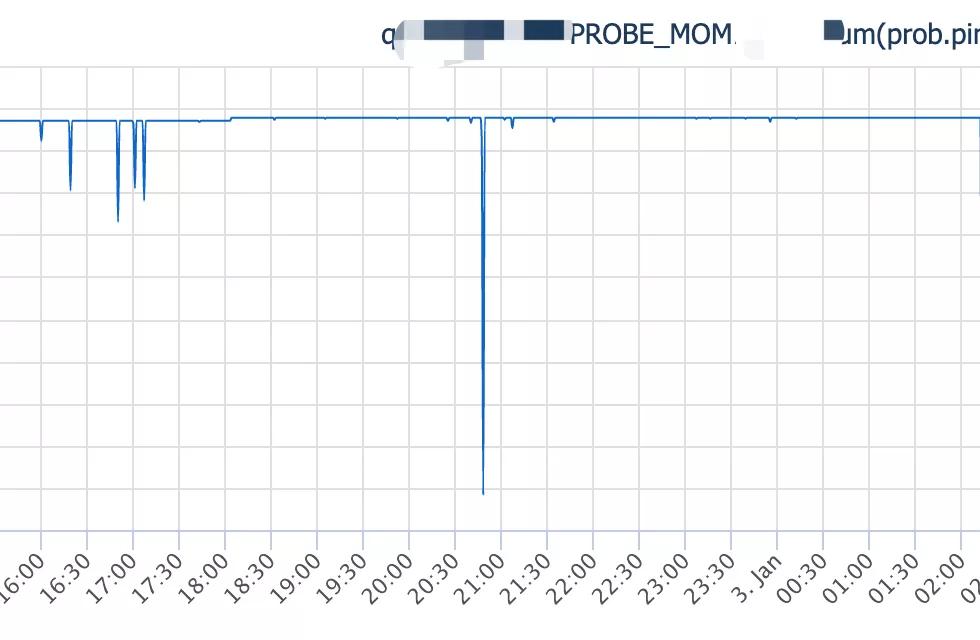
如图,流量出现了跌幅,并且出现健康检查拨测失败。
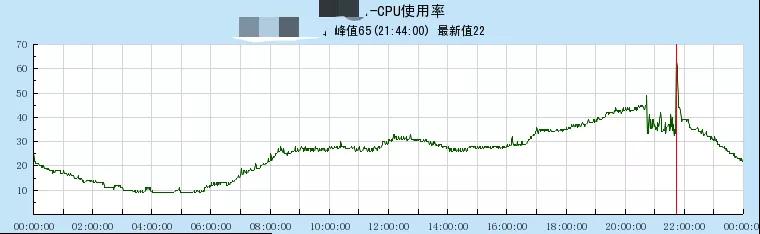
但是,整体CPU在流量出现缺口的期间,并未超过阈值,反而有一些下降,随后因为恢复正常流量冲高才出现一个小毛刺。
此外,内存和应用层监控,都没有发现明显异常。
前期探索
显然,仅凭这些常规监控,无法定位问题根本原因,尽量拿到更多的问题信息,成为了当务之急。幸运的是,从STGW自研的秒级监控系统中,我们查到了一些关键的信息。
在STGW自研的监控系统里,我们增加了核心资源细粒度监控,针对CPU、内存、内核网络协议栈这些核心指标支持秒级监控、监控指标更细化,如下图就是出问题时间段,cpu各个核心的秒级消耗情况。
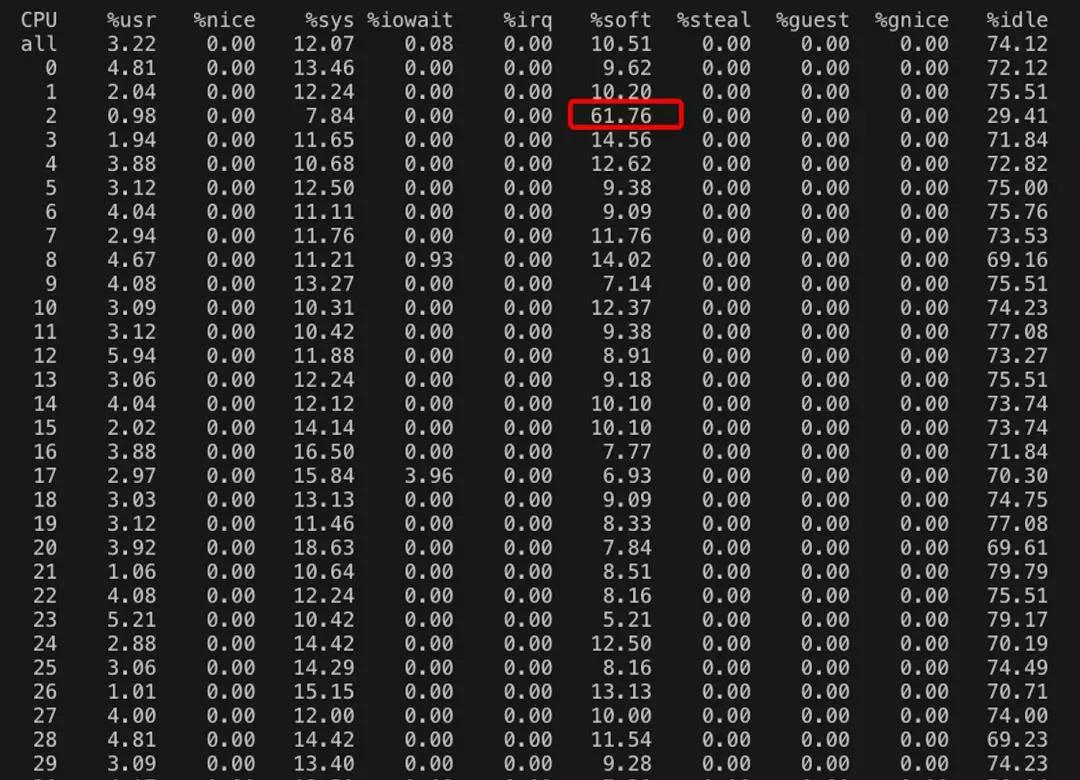
通过STGW CPU细粒度监控展示的信息,可以看到在出现问题的时间段内,部分CPU核被跑满,并且是由于软中断消耗造成,回溯整个问题时间段,我们还发现,在一段长时间内,这种软中断热点偏高都会在几个固定的核上出现,不会转移给其他核。
此外,STGW的监控模块支持在出现系统核心资源异常时,抓取当时的函数调用栈信息,有了函数调用信息,我们能更准确的知道是什么造成了系统核心资源异常,而不是继续猜想。如图展示了STGW监控抓到的函数调用及cpu占比信息:
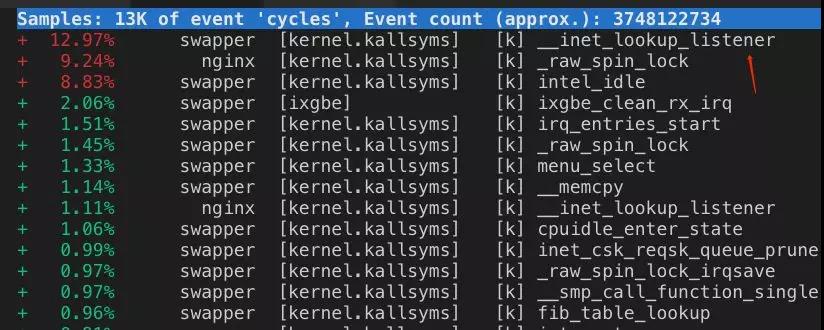
通过函数栈监控信息,我们发现了inet_lookup_listener函数是当时CPU软中断热点的主要消耗者。出现问题时,其他函数调用在没有发生多少变化情况下,inet_lookup_listener由原本很微小的cpu消耗占比,一下子冲到了TOP1。
通过这里,我们可以初步确定,inet_lookup_listener消耗过高跟软中断热点强相关,当热点将cpu单核跑满后就可能引发出流量有损的问题。由于软中断热点持续在产生,线上稳定性隐患很大。基于这个紧迫的稳定性问题,我们从为什么产生热点、为什么热点只在部分cpu core上出现两个方向,进行了问题分析、定位和解决。
为什么产生了热点
1. 探秘 inet_lookup_listener
由于perf已经给我们提供了热点所在,首先从热点函数入手进行分析,结合内核代码得知,__inet_lookup系列函数是用于将收到的数据包定位到一个具体的socket上,但只有握手包会进入到找__inet_lookup_listener的逻辑,大部分数据包是通过__inet_lookup_established寻找socket。
具体分析lookup_listener的代码我们发现,由于listen socket不具备四元组特征,因此内核只能用监听端口计算一个哈希值,并使用了 listening_hash 哈希桶存起来,握手包发过来的时候,就从该哈希桶中寻找对应的listen socket。
- struct sock *__inet_lookup_listener(struct net *net,
- struct inet_hashinfo *hashinfo,
- const __be32 saddr, __be16 sport,
- const __be32 daddr, const unsigned short hnum,
- const int dif)
- {
- // 省略了部分代码
- // 获取listen fd 哈希桶
- struct inet_listen_hashbucket *ilb = &hashinfo->listening_hash[hash];
- result = NULL;
- hiscore = 0;
- // 遍历桶中的节点
- sk_nulls_for_each_rcu(sk, node, &ilb->head) {
- score = compute_score(sk, net, hnum, daddr, dif);
- if (score > hiscore) {
- result = sk;
- hiscore = score;
- reuseport = sk->sk_reuseport;
- if (reuseport) {
- phash = inet_ehashfn(net, daddr, hnum,
- saddr, sport);
- matches = 1;
- }
- } else if (score == hiscore && reuseport) {
- matches++;
- if (((u64)phash * matches) >> 32 == 0)
- result = sk;
- phash = next_pseudo_random32(phash);
- }
- }
- }
相对来说并不复杂的lookup_listener函数为什么会造成这么大的cpu开销?经过进一步定位后,发现问题所在:listen哈希桶开的太小了,只有32个。
- /* This is for listening sockets, thus all sockets which possess wildcards. */
- #define INET_LHTABLE_SIZE 32 /* Yes, really, this is all you need. */
为什么内核这里会觉得listen哈希桶大小32就满足需要了呢?
在IETF(互联网工程任务组)关于端口的规划中,0-1023是System port,系统保留使用,1024-49151为Registered port,为IANA(互联网数字分配机构)可分配给一些固定应用,49152-65535是Dynamic port,是可以真正自由使用的。当然了,这只是IETF的一个规划,在Linux中,除了System port,另两个端口段并未真的做了明显区分,除非端口已经被占用,用户可以自由使用,这里提一个Linux中跟端口划分有关联的内核参数:ip_local_port_range,它表示系统在建立TCP/UDP连接时,系统给它们分配的端口范围,默认的ip_local_port_range值是32768-60999,进行这个设置后好处是,61000~65535端口是可以更安全的用来做为服务器监听,而不用担心一些TCP连接将其占用。
因此,在正常的情况下,服务器的listen port数量,大概就是几w个这样的量级。这种量级下,一个port对应一个socket,哈希桶大小为32是可以接受的。然而在内核支持了reuseport并且被广泛使用后,情况就不一样了,在多进程架构里,listen port对应的socket数量,是会被几十倍的放大的。以应用层监听了5000个端口,reuseport 使用了50个cpu核心为例,5000*50/32约等于7812,意味着每次握手包到来时,光是查找listen socket,就需要遍历7800多次。随着机器硬件性能越来越强,应用层使用的cpu数量增多,这个问题还会继续加剧。
正因为上述原因,并且我们现网机器开启了reuseport,在端口数量较多的机器里,inet_lookup_listener的哈希桶大小太小,遍历过程消耗了cpu,导致出现了函数热点。
2. 如何解决__inet_lookup_listener问题
Linux社区难道没有注意到开启reuseport后,原来的哈希桶大小不够用这个问题吗?
其实社区是注意到了这个问题的,并且有修复这个问题。
从Linux 4.17开始,Linux社区就修复了由于reuseport带来的socket数量过多,导致inet_lookup_listener查找缓慢的问题,修复方案分两步:
1. 引入了两次查找,首先还是根据目的端口进行哈希,接着会使用握手包中拿到的四元组信息,按照四元组进行第一次查找,如果四元组获取不到结果,则使用之前那种对于任意IP地址查找。
- struct sock *__inet_lookup_listener(struct net *net,
- struct inet_hashinfo *hashinfo,
- struct sk_buff *skb, int doff,
- const __be32 saddr, __be16 sport,
- const __be32 daddr, const unsigned short hnum,
- const int dif, const int sdif)
- {
- struct inet_listen_hashbucket *ilb2;
- struct sock *result = NULL;
- unsigned int hash2;
- // 根据目的端口进行第一次哈希
- hash2 = ipv4_portaddr_hash(net, daddr, hnum);
- ilb2 = inet_lhash2_bucket(hashinfo, hash2);
- // 根据四元组信息再做一次查找
- result = inet_lhash2_lookup(net, ilb2, skb, doff,
- saddr, sport, daddr, hnum,
- dif, sdif);
- if (result)
- goto done;
- /* Lookup lhash2 with INADDR_ANY */
- // 四元组没查到,尝试在0.0.0.0监听范围查找
- hash2 = ipv4_portaddr_hash(net, htonl(INADDR_ANY), hnum);
- ilb2 = inet_lhash2_bucket(hashinfo, hash2);
- result = inet_lhash2_lookup(net, ilb2, skb, doff,
- saddr, sport, htonl(INADDR_ANY), hnum,
- dif, sdif);
- done:
- if (IS_ERR(result))
- return NULL;
- return result;
- }
2. 合并处理reuseport放大出来的socket,在发现指定的端口开启了reuseport后,不再是遍历式的去获取到合适的socket,而是将其看成一个整体,二次哈希后,调用 reuseport_select_sock,取到合适的socket。
- static struct sock *inet_lhash2_lookup(struct net *net,
- struct inet_listen_hashbucket *ilb2,
- struct sk_buff *skb, int doff,
- const __be32 saddr, __be16 sport,
- const __be32 daddr, const unsigned short hnum,
- const int dif, const int sdif)
- {
- bool exact_dif = inet_exact_dif_match(net, skb);
- struct inet_connection_sock *icsk;
- struct sock *sk, *result = NULL;
- int score, hiscore = 0;
- u32 phash = 0;
- inet_lhash2_for_each_icsk_rcu(icsk, &ilb2->head) {
- sk = (struct sock *)icsk;
- score = compute_score(sk, net, hnum, daddr,
- dif, sdif, exact_dif);
- if (score > hiscore) {
- if (sk->sk_reuseport) {
- // 如果是reuseport,进行二次哈希查找
- phash = inet_ehashfn(net, daddr, hnum,
- saddr, sport);
- result = reuseport_select_sock(sk, phash,
- skb, doff);
- if (result)
- return result;
- }
- result = sk;
- hiscore = score;
- }
- }
- return result;
- }
总结来说,社区通过引入两次查找+合并reuseport sockets的处理,解决了reuseport带来的sockets数量放大效果。这里结合我们的探索,另外提供两个可行的低成本解决方案:
1. 修改内核哈希桶大小,根据reuseport增加socket的倍数,相应提高INET_LHTABLE_SIZE,或者直接改成例如2048
- #define INET_LHTABLE_SIZE 2048
2. 关闭reuseport可以减少socket数目到32个哈希桶大小能承受的范围,从而降低该函数消耗。
加上社区方案,这里的三个方法在本质上都是减少listen table哈希桶的遍历复杂度。社区的方案一套比较系统的方法,今后随着内核版本升级,肯定会将这个问题解决掉。但短期升级内核的成本较高,所以后面两个方案就可以用来短期解决问题。此外,关闭reuseport虽然不需要更改内核,但需要考虑应用层server对于reuseport的依赖情况。
为什么热点只在部分核心出现
解决完哈希桶问题后,我们并没有定位到全部的问题,前面提到,软中断热点仅在部分cpu核上出现,如果仅仅是__inet_lookup_listener问题,按理所有cpu核的软中断消耗都会偏高。如果这里问题没有解释清楚,一旦出现热点函数,一些单核就会被跑满,意味着整机容量强依赖部分单核的性能瓶颈,超出了单核能力就会有损,这是完全不能接受的。
1. 从CPU中断数入手
根据问题现象,我们做了一些假设,在这里最直观的假设就是,我们的数据包在各个核上并不是负载均衡的。
首先,通过cat /proc/interrupts找到网卡在各个cpu核的中断数,发现网卡在各个核的硬中断就已经不均衡了。那么会是硬中断亲和性的问题吗?接着检查了网卡各个队列的smp_affiinity,发现每个队列与cpu核都是一一对应并且互相错开,硬中断亲和性设置没有问题。
紧接着,我们排查了网卡,我们的网卡默认都打开了RSS(网卡多队列),每个队列绑定到一个核心上,既然硬中断亲和性没有问题,那么会是网卡多队列本身就不均衡吗?通过ethtool -S eth0/eth1再过滤出每个rx_queue的收包数,我们得到如下图:
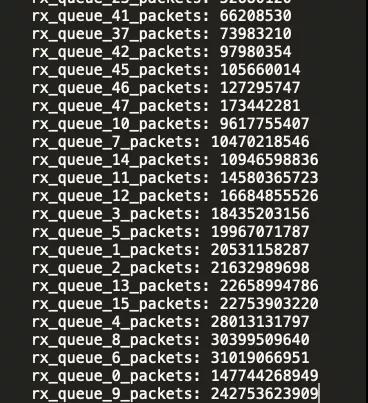
原来网卡多队列收包就已经严重不均衡了,以入包量升序排序,发现不同的rx_queue 收包数量相差达到了上万倍!
2. 探究网卡多队列(RSS)
这里我们着重检查了几个网卡多队列的参数
- // 检查网卡的队列数
- ethtool -l eth0
- Current hardware settings:
- RX: 0
- TX: 0
- Other: 1
- Combined: 48
- // 检查硬件哈希开关
- ethtool -k eth0
- receive-hashing: on
- // 检查硬件哈希的参数,这里显示以TCP是以四元组信息进行哈希
- ethtool -n eth0 rx-flow-hash tcp4
- TCP over IPV4 flows use these fields for computing Hash flow key:
- IP SA
- IP DA
- L4 bytes 0 & 1 [TCP/UDP src port]
- L4 bytes 2 & 3 [TCP/UDP dst port]
这些参数都是符合预期的,数据包会根据TCP包的四元组哈希到不同的队列上。我们继续使用假设论证法,会是数据包本身就是比如长连接,导致不均衡吗?通过检查我们服务端的日志,发现请求的ip和端口都是比较分散的,传输的数据也都是较小文件,并没有集中化。
经过了一番折腾,我们有了新的假设,由于我们现网大部分流量是IPIP隧道及GRE封装的数据包,在普通数据包的IP header上多了一层header,外层IP与我们在server看到的并不一样,外层IP是非常集中的。这里是否会让网卡多队列的均衡策略失效呢?
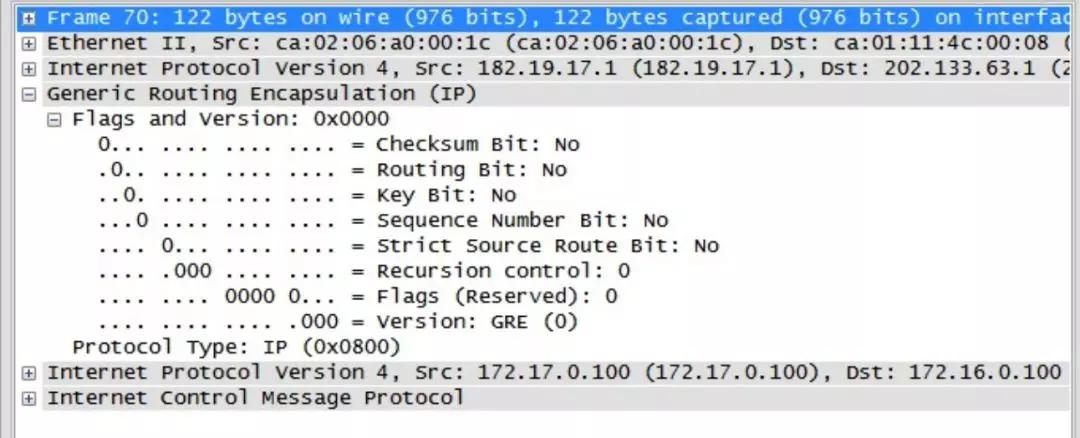
来源网图,以GRE包为例,IP数据包其实是分了外层IP头部、gre层、内层IP头部,以及再往上的TCP/UDP层,如果只获取了外层IP头部,则较为集中,难以进行分散。
经过同事帮忙牵线,我们从网卡厂商处获得了重要的信息,不同的网卡对于多队列哈希算法是不一样的!
从网卡厂商处进一步确认得知,我们在使用的这款网卡,是不支持解析封装后的数据包的,只会以外层IP作为哈希依据。厂商提供了一款新型号的网卡,是支持解析IPIP及GRE内层IP PORT的。我们经过实测这两种网卡,发现确实如此。
看到这里,网卡多队列不均衡问题原因已经定位清楚,由于现网使用了IPIP或GRE这类封装协议,部分网卡不支持解析内层IP PORT进行哈希,从而导致多队列不均衡,进一步导致cpu硬中断不均衡,然后不均衡的软中断热点便出现了。
3. 如何解决网卡多队列不均衡
对于STGW来说,我们已经确定了不均衡的网卡型号,都是型号较老的网卡,我们正在逐步使用新的网卡型号,新网卡型号已验证支持IPIP及GRE格式的数据包负载均衡。
为什么RPS没有起作用
Receive Packet Steering (RPS),是内核的一种负载均衡机制,即便硬件层面收到的数据包不均衡的,RPS会对数据包再次进行哈希与分流,保证其进入网络协议栈是均衡的。
经过确认,出问题机器上都开启了RPS。所以问题还是没有解释清楚,即便旧型号的网卡RSS不均衡,但经过内核RPS后,数据包才会送给网络协议栈,然后调用_inet_lookup_listener,此时依然出现热点不均衡,说明RPS并未生效。
1. 了解硬件及内核收包流程
由于引入了RPS这个概念,在定位该问题前,我梳理了一份简明收包流程,通过了解数据包是如何通过硬件、内核、再到内核网络协议栈,可以更清晰的了解RPS所处的位置,以及我们遇到的问题。
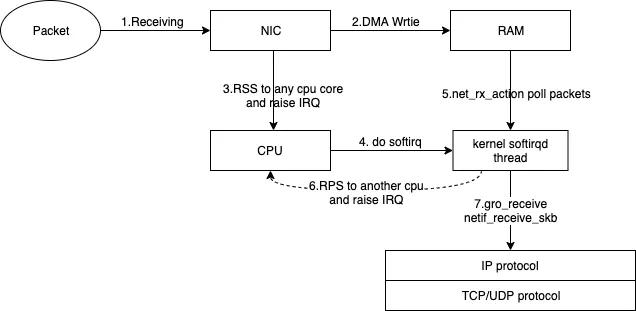
如上图所示,数据包在进入内核IP/TCP协议栈之前,经历了这些步骤:
- 网口(NIC)收到packets
- 网口通过DMA(Direct memeory access)将数据写入到内存(RAM)中。
- 网口通过RSS(网卡多队列)将收到的数据包分发给某个rx队列,并触发该队列所绑定核上的CPU中断。
- 收到中断的核,调用该核所在的内核软中断线程(softirqd)进行后续处理。
- softirqd负责将数据包从RAM中取到内核中。
- 如果开启了RPS,RPS会选择一个目标cpu核来处理该包,如果目标核非当前正在运行的核,则会触发目标核的IPI(处理器之间中断),并将数据包放在目标核的backlog队列中。
- 软中断线程将数据包(数据包可能来源于第5步、或第6步),通过gro(generic receive offload,如果开启的话)等处理后,送往IP协议栈,及之后的TCP/UDP等协议栈。
回顾我们前面定位的问题,__inet_lookup_listener热点对应的是IP协议栈的问题,网卡多队列不均衡是步骤3,RSS阶段出现的问题。RPS则是在步骤6中。
2. 探秘RPS负载不均衡问题
通过cat /proc/net/softnet_stat,可以获取到每个核接收的RPS次数。拿到这个数目后,我们发现,不同的核在接收RPS次数上相差达到上百倍,并且RPS次数最多的核,正好就是软中断消耗出现热点的核。
至此我们发现,虽然网卡RSS存在不均衡,但RPS却依然将过多的数据包给了部分cpu core,没有做到负载均衡,这才是导致我们软中断热点不均衡的直接原因。
通过在内核代码库中找到RPS相关代码并进行分析,我们再次发现了一些可疑的点
- static int get_rps_cpu(struct net_device *dev, struct sk_buff *skb,
- struct rps_dev_flow **rflowp)
- {
- // 省略部分代码
- struct netdev_rx_queue *rxqueue;
- struct rps_map *map;
- struct rps_dev_flow_table *flow_table;
- struct rps_sock_flow_table *sock_flow_table;
- int cpu = -1;
- u16 tcpu;
- skb_reset_network_header(skb);
- if (rps_ignore_l4_rxhash) {
- // 计算哈希值
- __skb_get_rxhash(skb);
- if (!skb->rxhash)
- goto done;
- }
- else if(!skb_get_rxhash(skb))
- goto done;
- // 通过哈希值计算出目标CPU
- if (map) {
- tcpu = map->cpus[((u64) skb->rxhash * map->len) >> 32];
- if (cpu_online(tcpu)) {
- cpu = tcpu;
- goto done;
- }
- }
- done:
- return cpu;
- }
- /*
- * __skb_get_rxhash: calculate a flow hash based on src/dst addresses
- * and src/dst port numbers. Sets rxhash in skb to non-zero hash value
- * on success, zero indicates no valid hash. Also, sets l4_rxhash in skb
- * if hash is a canonical 4-tuple hash over transport ports.
- */
- void __skb_get_rxhash(struct sk_buff *skb)
- {
- struct flow_keys keys;
- u32 hash;
- if (!skb_flow_dissect(skb, &keys))
- return;
- if (keys.ports)
- skb->l4_rxhash = 1;
- // 使用TCP/UDP四元组进行计算
- /* get a consistent hash (same value on both flow directions) */
- if (((__force u32)keys.dst < (__force u32)keys.src) ||
- (((__force u32)keys.dst == (__force u32)keys.src) &&
- ((__force u16)keys.port16[1] < (__force u16)keys.port16[0]))) {
- swap(keys.dst, keys.src);
- swap(keys.port16[0], keys.port16[1]);
- }
- // 使用jenkins哈希算法
- hash = jhash_3words((__force u32)keys.dst,
- (__force u32)keys.src,
- (__force u32)keys.ports, hashrnd);
- if (!hash)
- hash = 1;
- skb->rxhash = hash;
- }
猜想一:rps_ignore_l4_rxhash未打开,导致不均衡?
通过代码发现 rps_ignore_l4_rxhash 会影响当前是否计算哈希值,当前机器未设置ignore_l4_rxhash,则内核会直接使用网卡RSS计算出的哈希值,根据上面定位的网卡RSS不均衡的结论,RSS哈希值可能是不准的,这里会导致问题吗?
我们将ignore_l4_rxhash开关进行打开
- sysctl -w kernel.rps_ignore_l4_rxhash=1
发现并没有对不均衡问题产生任何改善,排除这个假设。
猜想二:RPS所使用的哈希算法有缺陷,导致不均衡?
对于负载不均衡类的问题,理所应当会怀疑当前使用的均衡算法存在缺陷,RPS这里使用的是jenkins hash(jhash_3words)算法,是一个比较著名且被广泛使用的算法,经过了很多环境的验证,出现缺陷的可能性较小。但我们还是想办法进行了一些验证,由于是内核代码,并且没有提供替代性的算法,改动内核的代价相对较高。
因此这里我们采取的对比的手段快速确定,在同样的内核版本,在现网找到了负载均衡的机器,检查两边的一些内核开关和RPS配置都是一致的,说明同样的RPS哈希算法,只是部分机器不均衡,因此这里算法侧先不做进一步挖掘。
猜想三:和RSS问题一样,RPS也不支持对封装后的数据进行四元组哈希?
skb_flow_dissect是负责解析出TCP/UDP四元组,经过初步分析,内核是支持IPIP、GRE等通用的封装协议,并从这些协议数据包中,取出需要的四元组信息进行哈希。
在各种假设与折腾都没有找到新的突破之时,我们使用systemtap这个内核调试神器,hook了关键的几个函数和信息,经过论证和测试后,在现网进行了短暂的debug,收集到了所需要的关键信息。
- #! /usr/bin/env stap
- /*
- Analyse problem that softirq not balance with RPS.
- Author: dalektan@tencent.com
- Usage:
- stap -p4 analyse_rps.stp -m stap_analyse_rps
- staprun -x cpuid stap_analyse_rps.ko
- */
- // To record how cpu changed with rps execute
- private global target_cpu = 0
- private global begin_cpu
- private global end_cpu
- probe begin {
- target_cpu = target()
- begin_cpu = target_cpu - 2
- end_cpu = target_cpu + 2
- // 指定需要分析的cpu范围,避免对性能产生影响
- printf("Prepare to analyse cpu is :%d-%d\n", begin_cpu, end_cpu)
- }
- // To record tsv ip addr, daddr and protocol(ipip, gre or tcp)
- probe kernel.function("ip_rcv").call {
- if (cpu() >= begin_cpu && cpu() <= end_cpu) {
- ip_protocol = ipmib_get_proto($skb)
- // if not tcp, ipip, gre, then return
- if (ip_protocol == 4 || ip_protocol == 6 || ip_protocol == 47) {
- saddr = ip_ntop(htonl(ipmib_remote_addr($skb, 0)))
- daddr = ip_ntop(htonl(ipmib_local_addr($skb, 0)))
- printf("IP %s -> %s proto:%d rx_queue:%d cpu:%d\n",
- saddr, daddr, ip_protocol, $skb->queue_mapping-1, cpu())
- }
- }
- }
- // To record tcp states
- probe tcp.receive.call {
- if (cpu() >= begin_cpu && cpu() <= end_cpu) {
- printf("TCP %s:%d -> %s:%d syn:%d rst:%d fin:%d cpu:%d\n",
- saddr, sport , daddr, dport, syn, rst, fin, cpu())
- }
- }
通过使用上述systemtap脚本进行分析后,我们得到了一个关键信息,大量GRE协议(图中proto:47)的数据包,无论其四元组是什么,都被集中调度到了单个核心上,并且这个核心正好是软中断消耗热点核。并且其他协议数据包未出现这个问题。
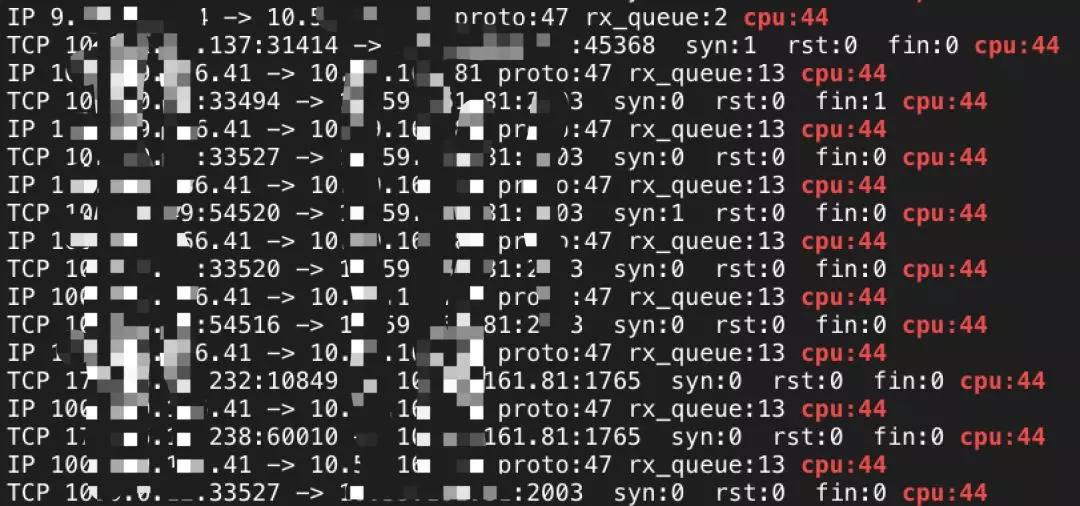
走到这里,问题渐为开朗,GRE数据包未按预期均衡到各个核心,但根据之前的分析,RPS是支持GRE协议获取四元组的,为什么在这里,不同的四元组,依然被哈希算成了同一个目标核呢?
3. 探究GRE数据包不均衡之谜
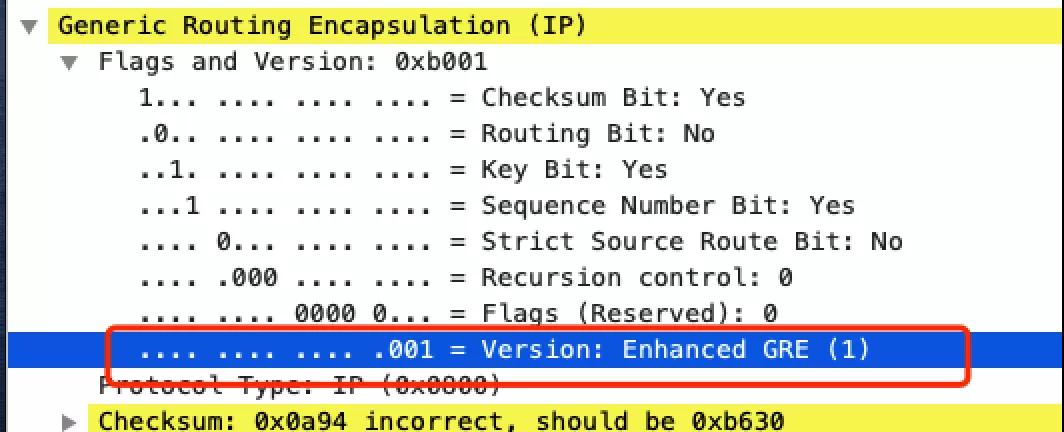
带着这个问题进一步挖掘,通过抓包以及代码比对分析,很快有了突破,定位到了原因是:当前内核仅识别GRE_VERSION=0的GRE协议包并获取其四元组信息,而我们的数据包,是GRE_VERSION=1的。
- // skb_flow_dissect 获取四元组信息
- switch (ip_proto) {
- case IPPROTO_GRE: {
- struct gre_hdr {
- __be16 flags;
- __be16 proto;
- } *hdr, _hdr;
- hdr = skb_header_pointer(skb, nhoff, sizeof(_hdr), &_hdr);
- if (!hdr)
- return false;
- /*
- * Only look inside GRE if version zero and no
- * routing
- */
- // 只解析GRE_VERSION = 0的GRE协议数据包
- if (!(hdr->flags & (GRE_VERSION|GRE_ROUTING))) {
- proto = hdr->proto;
- nhoff += 4;
- if (hdr->flags & GRE_CSUM)
- nhoff += 4;
- if (hdr->flags & GRE_KEY)
- nhoff += 4;
- if (hdr->flags & GRE_SEQ)
- nhoff += 4;
- if (proto == htons(ETH_P_TEB)) {
- const struct ethhdr *eth;
- struct ethhdr _eth;
- eth = skb_header_pointer(skb, nhoff,
- sizeof(_eth), &_eth);
- if (!eth)
- return false;
- proto = eth->h_proto;
- nhoff += sizeof(*eth);
- }
- goto again;
- }
- break;
- }
首先,我们先确认一下,GRE_VERSION=1是符合规范的吗,答案是符合的,如果去了解一下PPTP协议的话,可以知道RFC规定了PPTP协议就是使用的GRE协议封装并且GRE_VERSION=1。
那么为什么内核这里不支持这种标记呢?
通过在Linux社区进行检索,我们发现Linux 4.10版本开始支持PPTP协议下的GRE包识别与四元组获取,也就是GRE_VERSION=1的情况。由于没有加入对PPTP协议的支持,因此出现不识别GRE_VERSION=1(PPTP协议)的情况,RPS不会去获取这种数据包的四元组信息,哈希后也是不均衡的,最终导致单核出现软中断热点。
4. 如何解决RPS不均衡问题
至此,所有的问题都已经拨开云雾,最后对于RPS不均衡问题,这里提供三种解决方案:
- 对于RSS网卡多队列已经是均衡的机器,可以将修改kernel.rps_ignore_l4_rxhash = 0,让RPS直接使用网卡硬件哈希值,由于硬件哈希值足够分散,因此RPS效果也是均衡的。
- 对于RSS网卡多队列均衡的机器,通过ethtool -S/-L查看或修改网卡多队列数目,如果队列数不少于cpu核数,再将多队列通过/proc/irq/设备id/smp_affinity分散绑定到不同的cpu核。这样可以充分利用网卡RSS的均衡效果,而无需打开内核RPS。
- 在当前内核进行修改或热补丁,在RPS函数中新增对GRE_VERSION=1的GRE数据包的识别与四元组获取。
- 升级内核到Linux 4.10之后,即可支持PPTP协议包的RPS负载均衡。
总结
最后,总结一下整个问题和定位过程,我们从一次流量下降,业务有损的问题出发,从最开始找不到思路,到找到软中断热点这个关键点,再到区分IP协议栈、网卡多队列、内核收包这三个层面进行问题入手,没有满足于已经解决的部分问题,不断深挖了下去,终于各个方向击破,拨开了问题的层层面纱,并给出了解决方案。
借着对问题的定位和解决,收获良多,学习了内核收包流程,熟悉了内核问题定位工具和手段。感谢STGW组里同事,文中诸多成果都是团队的共同努力。
【本文为51CTO专栏作者“腾讯技术工程”原创稿件,转载请联系原作者(微信号:Tencent_TEG)】