【51CTO.com原创稿件】大家都知道古代皇帝各个都是后宫佳丽三千,而皇帝身上都天然的带着雨露均沾的精神,不想单独的宠爱一人!
图片来自 Pexels
弱水三千,又怎舍得只取一瓢饮?据传皇帝们晚上睡觉个个都怕冷,因此每晚都需要有人侍寝,那么这么多后宫,该翻谁牌子、怎么分配侍寝名额呢?
还别说,皇帝行房事竟还挺讲究的!早在《春秋》就有记载“晦阴惑疾,明谣心疾,以辟六气”。
九嫔以下,每九人中进御一人,八十一女御占九个晚上,世妇二十七人占三个晚上,九嫔占一个晚上,三夫人占一个晚上,以上共十四夜,皇后独占一个晚上,共十五夜。上半个月按上述安排进御,下半个月从十六日开始,由皇后起,再御九嫔、世妇、女御,与月亮由盛而衰相对应......
不同朝代的皇帝也有不同宠幸妃子的方法,著名的有羊车望幸、掷筛侍寝、蝶幸、翻牌悬灯等等。
不过在我看来,如果皇帝懂负载均衡算法的话,大可不必这么折腾,一套算法便可搞定终身侍寝大事!因此我们今天来介绍几种常用的负载均衡算法及代码实现!
先看下文章的大纲:
- 轮询算法
- 加权轮询算法
- 随机算法
- 加权随机算法
- 源地址 hash 算法
- 一致性 hash 算法
轮询算法
据史料记载,乾隆一生妃嫔就有 42 人,还不算大明湖畔的夏雨荷等在下江南时候留下的情。
假设在某个时期内,皇阿玛最宠幸的有令妃、娴妃、高贵妃、纯妃四位。那普通的轮询算法怎么去选择呢?
我们先定义一个妃子集合如下:
- /**
- * *所有妃子集合
- */
- public static final List<String> PRINCESS_LIST = Arrays.asList("令妃", "娴妃", "高贵妃", "纯妃");
然后从列表中轮询侍寝的妃子,用一个变量 index 去记录轮询的位置。
- // 记录循环的位置
- private static Integer index = 0;
- public static void main(String[] args) {
- for (int i = 0; i < 10; i++) {
- System.out.println(getPrincess());
- }
- }
- private static String getPrincess() {
- // 超过数组大小需要归零(每次获取前判断,防止配置变化导致索引越界)
- if (index >= PrincessConfig.PRINCESS_LIST.size()) {
- index = 0;
- }
- String princess = PrincessConfig.PRINCESS_LIST.get(index);
- index++;
- return princess;
- }
输出结果就不贴出来了。该算法的特点就是简单、简单、简单!但是也存在很大缺点!
如果皇帝更宠爱令妃,想让她侍寝的概率更高呢?那就需要用到下面的加权轮询算法!
加权轮询算法
加权轮询就是可以主观的给每个妃子设置一个喜好值(权重值),以控制被选中的概率,因此我们需要定义如下的配置:
- /**
- * *所有妃子集合
- */
- public static final Map<String, Integer> PRINCESS_MAP = new LinkedHashMap<String, Integer>() {
- {
- put("令妃", 5);
- put("娴妃", 1);
- put("高贵妃", 3);
- put("纯妃", 2);
- }
- };
这里的配置就不再是简单的一个集合,每个妃子都对应了一个权重值,那轮询的时候怎么根据这个值去提高被选中的概率呢?
下面我们来讲三种比较常见的实现。
加权轮询实现一
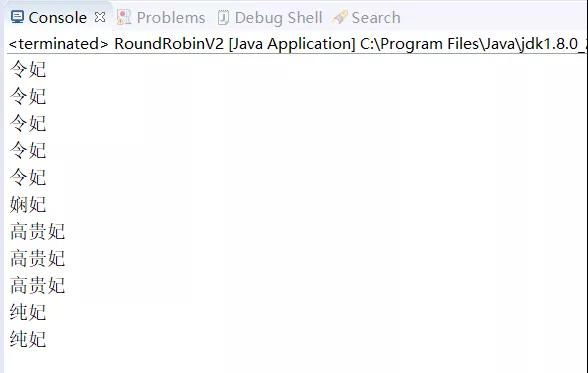
我们的思路是把这个 map 的 key(妃子)根据权重值转存到一个 list 中,然后再去轮询这个 list,如果权重值为 5,那就在 list 中添加 5 条相同的记录!
然后我们去遍历这个 list,这样权重值越高,在 list 中出现的概率就越高,被轮询中的概率也就越高!
- // 记录循环的位置
- private static Integer index = 0;
- public static void main(String[] args) {
- for (int i = 0; i < 11; i++) {
- System.out.println(getPrincess1());
- }
- }
- private static String getPrincess1() {
- // 遍历map放入到list中
- List<String> princessList = new ArrayList<String>();
- for (String princess : PrincessConfig.PRINCESS_MAP.keySet()) {
- int weight = PrincessConfig.PRINCESS_MAP.get(princess);
- // 根据权重值重复放入到一个list中
- for (int i = 0; i < weight; i++) {
- princessList.add(princess);
- }
- }
- if (index >= princessList.size()) {
- index = 0;
- }
- String princess = princessList.get(index);
- index++;
- return princess;
- }
输出结果如下:
该加权轮询算法比较简单,比较容易实现。但是也有个问题,我们配置的权重值是 5、1、3、2,那我们是不是也可以配置成 50、10、30、20 呢?
那按照上面的方式,我们是不是就需要把同样的元素往 list 里面放几百个呢?这显然是比较不合理且耗内存的!
加权轮询实现二
基于上面的算法存在的问题,我们考虑用类似占比的方式来处理。
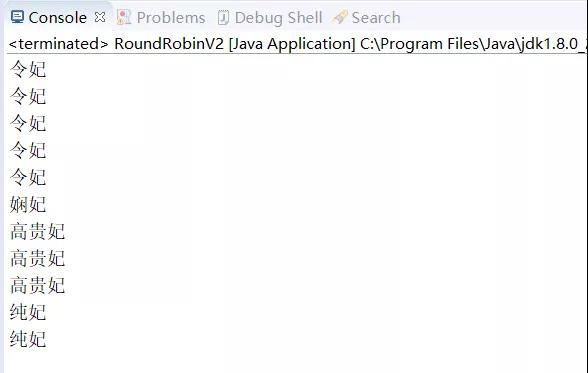
比如我们配置的权重值为 50、10、30、20,那在横坐标上表示就是 0_____50_60__80__110。
我们还是用一个 index 去记录轮询的位置,如果 index 在 0~50 之间就代表第一个妃子被选中,如果在 50~60 之间就代表第二个妃子被选中......
我们看具体代码实现:
- // 记录循环的位置
- private static Integer indexInteger = 0;
- public static void main(String[] args) {
- for (int i = 0; i < 11; i++) {
- System.out.println(getPrincess2());
- }
- }
- private static String getPrincess2() {
- //记录总权重值
- int totalWeight = 0;
- for (String princess : PrincessConfig.PRINCESS_MAP.keySet()) {
- int weight = PrincessConfig.PRINCESS_MAP.get(princess);
- totalWeight += weight;
- }
- // 归零
- if (indexInteger >= totalWeight) {
- indexInteger = 0;
- }
- int index = indexInteger;
- String result = null;
- for (String princess : PrincessConfig.PRINCESS_MAP.keySet()) {
- int weight = PrincessConfig.PRINCESS_MAP.get(princess);
- // 落在当前区间 直接返回
- if (index < weight) {
- result = princess;
- break;
- }
- // 没有落在当前区间 继续循环
- index = index - weight;
- }
- indexInteger++;
- return result;
- }
输出结果与上面的方法一毛一样:
该加权轮询算法略复杂于第一种,但是这两种实现都存在的共同问题是,按照我们目前的配置去轮询会连续 5 次令妃、再 1 次娴妃、再 3 次高贵妃......
连续 5 次!就算皇阿玛再喜欢令妃,怕是令妃也有点吃不消!用计算机术语说也就是负载不是很均衡!
加权轮询实现三(平滑加权轮询)
平滑加权轮询算法就是为了解决上面负载不均衡的情况的,该算法实现起来相对比较复杂!
每个妃子不仅有一个权重值(weight),还有一个会变化的动态权重值(dynamicWeight)来辅助计算。
动态权重值计算逻辑如下:
- 动态权重值 dynamicWeight 初始为 0。
- 每次获取轮询获取目标妃子时先设置 dynamicWeight=dynamicWeight+weight。
- 然后找到所有妃子中动态权重值 dynamicWeight 最大的一个,则为本次轮询到的目标。
- 将本次轮询到的目标的 dynamicWeight 设置为 dynamicWeight-totalWeight(总权重值)。
这样看可能会有点不是很明白,我们来做个推算,假设我们还是有如下配置(配置中只有妃子名称及对应的权重值):
- /**
- * *所有妃子集合
- */
- public static final Map<String, Integer> PRINCESS_MAP = new LinkedHashMap<String, Integer>() {
- {
- put("令妃", 5);
- put("娴妃", 1);
- put("高贵妃", 3);
- put("纯妃", 2);
- }
- };
在上面的配置中总权重值 totalWeight=5+1+3+2 等于 11。
①按照上面算法的第一点,在第一次轮询目标之前她们的 dynamicWeight 都是0。
因此四位妃子的 weight 和 dynamicWeight 值如下:

②按照上面算法的第二点,在第一次轮询选中目标的时候 dynamicWeight=dynamicWeight+weight。
变化后四位妃子的 weight 和 dynamicWeight 值如下:

③按照上面算法的第三点,然后找最大的 dynamicWeight,也就是 5,因此第一次轮询选中的就是令妃。
④按照上面算法的第四点,令妃的 dynamicWeight 需要减去 totalWeight。
变化后四位妃子的 weight 和 dynamicWeight 值如下:

然后第二次轮询的时候又需要按照算法的第一点设置 dynamicWeight。
设置后四位妃子的 weight 和 dynamicWeight 值如下:

就这样一直按照算法处理下去,轮询完 11 次后,所有妃子的 dynamicWeight 又会全部变为 0......
如果大家依然还是有点模糊,我们只能上代码为敬了!我们需要先定义一个实体,来存放每个妃子及对应的 weight 及 dynamicWeight 属性:
- /**
- * *权重实体
- *
- * @author sullivan
- *
- */
- public class PrincessWeight {
- private String princess;
- private Integer weight;
- private Integer dynamicWeight;
- public PrincessWeight(String princess, Integer weight, Integer dynamicWeight) {
- super();
- this.princess = princess;
- this.weight = weight;
- this.dynamicWeight = dynamicWeight;
- }
- }
然后定义两个全局的对象存放对象:
- // 每个妃子及对应的权重实体
- private static Map<String, PrincessWeight> weightMap = new HashMap<String, PrincessWeight>();
- // 总权重值
- private static int totalWeight = 0;
再进行算法的实现:
- private static String getPrincess() {
- // 初始化妃子及对应的权重实体
- if (weightMap.isEmpty()) {
- //将配置初始化到map中去
- for (String princess : PrincessConfig.PRINCESS_MAP.keySet()) {
- // 算法的第一点:初始dynamicWeight为0
- weightMap.put(princess, new PrincessWeight(princess, PrincessConfig.PRINCESS_MAP.get(princess), 0));
- totalWeight += PrincessConfig.PRINCESS_MAP.get(princess);
- }
- }
- // 算法的第二点:设置currentWeight=设置weight+currentWeight
- for (PrincessWeight weight : weightMap.values()) {
- weight.setDynamicWeight(weight.getWeight() + weight.getDynamicWeight());
- }
- // 算法的第三点:寻找最大的currentWeight
- PrincessWeight maxPrincessWeight = null;
- for (PrincessWeight weight : weightMap.values()) {
- if (maxPrincessWeight == null || weight.getDynamicWeight() > maxPrincessWeight.getDynamicWeight()) {
- maxPrincessWeight = weight;
- }
- }
- // 算法的第四点:最大的dynamicWeight = dynamicWeight-totalWeight
- maxPrincessWeight.setDynamicWeight(maxPrincessWeight.getDynamicWeight() - totalWeight);
- return maxPrincessWeight.getPrincess();
- }
最终输出如下:
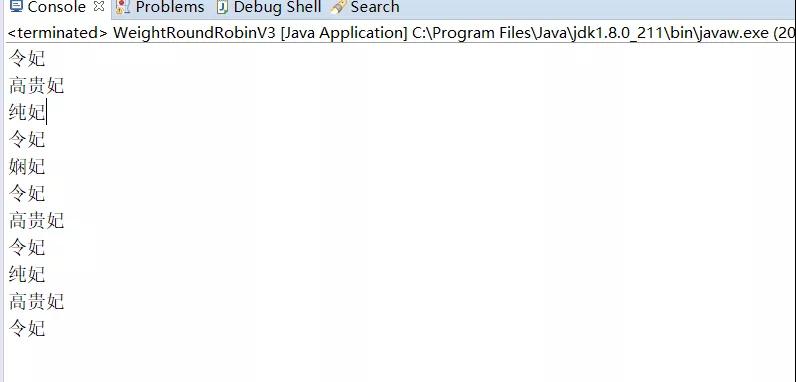
这样经过 11 次轮询,令妃同样出现了 5 次,但是明显不会再像之前算法那样连续出现了,会均衡得多!!!如果还有不清楚的,可以去文末的 Github 地址上下载代码自己调试及理解!
随机算法
平滑加权轮询算法能很好的进行负载了!但是皇阿玛又说了,按照轮询算法,我自己都能够推出来每晚侍寝的妃子,不刺激不刺激。
皇帝嘛,总喜欢来些新鲜的刺激的我们也可以理解!还好我们有随机算法可以解决,每晚都是随机选一个,让皇帝无法提前推测,给皇帝足够的刺激感!
我们依然先定义一个妃子集合如下:
- /**
- * *所有妃子集合
- */
- public static final List<String> PRINCESS_LIST = Arrays.asList("令妃", "娴妃", "高贵妃", "纯妃");
然后利用随机函数去选择一个目标:
- public static void main(String[] args) {
- for (int i = 0; i < 10; i++) {
- System.out.println(getPrincess());
- }
- }
- /**
- * *随机获取侍寝妃子
- * @return
- */
- private static String getPrincess() {
- SecureRandom rd = new SecureRandom();
- int index = rd.nextInt(PrincessConfig.PRINCESS_LIST.size());
- return PrincessConfig.PRINCESS_LIST.get(index);
- }
因为输出是随机的,所以这里就不贴出来了。如果明白了轮询算法,随机算法理解起来也就简单了,只是在轮询中用一个全局的 index 去保存每次循环的位置,而在随机中是每次去随机出来一个值。
加权随机算法
加权随机实现一
加权随机实现一与上面的加权轮询实现一的思路几乎一毛一样,这里就直接上代码了:
- public static void main(String[] args) {
- for (int i = 0; i < 10; i++) {
- System.out.println(getPrincess());
- }
- }
- private static String getPrincess() {
- List<String> princessList = new ArrayList<String>();
- for (String princess : PrincessConfig.PRINCESS_MAP.keySet()) {
- int weight = PrincessConfig.PRINCESS_MAP.get(princess);
- for (int i = 0; i < weight; i++) {
- princessList.add(princess);
- }
- }
- Random rd = new Random();
- int index = rd.nextInt(princessList.size());
- return princessList.get(index);
- }
加权随机实现二
加权随机实现二与上面的加权轮询实现二的思路几乎一模一样,这里也就直接上代码了:
- public static void main(String[] args) {
- for (int i = 0; i < 10; i++) {
- System.out.println(getPrincess2());
- }
- }
- private static String getPrincess2() {
- List<String> princessList = new ArrayList<String>();
- int totalWeight = 0;
- for (String princess : PrincessConfig.PRINCESS_MAP.keySet()) {
- int weight = PrincessConfig.PRINCESS_MAP.get(princess);
- totalWeight += weight;
- for (int i = 0; i < weight; i++) {
- princessList.add(princess);
- }
- }
- Random rd = new Random();
- int index = rd.nextInt(totalWeight);
- String result = null;
- for (String princess : PrincessConfig.PRINCESS_MAP.keySet()) {
- int weight = PrincessConfig.PRINCESS_MAP.get(princess);
- // 落在当前区间 直接返回
- if (index < weight) {
- result = princess;
- break;
- }
- // 没有落在当前区间 继续循环
- index = index - weight;
- }
- return result;
- }
源地址 hash 算法
我们的工作中开发系统很常见的一个需求就是需要登录后才能访问,这就会涉及到 session!
如果我们没有做 session 共享,那登录后的 session 信息只会存在我们调用登录接口的那台服务器上!
按照前面的轮询算法或者随机算法,我们同一客户端的多次请求就会落在不同的服务器上,这样就会导致部分接口没权限访问!
因此我们需要同一个客户端多次的请求落在同一台服务器上,这里常见的一种做法是对源地址进行 hash!
到这里我们也得让我们的皇阿玛歇会儿了,回到我们正常的业务场景中。假如我们有服务器配置如下:
- /**
- * *所有服务器集合
- */
- public static final List<String> SERVER_IP_LIST = Arrays.asList(
- "192.168.1.10",
- "192.168.2.20",
- "192.168.3.30",
- "192.168.4.40");
客户端访问的 ip 我也模拟了一个集合:
- /**
- * *客户端ip
- */
- public static final List<String> CLIENT_IP_LIST = Arrays.asList(
- "113.88.97.173",
- "106.11.154.33",
- "207.46.13.149",
- "42.156.137.120",
- "203.208.60.0",
- "119.39.47.182",
- "171.34.179.4",
- "111.175.58.52",
- "124.235.138.199",
- "175.184.166.184");
源地址 hash 算法的思路就是对客户端的 ip 进行 hash,然后用 hash 值与服务器的数量进行取模,得到需要访问的服务器的 ip。只要客户端 ip 不变,那 hash 后的值就是固定的!
实现如下:
- public static void main(String[] args) {
- for (String clientIp : CLIENT_IP_LIST) {
- int index = Math.abs(getHash(clientIp)) % PrincessConfig.SERVER_IP_LIST.size();
- String serverIp = PrincessConfig.SERVER_IP_LIST.get(index);
- System.out.println(clientIp + "请求的服务器ip为" + serverIp);
- }
- }
最终输出如下:

这样不管执行多少次,相同的客户端 ip 请求得到的服务器地址都是一样的!
这种实现很简单,但也很脆弱!因为我们服务器的数量是可能变化的,今天下线一台机器明天增加一台机器是很常见的!
服务器数量一旦变化,那源地址 hash 之后取模的值可能就变化了,获取到的服务器的 ip 自然就也会发生变化!
比如我们服务器去掉一台 192.168.4.10 的机器再看下输出结果:

对比输出结果我们就能看到,影响几乎是全局的!那我们能不能有一种方案就算是服务器数量变化,也能减少受影响的客户端呢?这就需要用到下面的一致性 hash 算法!
一致性 hash 算法
加权轮询算法实现二中我们讲到过把权重值转化为横坐标展示,我们这里是不是也可以用同样的思路呢?
客户端 ip 进行 hash 后不就是一个 int32 的数字嘛,那我们就可以把一个 int32 的数字分为几个段,让每个服务器负责一个段的请求!
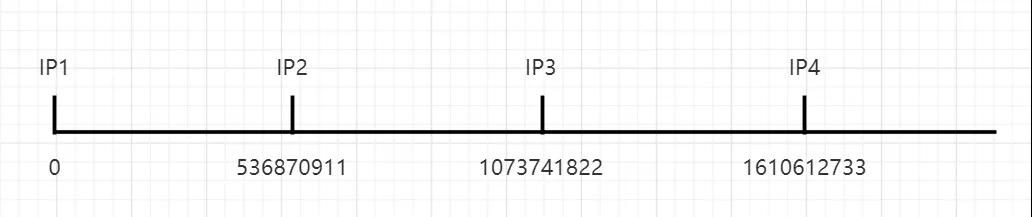
下面为了直观我们把服务器 192.168.2.10、192.168.2.20、192.168.2.30、192.168.2.40 分别用 IP1、IP2、IP3、IP4 表示,如上图:
- 如果客户端 ip 进行 hash 后的值在 0~536870911 之间,那就交给 IP2 服务器处理。
- 如果客户端 ip 进行 hash 后的值在 536870911~1073741822 之间,那就交给 IP3 服务器处理。
- 如果客户端 ip 进行 hash 后的值在 1073741822~1610612733 之间,那就交给 IP4 服务器处理。
- 如果客户端 ip 进行 hash 后的值大于 1610612733 之间,那就交给 IP1 服务器处理。
但是专业一点的表示都会把这个横坐标掰弯,形成一个环,就叫所谓的 hash 环,如下图:
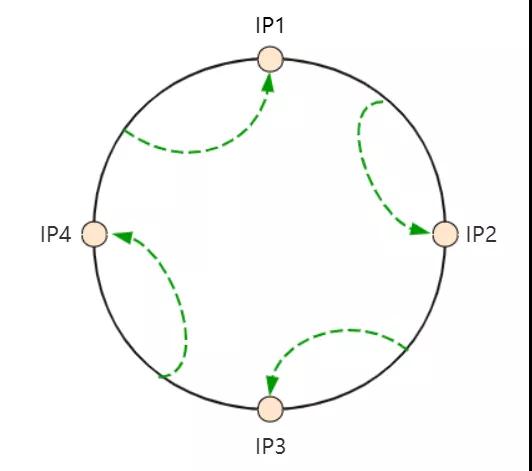
这样看就更直观了!如果有天 IP4 这台服务器宕机,那原来需要到 IP4 的请求就会全部转移到 IP1 服务器进行处理。
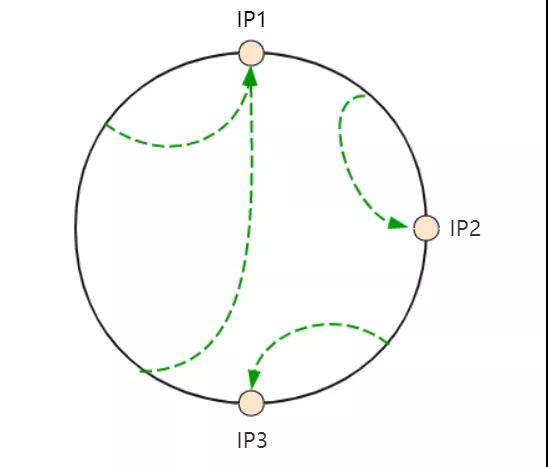
这样对部分客户端的请求依然会有影响,但至少影响也只是局部的,如下图:
这样就可以了吗?我们思考两个问题:
- 每个服务器在 hash 环上的位置是我们人为的均匀的分配的,这样经常需要扩容缩容的时候会不会比较难以维护呢?
- IP4 宕机,原本会到 IP4 的请求全部转移到 IP1,那会不会导致 IP1 的流量不均衡?能不能有一个更均衡一点的方案让原本到 IP4 的流量均衡的转移到 IP1、IP2、IP3 呢?
解决问题 1 的方案就是不再人为分配结点所在的位置,而是根据服务器的 ip 计算出 hash 值,再看 hash 值落在环上的哪个位置!
这样存在的一个问题是每个集群的服务器 ip 都会不同,因此计算后落在环上的位置可能就是不可控的。
如上面四台服务器计算后所在的位置可能会如下图所示:
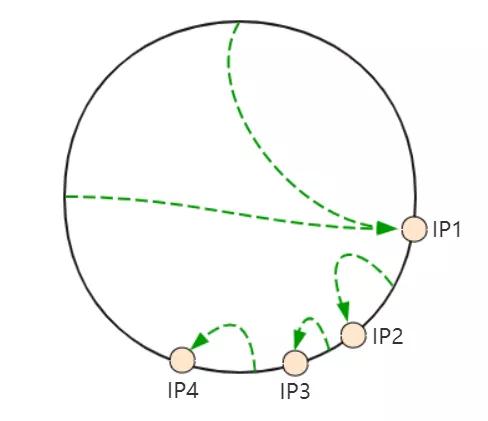
很明显,这种情况是极为不均匀的,会造成数据的倾斜!上面问题 2 的问题其实也是宕机导致的数据倾斜!
环的左上部分那么空,我们是不是可以把现在的 4 台服务器再根据其他的规则在左上方生成一些结点呢?这样是不是请求就会稍微均匀一点呢?
这就是所谓的虚拟结点!虚拟结点就是同一个服务器 ip 会根据某个规则生成多个 hashcode,这样在环上就存在多个结点了。
如下图所示:
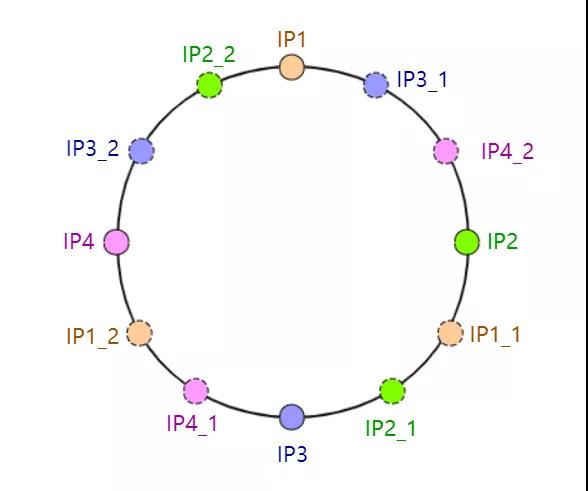
这里只是模拟了每台服务器有两个虚拟结点,实际在开发中会更多!这样就算 IP4 机器挂掉,请求也不会全部压到某一台服务器上去!
讲了这么多,但实现起来也不难,下面就该上代码了(服务器配置及请求的客户端 ip 与源地址 hash 算法部分的一致,这里就不贴对应的代码了,直接上算法逻辑):
- //虚拟结点数量100
- private static final Integer VIRTUAL_NODES = 100;
- public static void main(String[] args) {
- // 遍历服务器ip,生成对应的虚拟结点
- TreeMap<Integer, String> nodeMap = new TreeMap<Integer, String>();
- for (String serverIp : PrincessConfig.SERVER_IP_LIST) {
- for (int i = 0; i < VIRTUAL_NODES; i++) {
- nodeMap.put(getHash(serverIp + "VN" + i), serverIp);
- }
- }
- for (String clientIp : CLIENT_IP_LIST) {
- //这里利用的TreeMap的特性,不清楚的可以去自己去了解一下tailMap方法的作用
- SortedMap<Integer, String> subMap = nodeMap.tailMap(getHash(clientIp));
- Integer firstKey = null;
- try {
- firstKey = subMap.firstKey();
- } catch (Exception e) {
- }
- if (firstKey == null) {
- firstKey = nodeMap.firstKey();
- }
- System.out.println("请求的服务器ip为" + nodeMap.get(firstKey));
- }
- }
到此,几种常用的负载均衡算法及代码实现都已介绍完毕!还有不清楚可以去同性交友网下载示例代码自己调试:
- https://github.com/sujing910206/load-balance
作者:苏静
简介:有过多年大型互联网项目的开发经验,对高并发、分布式、以及微服务技术有深入的研究及相关实践经验。经历过自学,热衷于技术研究与分享!格言:始终保持虚心学习的态度!

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】