












王华,2014年加入阿里,一直做大数据运维相关的事情,也在做运维平台研发的事情。第一年做离线的运维,后来从2015年开始做流计算的运维,之前负责阿里云的流计算。
2017年开始负责 Flink 的运维,以及Flink运维管控建设。
一、阿里 Flink 集群运维挑战
首先说一下流计算,批计算就是数据集是有限的,每次的计算都可以拿到一样的结果,在批计算之上,如有很多个批,这个数据永久不断过来的时候就变成了流。
流计算是批计算以上的概念,很多用流计算的,比如说每天把所有的前端日志导到流上算一天,但是有了流计算之后,一条路过来就可以实时算出网站的UV。

说一下阿里的流计算引擎,2015年在 Galaxy 自研的流计算,2014年的时候阿里就有了流计算,那个时候还有JStorm和Flink,分别分布在搜索和中间件其他的部门。
之后经常在内网上PK,这几套引擎谁最牛逼。2017年左右 Flink 以低延时、高吞吐、一致性,从几个流计算引擎里面脱颖而出,后来整个集团做了技术统一,其他引擎全部抛弃,用Flink来做,Flink是阿里统一的流计算引擎。有了这样的基础之后,业务不断发展,所有的流计算引擎往 Flink 上迁移。
另外一个方面,我们对于数据的处理要求越来越高,现在尽可能往实时化,现在越来越多的Flink本身已经有很多批计算的逻辑和机器学习,综合这三点,导致阿里的 Flink 集群发展非常大。
据我了解,像谷歌、Facebook 没有用。只要用 Flink,阿里的 Flink 集群是全世界最大的。
现在我们的集群规模有几万个计算节点,大部分还是传统的物理机,还有大部分是 ECS和容器;有几百个集群,Flink 一部分用户是阿里内部的,集群最大的规模可能是五六千台,但是对外阿里云上售卖的,一个用户可以开通一个集群。
所以有上百个集群,一个集群可以有成百上千台机器,整个系统非常复杂,因为 Flink是一个计算的,不负责数据的源和目标存储,所以要从上游读数据,然后写到下游的数据库或者其他系统里面去,大概几十个上下游,而且整个 Flink 的底座也很多。
最早有基于 Hadoop 的底座和阿里飞天系的底座,还有现在基于云原生 Kubernetes 的底座。另外,出口非常多,基本上分布在全世界各地都是可以看到 Flink 的应用。
现在仅阿里内部的 Flink,每秒处理几十亿条数据,这个数据量非常庞大,一条数据1K,你想想这个数据有多大。规模这么大,运维上碰到了很多问题,挑战分为下面几部分:

第一部分是故障,特别实时计算系统,都在 Flink 上运行,所以我们对故障的要求是比较苛刻的;第二部分是大促稳定性怎么保障,大量的日常运维操作怎么保持一致性;
再就是成本,包括硬件成本怎样管理,用户资源怎样合理分配和合理均衡,怎么样降低运维人力成本。
我们不仅仅做 Flink运维,这么大的工作量,其实只有几个人负责整个运维,而且业务规模基本上每年都在翻番,它是一头奔跑着的大象。

首先运维靠人堆是绝对不可能的,这也是大数据运维和其他的运维不一样的点,靠人堆绝对不可能赢,我们要以技术为基础,所有的运维的出发点,要以技术为基础,我们做了一个 Flink 运维管控,最上面是Flink运维管控上承载着很多 Flink 的技术解决方案,我把两个“技术”都标红,我们在任何时候都不要忘记我们要用技术去解决这些问题。
二、阿里 Flink 运维管控
2015年不叫Flink运维管控,叫做流计算运维平台,17年的时候把这个东西做的更大一点。左边这个图,我们运维的是集群,集群就是一堆 IDC 资源的整合:网络、机器、内核。集群之上部署了软件,分布系统的软件和 Flink 软件,软件上跑的业务。
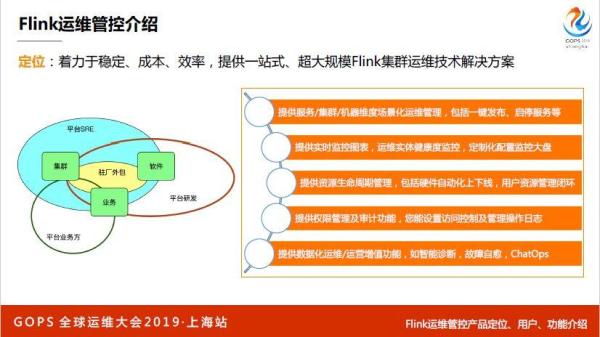
运维主要是面向集群业务和软件的。用户分为几块,一开始的用户是我们自己平台的SRE,运维和运维研发(Flink的开发)、平台的业务方,还有很多驻场外包也在用,整个权限的设计围绕着四大类用户。它提供了很多功能,整个 Flink 是机器-集群-服务-业务的方式来运作的。所以,带来了各种维度的产品化运维,比如从一个管控上面一键发布,停止服务,还提供实时秒级监控报表,里面有一套监控系统。
整个 Flink 管控上做了资源生命周期管理,不仅仅是硬件的,还有一些数据化运维和越位增值公司,现在的智能诊断,还有故障自愈。
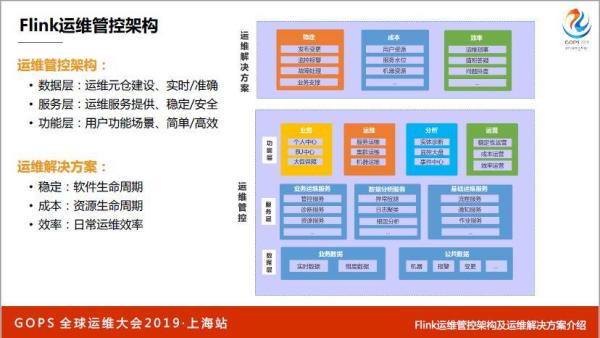
讲一下整体架构,最下面就是数据层,就在做一件事情,做Flink实时运维元仓的建设,一部分是业务数据,Flink本身的数据,一部分是实时数据,一部分是围表数据,还有一些公共数据,这层主要解决的是保证实时和准确。
数据层之上就是服务层,基础运维服务,还有一块是数据分析服务,大家经常听到的地产检测,日志聚类,还有最左边的业务服务、诊断服务、资源服务。
最上面是功能层,也很清晰,就是先业务,用户有自己的业务中心,围绕着稳定、成本、效率三大块做的,首先要说稳定性,我们怎么做,我们围绕着软件的发布,整个生命周期来讲,每一环是怎样解决的,第二块就是成本,资源的生命周期是怎样解决的,再就是日常运维效率怎么解决的。

这是一个Flink运维管控功能的布局,其实这里功能很多,光菜单布局就有很多版,后来我们找到了一个清晰的思路,就是业务有用户、作业、监控等等。
接下来是运维,运维就是稳定,面向运维的实体有集群、机器、业务、服务,还有就是运营,KPI的衡量;分析就是提升效率的,面向用户的业务有实时所有的作业,队列、预算等等。这是运维,面向管控的,有几个运维,每个点进去可以管理一个集群,也可以管理几百个集群。
这是诊断分析,下面会讲,我们的目标就是说一个站点要能做到所有的集群的运维,这个其实是很有挑战的,因为中间涉及到很多部署架构的异构,还有网络域,阿里的网络域比较复杂,有很大挑战在后面。
三、Flink 运维解决方案
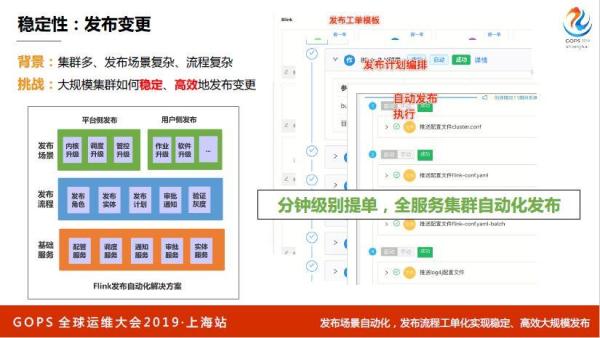
先说发布变更,我前几年 GOPS 大家都在谈自动化发布变更,这两天听下来,没有人聊发动变更了,说明已经做的很牛逼了,你发现阿里前两位同学都讲的发布变更,其实发布变更在阿里还是挺难的,为什么?
首先阿里的场景很复杂,那个同学提了,我们几万台机器的内核,怎么从3.x升到4.x,天基可以把机器关机升内核然后启动,但是在升级之前要把业务下掉,业务上面布了十个软件,哪个软件提供了一个接口,告诉他十个软件已经全下完了,这还不够。
几万台机器,一天按照一台机器,半个小时升一下内核,升到猴年马月,得升半年,这时又出现了业务可能要一批一批去升,这个更复杂了,如果说纯计算节点,没状态,很简单。你不能说三台机器同时分布在不同机架上,数据就丢了,这是大数据分布系统的一个复杂点。
另外一个就是流程很复杂,复杂在哪?从一个软件包发出来,有很多模块,然后到测试环境,到预发布再生产环境,这个流程有层层审批机制,可能会有熔断、回滚、验证,这个流程非常复杂。
最下面是发布一个技术服务,下面也会调用一些天基等等其他能力,范围是发布流程,最后是发布场景,用户和平台侧的发布,我们把很多场景工单化,预先定义好所有的发布流程,只要提一个单子,所有发布的计划都编排好了。
这周发这两个集群,所有的发布计划都已经编排好了,然后发布之后进行执行,能做到分钟级别的提单,但是最终也是面向中台的,可能会利用天基的能力,做到全服务集群的自动化,保持一致。
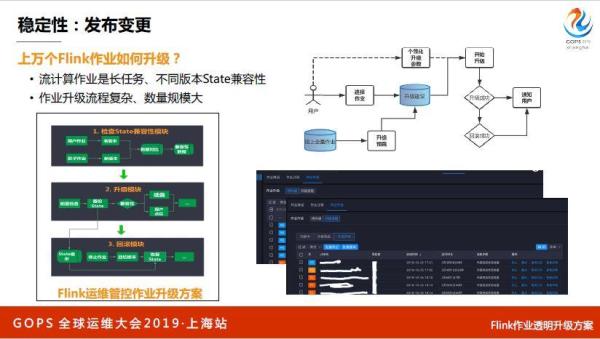
刚才说了软件发布,这里讲一个Flink的,软件包发到集群上面后,怎么样让用户用起来,用户的作业是长任务,是一直跑在线上的,除非要停下来,用新的版本把资源全部传上去,才能升级到新的,这是流计算本身的原理。
数据是一个时间轴,在10点钟停了,怎么保证在11点起来?怎么样保证自对回追回来,有一个state,把所有的计算中心结果都写在本地存储上面,不同版本之间有不同的兼容情况,而且整个升级非常复杂,几万个作业升级也是非常难的。在业务的发布上,天基解决不了我们的问题。我们有自己的一套方案,大家对这块有很多技术细节,大家对Flink不了解,我就暂时不说了。
最终能够做到用户根据自己的业务属性做批量自动化升级,我们会把升级的闭环全部打通,升级失败了自动回滚,升级成功自动通知等等,这里面有比较多的技术细节。
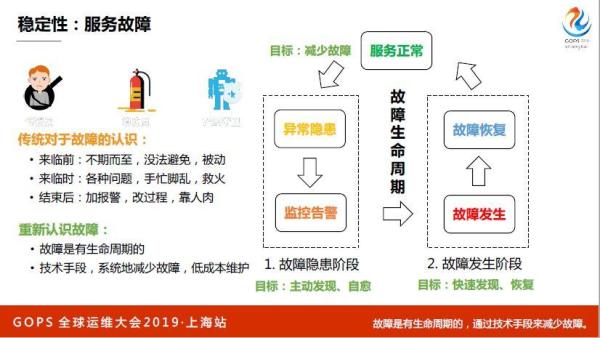
软件上线以后,用户用起来了,接下来怎么样保证用户平稳运行,其实就是故障。我觉得GOPS大家把故障和异常,通过异常,平时有一个报警也算异常,但是我们最关心的如果按报警来做,报警太多了,我们对关心的是故障,传统的故障。
大家都知道,感觉故障这个东西不期而至,没有办法避免这个故障什么时候来,每次来你好像都很被动,和小孩一样,什么时候哭不知道,来临的时候各种问题,老板在问你,出什么问题了,业务各种反馈,你就手忙脚乱的。结束之后很累,可能想报警没覆盖到,加一些报警吧,或者说流程有问题,改善一下流程。故障就是这样,很难。
但是其实我们去年做了一个事情,其实故障本身也是有一个完整的生命周期的,首先就是服务正常,目标就是来减少故障,每个系统都有自己的故障定义,开始有一些异常隐患,比如说集群有一个五千台机器,有几个作业很恶劣,现场慢慢在泄露,很多台机器已经慢慢在涨了,但是没有问题。
等到涨到一定的值,比如一台机器的内核线到十万,可能开始load很高很高,大量的时候CPU都消耗在内核线程切换上。如果再不处理,因为分布式系统,其他的作业,运行的所有的作业会有心跳吗?心跳超时,就有故障了。
故障发生开始查,查完之后恢复故障,又恢复到正常,又开始不断循环,这是一个完整的生命周期,其实把这些故障拆借一下,分成两部分,一部分是故障的隐患,我们没有故障,但是系统已经有异常了,这个时候不用背什么责任,这个时候我们要做到主动发现和治愈。
第二点发生了怎么,发生没辙,只能快速发现,迅速恢复。故障其实是有生命周期的,正确理解生命周期之后,可以通过一些技术手段系统解决故障,并且能够做到低成本维持住。
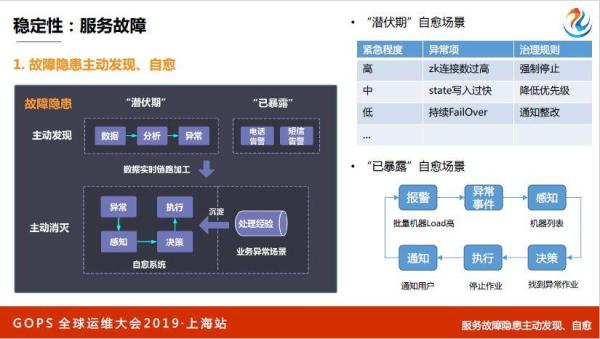
故障隐患我们怎么发现和治愈,分两部分,有潜伏期和暴露的。潜伏期就是不知道,暴露就是电话报警,会分析各种数据,把数据拿过来之后,第二部分就是分析,可以用监控,传统的阈值监控也可以,对于有一个异常事件,这是一个潜伏期的事件,主动发现的异常事件。
我们通过一条实时链路,因为异常事件如果进入一个系统里面,处理慢的话就会导致故障,进入下面的治愈系统里面,大家自己开发的,感知决策执行,我感知这个事件,然后做决策,最后执行,运维系统不断把我们的经验沉淀。
举个例子,潜伏期有哪些自愈场景,有些作业磁盘写的很猛,还有一些作业挂了,一个作业挂了没什么问题,已暴露自愈系统,报警,异常事件,进行感知,我们找到一百台机器,然后进行作业,解决问题之后通知用户已经恢复。
我们动作这套系统和理论,这是真实的场景,之前电话告警每周有28个到29个左右,现在我们做到了个位数,每周只有两三个电话。
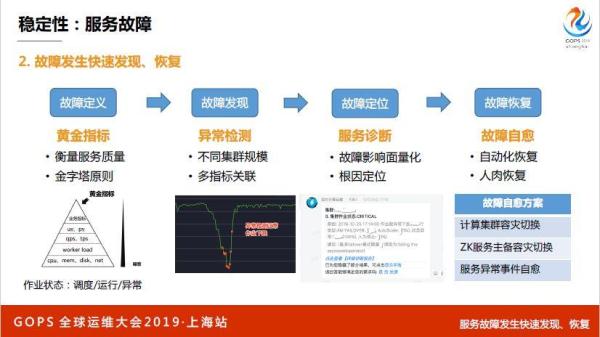
故障隐患阶段,我们可能尽力了,但是真的出故障了,到了第二个阶段。真的故障了,故障怎么发现和恢复,GOPS很多场都说了,有一个异常,异常检测,根因分析,然后反馈。
首先我们有一个故障定义,因为系统很大,需要找出一到两个指标,能说清楚,这个指标有问题,我的服务就有问题。像淘宝天猫,下单是一个KPI,支付是一个KPI,跳转又是一个KPI,前端访问不了没有影响,越往下的指标没有意义的。
整个集群的水位突然掉下来,有可能是软件升级,也有可能是一部分用户停了一部分作业,自己人为操作的,不算故障。越往下的指标越没有意义,但是流量如果跌下来了,很有可能是故障,但是也不一定,但是起码谁位越往上指标肯定更有意义,噪音越来越小。
Flink拿每个运行状态,把这个作业状态做成很多条曲线,反映服务的情况,最终这个指标的黄金指标,要衡量一个服务好不好的最后一个黄金指标肯定很简单,不可能有很多很多条曲线,那肯定是不可能的,如果有那肯定就是黄金指标,提取没有对,基于这个黄金指标进行检测。
第二个是多指标关联,我们要关联异常曲线上去,一个是断崖式的,一个是突增的,接下来是故障定位,故障定位一定要说清楚,现在到底出什么问题了;我要把我的故障量化出来,我哪里出了问题,大概出了什么问题,我现在到底受了多少损失,我们一定要说清楚,哪个服务,哪个地方哪个集群有问题,大概多少个作业受影响了,这些东西一定要说清楚。
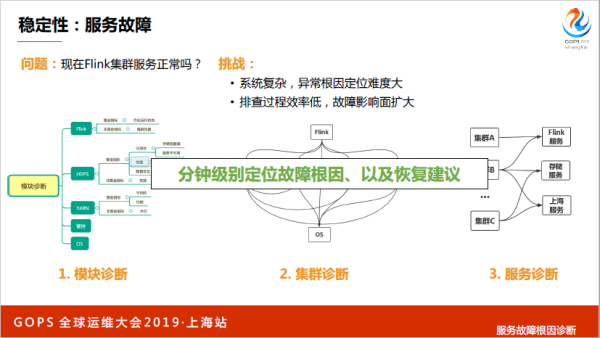
再就是根因定位,其实这块很难,我们没有用很多乱七八糟的所发,我们就是根据自己的经验把那些经验代码一个一个写下来,我知道故障发生的根因,我就开始自愈,这也没有那么简单,有些简单的场景可以做自动化恢复的,比如说哪有问题一把切,可以从第三个服务诊断,你们看到了这里可能不是很清晰,是一个出故障的时候我们钉钉有推送,有什么问题出来了。
现在Flink服务是不是正常的?这是一个比较难的问题,因为整个系统非常复杂,很庞大,不是一条链路,甚至不是一个链路下来的,可能会有异步的,也没有一个ID,不同的运维时期里面对象都是不一样的,而且故障排查率低的话还有可能会造成故障。
我们怎么诊断这个事情,一个系统,一个集群有很多模块存储调度,管控,每个模块也根据刚才的规则尝试提取一到两个黄金指标,衡量模块好不好,基于这个黄金指标做模块诊断,然后再说集群好不好,集群诊断做完之后,就可以做服务诊断,这是夸张一点,分钟界别发现故障,根因和恢复建议我们做不到,这个还不行。
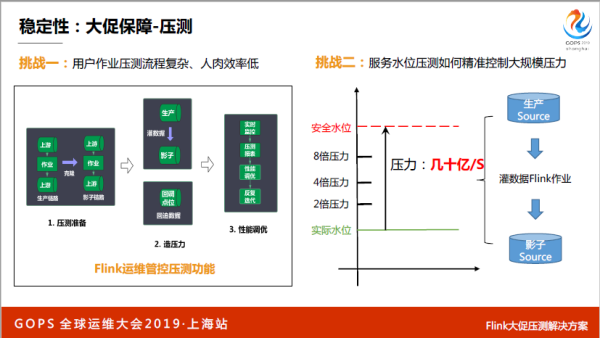
再来说和Flink有点关系的,大促的压测怎么做,用户有很多作业在线上跑,我们要做一件事情,把用户的作业,因为每个作业的计算逻辑代码都不一样,我们需要把用户计算逻辑考一份到备链路,看能不能达到要求。
如果能够达到的,相当于双十一可以解决问题,克隆一个影子作业,替换了上下游,就开始不断加压力,做各种实时监控性能报表,一个作业只要在平台上点一下,就可以自动完成这些事情。
再说一个大家直观感受的东西,刚才说了整个服务本身已经每秒在处理几十亿表数据了,按照正常双十一的量,肯定是平时的几倍,你要造出来的量也应该是几十亿的几倍不然逻辑说不过去,这是一个非常难的事情,给你一百个机器人也解决不了,更不用说小脚本,根本不可能。
这就是我们可能大数据运维同学的一个比较强的感觉,我们很擅长利用自己运维的大数据系统,来解决我们自己在大数据运维当中碰到的各种问题。
我们想了一个很巧妙的方案,我们用 Flink 自己的能力,这些 Flink 可以很巧妙解决两个问题,压测过程当中压力大的问题,充分利用 Flink 的分布式计算很牛逼的能力,解决了压力瓶颈。
压力不能一上来就把集群打挂了,一定得循序渐进。如何精准控制,我们通过不同的Flink作业数量,通过这种方式,很巧妙的解决了这个问题。这是Flink最重要的业务,GMV大屏成交额,每天可能看到PR公关上一分钟成交多少亿,十分钟成交多少亿,那个任务就是在Flink集群上的。
逻辑是从整个淘宝支付宝那边的交易数据库同步到数据通道,起了一个Flink作业,这个作业不断消费所有的交易日志,写到另外一个存储系统里面,前端来轮巡这个存储系统,这个数据量很大,可以做到一整天下来,Flink的作业延时在秒级。
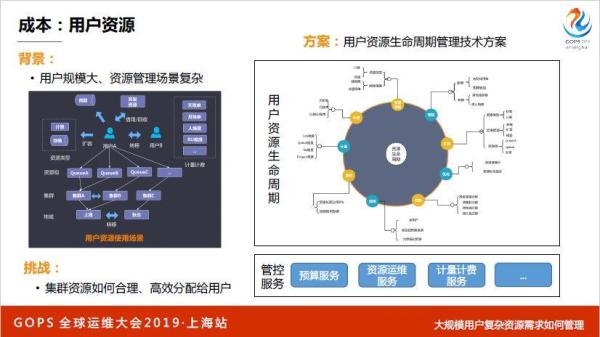
再来说一下用户资源,只有我们阿里人可以体会用户资源,说白了你有五万台机器,可能有五百万个CPU,怎么把资源合理分配给现场用户,有些用户说我的业务很重要。
这是一个很复杂的场景,我们怎么把集群资源如何合理的高效的分配给用户,我们希望做到最好的状态是用户不用关心资源,如果资源池无限大,哪都有资源,根本不用关心这个事情。
其实用户资源也有一个生命周期,从开始的提预算,再到线上资源扩容,再到上线之后有一些用户滥用,拿很多资源不用,我们怎么做优化,还有就是怎么做均衡,均衡之后怎么回收资源,怎么样计量计费,整个生命周期通过预算服务、资源服务,整个管控做起来。
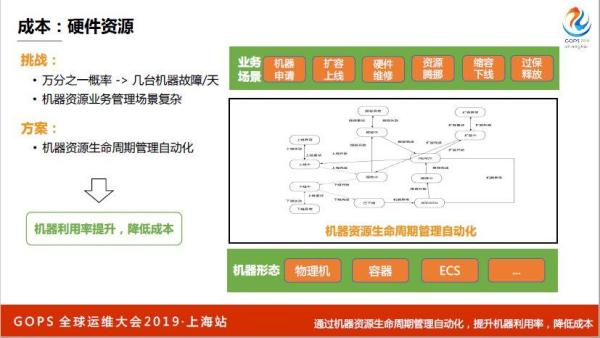
第二块硬件资源怎么管理,如果按照一天一万台机器只挂一台,我们每天都要挂几台机器,万分之一的宕机率,一天还要维护几台机器,一周就是几十台,怎么做自动化的维修,如果这个效率过程当中很低的话就会导致下面故障的机器越来越多,过一年几千台机器,怎么做高效的资源上下线。
机器上线、扩容、硬件维修、缩容、过保,机器的生命周期我们都管起来,这可能和天基讲的,我们会用天基很多能力,但是这里面有很多业务逻辑,我们从业务视角来看机器生命周期,我们希望做到自己的平台上选择一堆机器下线可以自动下线,从而降低成本。
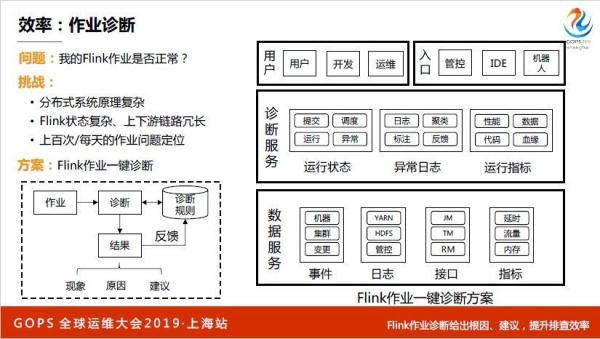
再说一下Flink作业是否正常,我们做了一整套作业诊断,比较复杂,整体思路下面有很多事件、日志、接口、指标,下面有一个诊断服务,主要做几件事情,运行状态,哪个状态到底什么阶段,日志和运行指标,下面有很多入口。
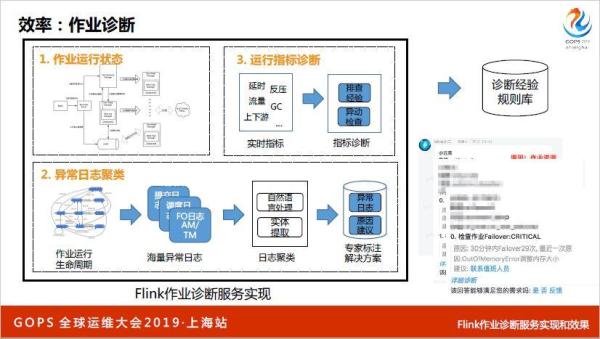
第一部分就是作业状态,只要搞清楚Flink的状态,每个状态的原因是什么,第二块就是日志聚类,我听了几场,把海量日志收集起来,把相同日志模式合起来,通过一些算法会写到一个库里面。
这个库里面这个日志是属于这个实体的,原因是什么,原因不知道,我们需要专家去标注,标注之后下一次有一个新的报错进来之后找到这个日志,原因是因为什么,就可以直接告诉他这个作业怎么处理,这是一个诊断思路,这是我们落地的结果。
基本上资源跑不起来,都可以告诉你,因为资源跑不起来,应该怎么做怎么做扩容去哪做扩容,一站式的,还有就是昨天晚上有一台机器下线了,还有就是可能告诉你哪个节点要调什么内存。
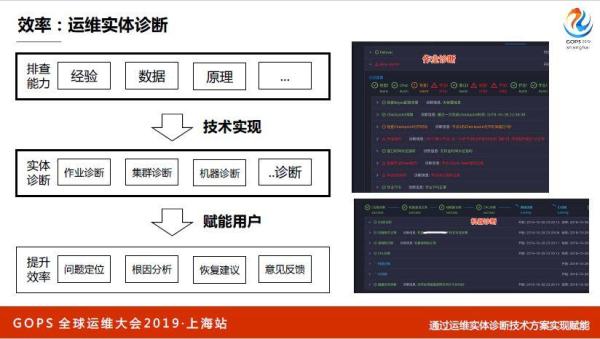
除了作业诊断,思路都是一样,就是把经验原理和数据通过一些技术实心来实现诊断,最终做到问题定位根因和恢复意见。我们不仅仅做到作业诊断,还做了机器诊断,一台机器输入进来告诉你机器好不好。
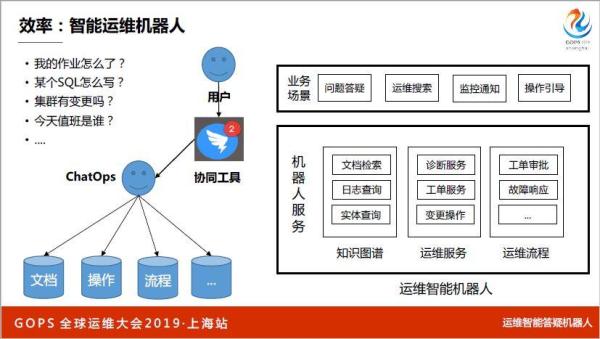
最后讲智能运维机器人,这个很解问题,我们答疑量特别大,用户会有各种各样的问题,以前都是靠人。我们通过钉钉,运维只需要把文档、操作、流程,把知识图谱构建起来,结合钉钉做整体协同,很简单让用户完成端到端的答疑。这里面有很多功能,就不一一细说了。
大数据运维难在哪,阿里的大数据形态和其他的很不一样,我们很早就实现了,像技术统一是很早的,Flink 流计算大家统一的引擎,离线计算可能是 MaxCompute,集群的管理用天基。近几年没有出现重复的,这一方面促进了整个阿里的底层大数据基础平台业务发展非常快,机器规模发展也很多,更多的复杂性导致,运维的挑战也越来越多。
以上为阿里大数据运维技术专家王华在 GOPS 2019 · 上海站的分享。




















