当初我学RabbitMQ的时候,第一时间就上GitHub找相应的教程,但是令我很失望的是没有找到,Spring,Mybatis之类的教程很多,而RabbitMQ的教程几乎找不到,后来想着索性自己总结一下吧,有不恰当的地方欢迎小伙伴指出。
这篇文章主要是对着我在GitHub上的源码解释的,因此本文并没有太多的源码。写了挺长时间的,为了防止迷路,欢迎大家star和fork
github地址:https://github.com/erlieStar/rabbitmq-examples
前言
我们先来看一下一条消息在RabbitMQ中的流转过程
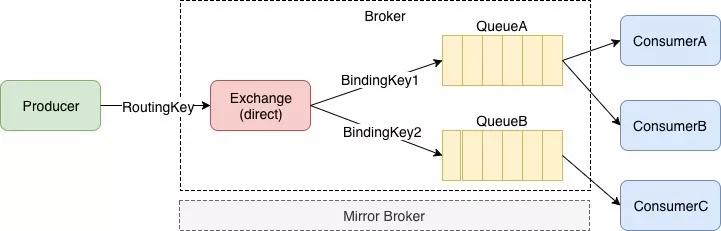
图示的主要流程如下
- 生产者发送消息的时候指定RoutingKey,然后消息被发送到Exchange
- Exchange根据一些列规则将消息路由到指定的队列中
- 消费者从队列中消费消息
整个流程主要就4个参与者message,exchange,queue,consumer,我们就来认识一下这4个参与者
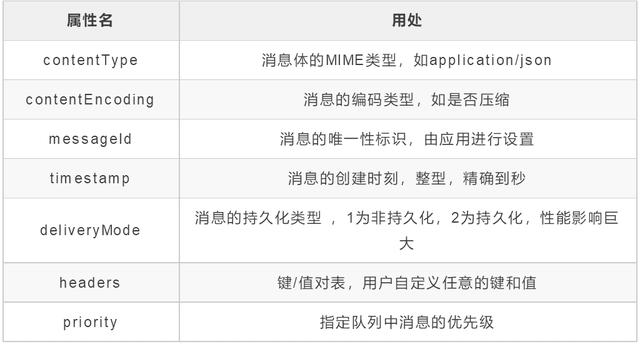
Message
消息可以设置一些列属性,每种属性的作用可以参考《深入RabbitMQ》一书
Exchange
接收消息,并根据路由键转发消息到所绑定的队列,常用的属性如下
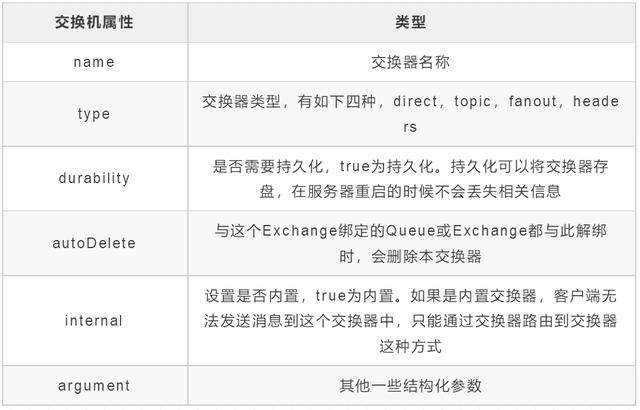
我们最常使用的就是type属性,下面就详细解释type属性
Fanout Exchange
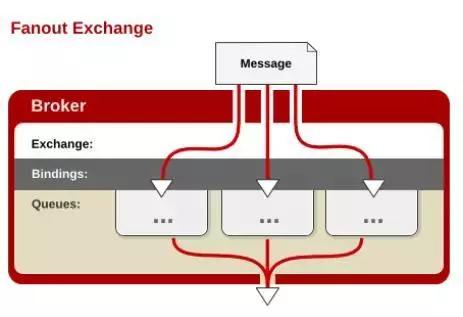
发送到该交换机的消息都会路由到与该交换机绑定的所有队列上,可以用来做广播
不处理路由键,只需要简单的将队列绑定到交换机上
Fanout交换机转发消息是最快的
Direct Exchage
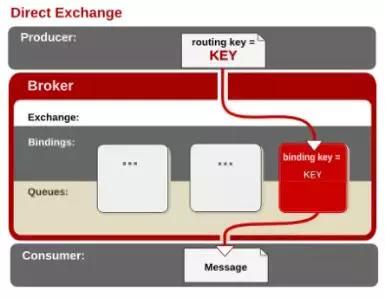
把消息路由到BindingKey和RoutingKey完全匹配的队列中
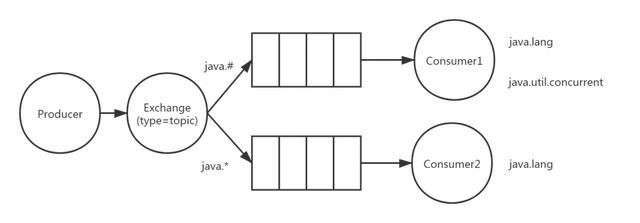
Topic Exchange
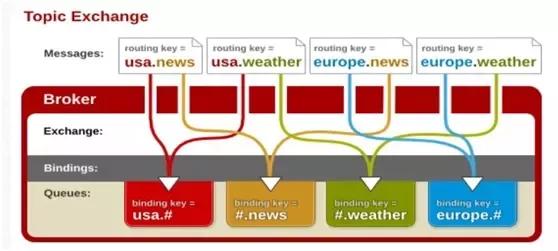
前面说到,direct类型的交换器路由规则是完全匹配RoutingKey和BindingKey。topic和direct类似,也是将消息发送到RoutingKey和BindingKey相匹配的队列中,只不过可以模糊匹配。
- RoutinKey为一个被“.”号分割的字符串(如com.rabbitmq.client)
- BindingKey和RoutingKey也是“.”号分割的字符串
- BindKey中可以存在两种特殊字符串“*”和“#”,用于做模糊匹配,其中“*”用于匹配不多不少一个词,“#”用于匹配多个单词(包含0个,1个)

假如现在有2个RoutingKey为java.lang和java.util.concurrent的消息,java.lang会被路由到Consumer1和Consumer2,java.util.concurrent会被路由到Consumer2。
Headers Exchange
headers类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送消息内容中的headers属性进行匹配。headers类型的交换器性能差,不实用,基本上不会使用。
Queue
队列的常见属性如下

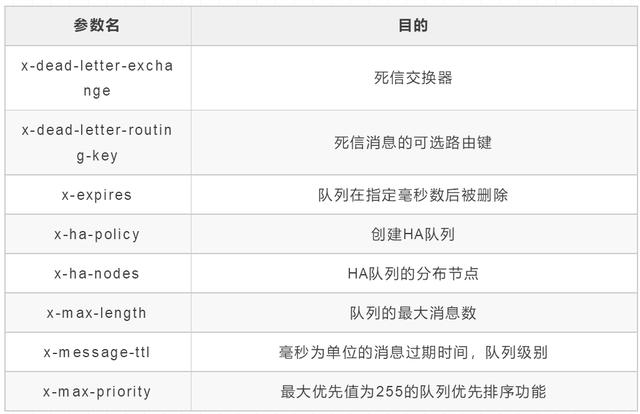
arguments中可以设置的队列的常见参数如下
rabbitmq-api(rabbitmq api的使用)
chapter_1: 快速开始,手写一个RabbitMQ的生产者和消费者
chapter_2: 演示了各种exchange的使用
来回顾一下上面说的各种exchange机器路由规则

chapter_3: 拉取消息
消息的获得方式有2种
- 拉取消息(get message)
- 推送消息(consume message)
那我们应该拉取消息还是推送消息?get是一个轮询模型,而consumer是一个推送模型。get模型会导致每条消息都会产生与RabbitMQ同步通信的开销,这一个请求由发送请求帧的客户端应用程序和发送应答的RabbitMQ组成。所以推送消息,避免拉取
chapter_4: 手动ack
消息的确认方式有2种
- 自动确认(autoAck=true)
- 手动确认(autoAck=false)
消费者在消费消息的时候,可以指定autoAck参数
String basicConsume(String queue, boolean autoAck, Consumer callback)
autoAck=false: RabbitMQ会等待消费者显示回复确认消息后才从内存(或者磁盘)中移出消息
autoAck=true: RabbitMQ会自动把发送出去的消息置为确认,然后从内存(或者磁盘)中删除,而不管消费者是否真正的消费了这些消息
手动确认的方法如下,有2个参数
basicAck(long deliveryTag, boolean multiple)
deliveryTag: 用来标识信道中投递的消息。RabbitMQ 推送消息给Consumer时,会附带一个deliveryTag,以便Consumer可以在消息确认时告诉RabbitMQ到底是哪条消息被确认了。
RabbitMQ保证在每个信道中,每条消息的deliveryTag从1开始递增
multiple=true: 消息id<=deliveryTag的消息,都会被确认
myltiple=false: 消息id=deliveryTag的消息,都会被确认
消息一直不确认会发生啥?
如果队列中的消息发送到消费者后,消费者不对消息进行确认,那么消息会一直留在队列中,直到确认才会删除。
如果发送到A消费者的消息一直不确认,只有等到A消费者与rabbitmq的连接中断,rabbitmq才会考虑将A消费者未确认的消息重新投递给另一个消费者
chapter_5: 拒绝消息的两种方式
确认消息只有一种方法
basicAck(long deliveryTag, boolean multiple)
而拒绝消息有两种方式
- basicNack(long deliveryTag, boolean multiple, boolean requeue)
- basicReject(long deliveryTag, boolean requeue)
basicNack和basicReject的区别只有一个,basicNack支持批量拒绝
deliveryTag和multiple参数前面已经说过。
requeue=true: 消息会被再次发送到队列中
requeue=false: 消息会被直接丢失
chapter_6: 失败通知
chapter_6到chapter_10主要简述了消息发布时的权衡
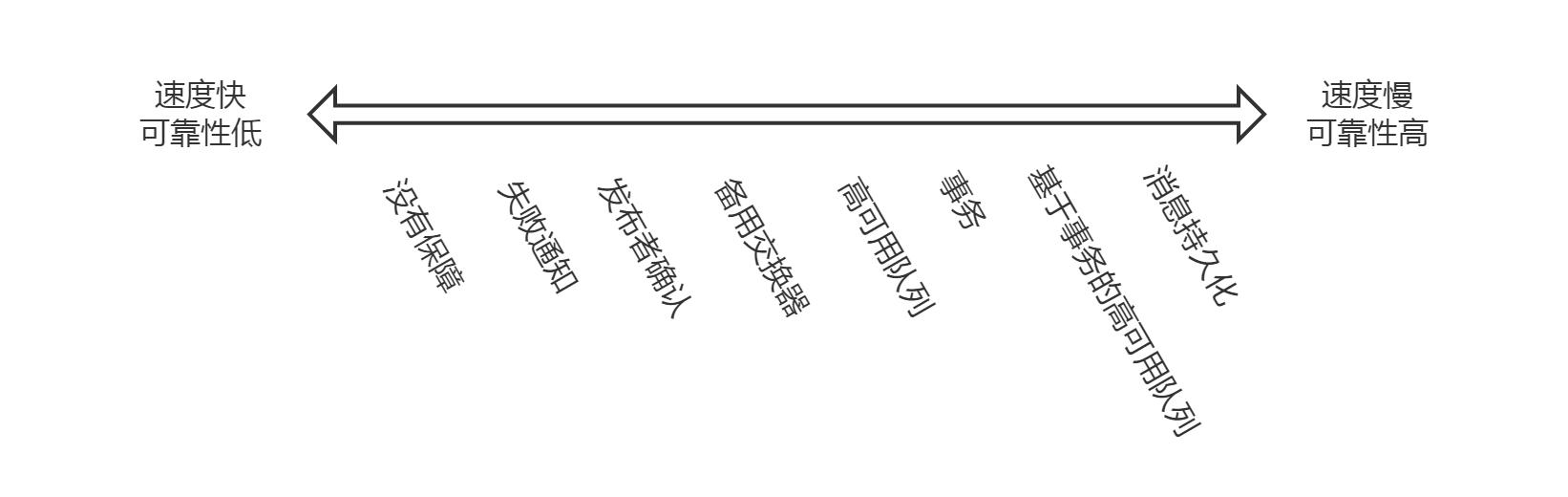
我们最常用的就是失败通知和发布者确认
当消息不能被路由到某个queue时,我们如何获取到不能正确路由的消息呢?
- 在发送消息时设置mandatory为true
- 生产者可以通过调用channel.addReturnListener来添加ReturnListener监听器获取没有被路由到队列中的消息
mandatory是channel.basicPublish()方法中的参数
mandatory=true: 交换器无法根据路由键找到一个符合条件的队列,那么RabbitMQ会调用Basic.Return命令将消息返回给生产者
mandatory=false: 出现上述情形,则消息直接被丢弃
chapter_7: 发布者确认
当消息被发送后,消息到底有没有到达exchange呢?默认情况下生产者是不知道消息有没有到达exchange
RabbitMQ针对这个问题,提供了两种解决方式
- 事务(后面会讲到)
- 发布者确认(publisher confirm)
而发布者确认有三种编程方式
- 普通confirm模式:每发送一条消息后,调用waitForConfirms()方法,等待服务器端confirm。实际上是一种串行confirm了。
- 批量confirm模式:每发送一批消息后,调用waitForConfirms()方法,等待服务器端confirm。
- 异步confirm模式:提供一个回调方法,服务端confirm了一条或者多条消息后Client端会回调这个方法。
异步confirm模式的性能最高,因此经常使用,我想把这个分享的细一下
- channel.addConfirmListener(newConfirmListener(){@OverridepublicvoidhandleAck(longdeliveryTag,booleanmultiple)throwsIOException{log.info("handleAck,deliveryTag:{},multiple:{}",deliveryTag,multiple);}@OverridepublicvoidhandleNack(longdeliveryTag,booleanmultiple)throwsIOException{log.info("handleNack,deliveryTag:{},multiple:{}",deliveryTag,multiple);}});
写过异步confirm代码的小伙伴应该对这段代码不陌生,可以看到这里也有deliveryTag和multiple。但是我要说的是这里的deliveryTag和multiple和消息的ack没有一点关系。
confirmListener中的ack: rabbitmq控制的,用来确认消息是否到达exchange
消息的ack: 上面说到可以自动确认,也可以手动确认,用来确认queue中的消息是否被consumer消费
chapter_8: 备用交换器
生产者在发送消息的时候如果不设置 mandatory 参数那么消息在未被路由到queue的情况下将会丢失,如果设置了 mandatory 参数,那么需要添加 ReturnListener 的编程逻辑,生产者的代码将变得复杂。如果既不想复杂化生产者的编程逻辑,又不想消息丢失,那么可以使用备用交换器,这样可以将未被路由到queue的消息存储在RabbitMQ 中,在需要的时候去处理这些消息
chapter_9: 事务
RabbitMQ中与事务机制相关的方法有3个

消息成功被发送到RabbitMQ的exchange上,事务才能提交成功,否则便可在捕获异常之后进行事务回滚,与此同时可以进行消息重发
因为事务会榨干RabbitMQ的性能,所以一般使用发布者确认代替事务
chapter_10: 消息持久化
消息做持久化,只需要将消息属性的delivery-mode设置为2即可
RabbitMQ给我们封装了这个属性,即MessageProperties.PERSISTENT_TEXT_PLAIN,
详细使用可以参考github的代码
当我们想做消息的持久化时,最好同时设置队列和消息的持久化,因为只设置队列的持久化,重启之后消息会丢失。只设置队列的持久化,重启后队列消失,继而消息也丢失
chapter_11: 死信队列
DLX,全称为Dead-Letter-Exchange,称之为死信交换器。当一个消息在队列中变成死信(dead message)之后,它能被重新发送到另一个交换器中,这个交换器就是DLX,绑定DLX的队列就称之为死信队列。
DLX也是一个正常的交换器,和一般的交换器没有区别,实际上就是设置某个队列的属性
消息变成死信一般是由于以下几种情况
- 消息被拒绝(Basic.Reject/Basic.Nack)且不重新投递(requeue=false)
- 消息过期
- 队列达到最大长度
死信交换器和备用交换器的区别
备用交换器: 1.消息无法路由时转到备用交换器 2.备用交换器是在声明主交换器的时候定义的
死信交换器: 1.消息已经到达队列,但是被消费者拒绝等的消息会转到死信交换器。2.死信交换器是在声明队列的时候定义的
chapter_12: 流量控制(服务质量保证)
qos即服务端限流,qos对于拉模式的消费方式无效
使用qos只要进行如下2个步骤即可
- autoAck设置为false(autoAck=true的时候不生效)
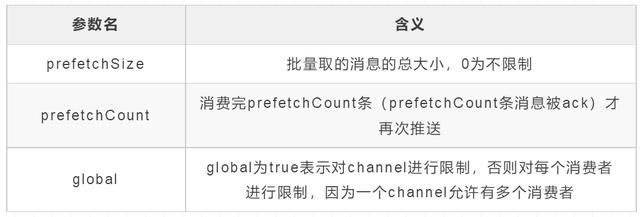
- 调用basicConsume方法前先调用basicQos方法,这个方法有3个参数
basicQos(int prefetchSize, int prefetchCount, boolean global)
为什么要使用qos?
- 提高服务稳定性。假设消费端有一段时间不可用,导致队列中有上万条未处理的消息,如果开启客户端,
巨量的消息推送过来,可能会导致消费端变卡,也有可能直接不可用,所以服务端限流很重要
- 提高吞吐量。当队列有多个消费者时,队列收到的消息以轮询的方式发送给消费者。但由于机器性能等的原因,每个消费者的消费能力不一样,
这就会导致一些消费者处理完了消费的消息,而另一些则还堆积了一些消息,会造成整体应用吞吐量的下降